
3. 범주형 데이터 시각화
seaborn을 import하고 data loading하는 code
import seaborn as snstitanic = sns.load_dataset('titanic') # 타이타닉 데이터 불러오기
이번 포스팅에서 살펴볼 시각화 그래프들
- 막대 그래프
- 포인트플롯
- 박스플롯
- 바이올린플롯
3.1 막대 그래프(barplot)
막대 그래프 barplot()
- 범주형 데이터 값에 따라 수치형 데이터 값이 어떻게 달라지는지 파악할 때 사용함.
- 범주형 데이터에 따른 수치형 데이터의 평균과 신뢰구간을 그려준다.
수치형 데이터의 평균 : 막대 높이,신뢰구간: 오차 막대 로 표현한다.- 원본 데이터를 복원 샘플링하여 얻은 표본을 활용햐 평균과 신뢰구간을 구함
- 즉,
barplot()은 원본 데이터 평균이 아니라 샘플링한 데이터 평균을 구하는 것!!!
기본적으로 x파라미터에 범주형 데이터를, y파라미터에 수치형 데이터를 전달한다.
data파라미터는 전체 데이터셋을 전달한다.
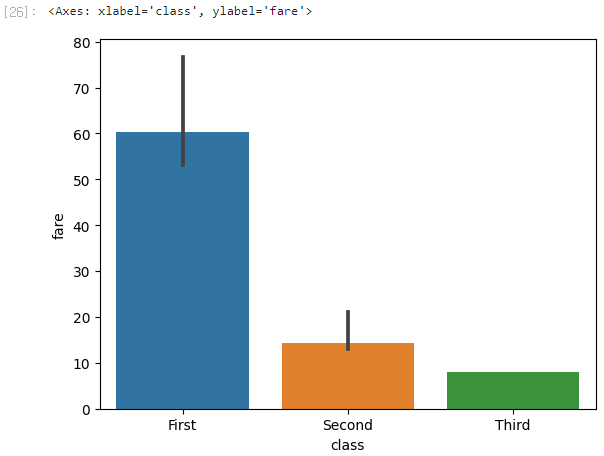
이제 barplot()을 활용하여 타이타닉 탑승자 등급별 운임을 barplot()으로 그려보겠다.
범주형 데이터인 class(등급) 피처를 x파라미터에, 수치형 데이터인 fare(운임) 피처를 y파라미터에 전달한다.
Code
sns.barplot(x='class', y='fare', data=titanic)
Result
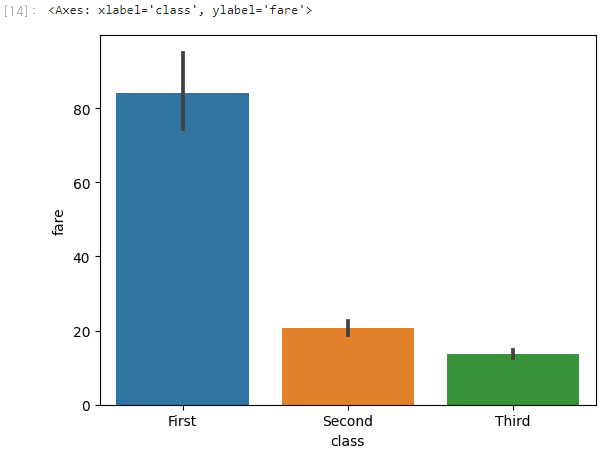
막대 높이는 등급별 평균 운임을 뜻한다.
막대 상단의 검은색 세로줄이 오차 막대(신뢰구간)이다.
막대 그래프를 통해 알 수 있는 insigt
등급이 높을수록 평균 운임이 비싸고 신뢰구간이 넓어진다.
3.2 포인트플롯(pointplot)
포인트플롯 pointplot()
- 막대 그래프와 모양만 다를 뿐, 동일한 정보를 제공한다.
범주형 데이터에 따른수치형 데이터의평균과신뢰구간을 나타낸다.- But, 그래프를 점과 선으로 나타낸다.
타이타닉 탑승자 등급별 운임을 pointplot()으로 그려보자.
Code
sns.pointplot(x='class', y='fare', data=titanic)
Result
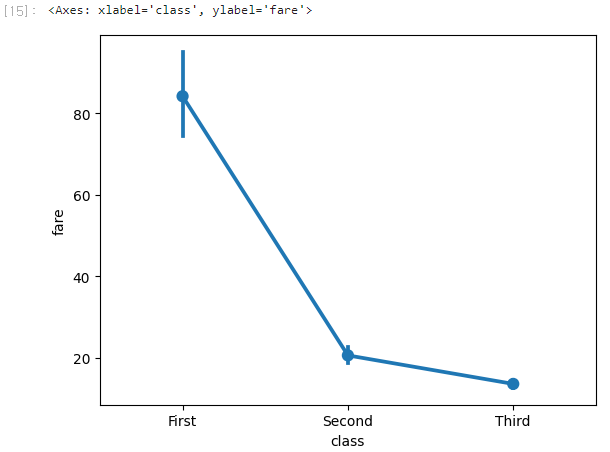
그래프를 직접 그려보니, pointplot과 barplot은 동일한 정보를 제공한다.
이 두가지의 그래프를 언제 어떻게 사용하는게 좋을까?
한 화면에 여러 그래프를 그릴 때 사용하는게 좋다.
포인트풀롯은 점과 선으로 표현하기 때문에 여러 그래프를 그려도 서로 잘 보이고, 비교하기도 쉽다.
계절에 따른 시간대별 자전거 대여 수량을 나타내는 그래프를 보자,
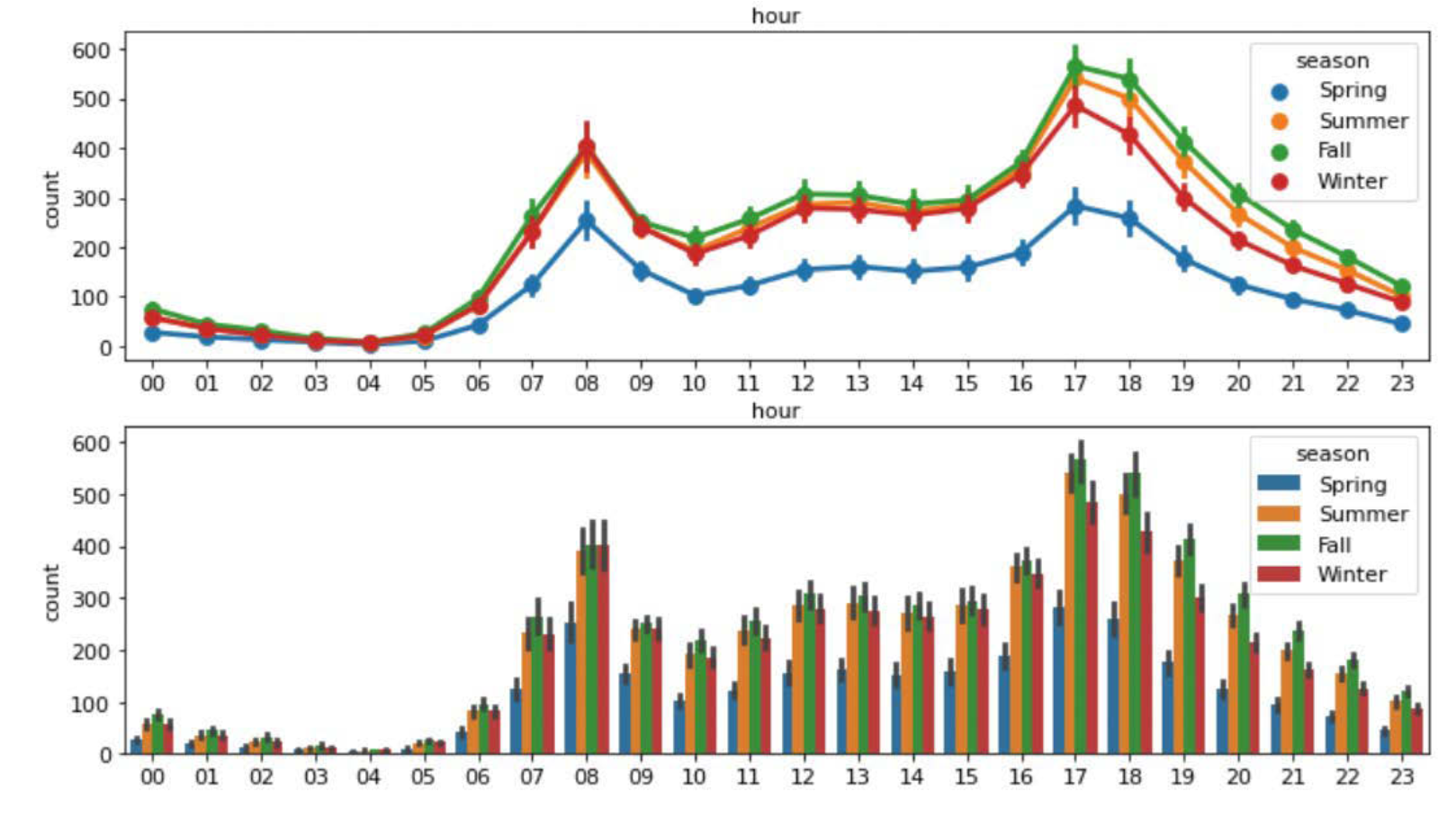
그림 출처 https://goldenrabbit.co.kr/2022/04/18/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D%C2%B7%EB%94%A5%EB%9F%AC%EB%8B%9D-%EB%AC%B8%EC%A0%9C%ED%95%B4%EA%B2%B0-%ED%83%90%EC%83%89%EC%A0%81-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EB%B6%84%EC%84%9D-%EC%8B%9C%EA%B0%81/
그래프를 보았을 때, 막대 그래프로 그린다면 봄, 여름, 가을, 겨울 계절들의 차이를 알기 어렵다.
하지만 포인트 플롯으로 그린다면 계절별 차이가 한 눈에 들어온다.
한 화면에 여러 그래프를 그려 비교할 때는 포인트플롯을 사용하는게 좋다!!!
3.3 박스플롯(boxplot)
박스플롯 boxplot()
- 막대 그래프나 포인트플롯보다 더 많은 정보(구체적으로 5가지 요약 수치)를 제공한다.
- 5가지 요약 수치
최솟값제 1사분위 수(Q1)제 2사분위 수(Q2)제 3사분위 수(Q3)최댓값
- 제 1사분위 수(Q1) : 전체 데이터 중 하위 25%에 해당하는 값
- 제 2사분위 수(Q2) : 50%에 해당하는 값(중앙값)
- 제 3사분위 수(Q3) : 상위 25%에 해당하는 값
- 사분위 범위 수(IQR) :
Q3 - Q1 - 최댓값 :
Q3 + (1.5 * IQR) - 최솟값 :
Q1 + (1.5 * IQR) - 이상치 :
최댓값보다 큰 값과최솟값보다 작은 값
다음은 박스플롯의 구성요소 그림이다.
그림 출처 https://goldenrabbit.co.kr/2022/04/18/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D%C2%B7%EB%94%A5%EB%9F%AC%EB%8B%9D-%EB%AC%B8%EC%A0%9C%ED%95%B4%EA%B2%B0-%ED%83%90%EC%83%89%EC%A0%81-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EB%B6%84%EC%84%9D-%EC%8B%9C%EA%B0%81/
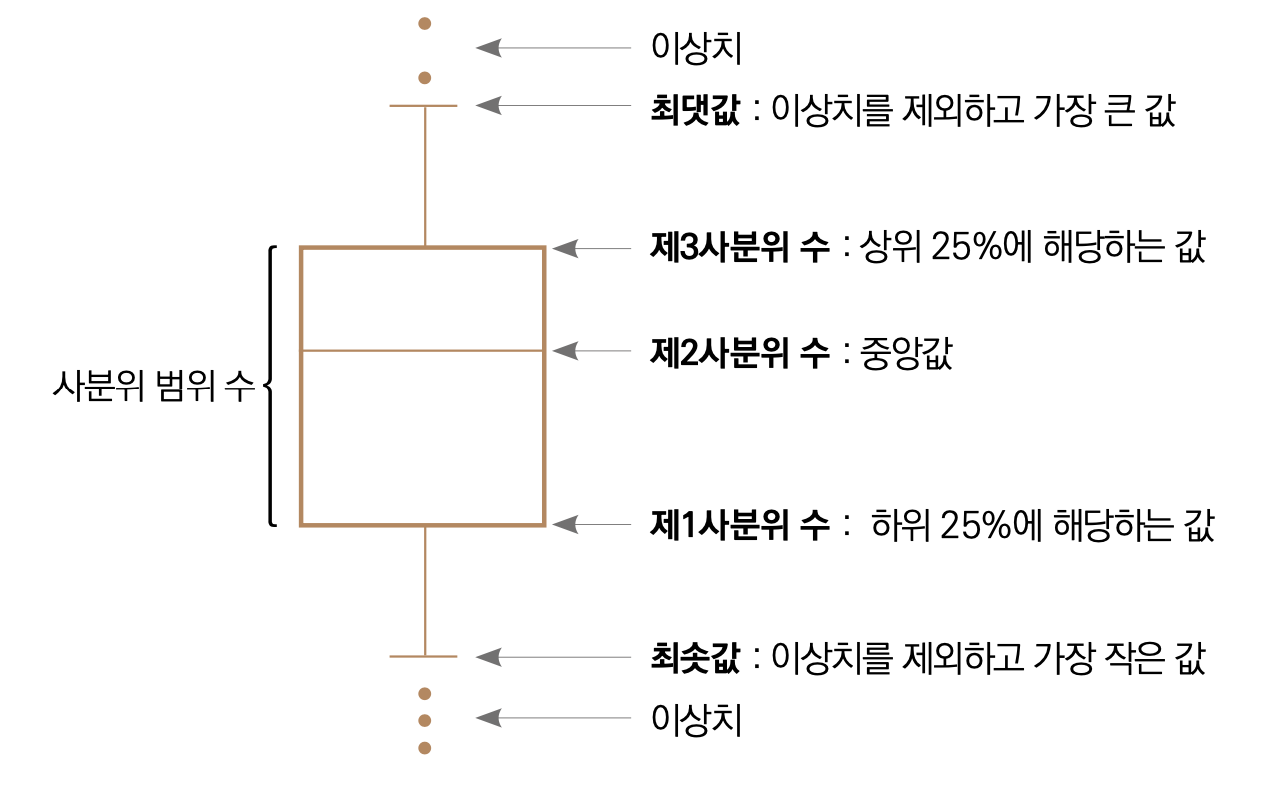
박스 플롯은 boxplot()으로 그릴 수 있다.
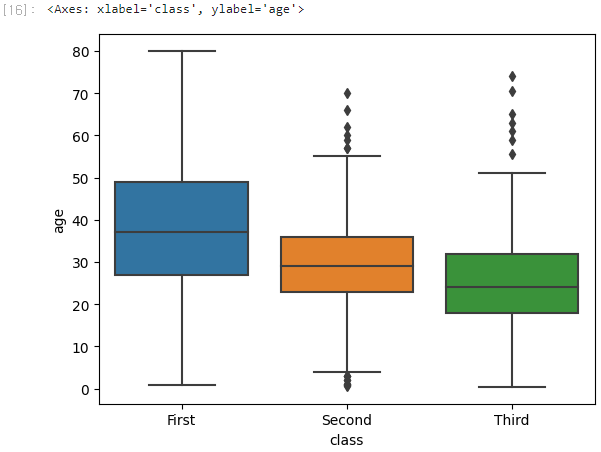
그럼 이제 타이타닉 탑승자 등급별 나이를 박스플롯으로 그려보겠다.
boxplot()의 x, y파라미터에 각각 범주형 데이터(class)와 수치형 데이터(age)를 전달하면 된다.
Code
sns.boxplot(x='class', y='age', data=titanic)
Result
3.4 바이올린플롯(violinplot)
바이올린플롯 violinplot()
-
박스플롯과 커널밀도추정 함수를 합쳐 놓은 그래프라고 볼 수 있다.
-
박스플롯이 제공하는 정보를 모두 포함하며, 모양은 커널밀도추정 함수 그래프 형태이다.
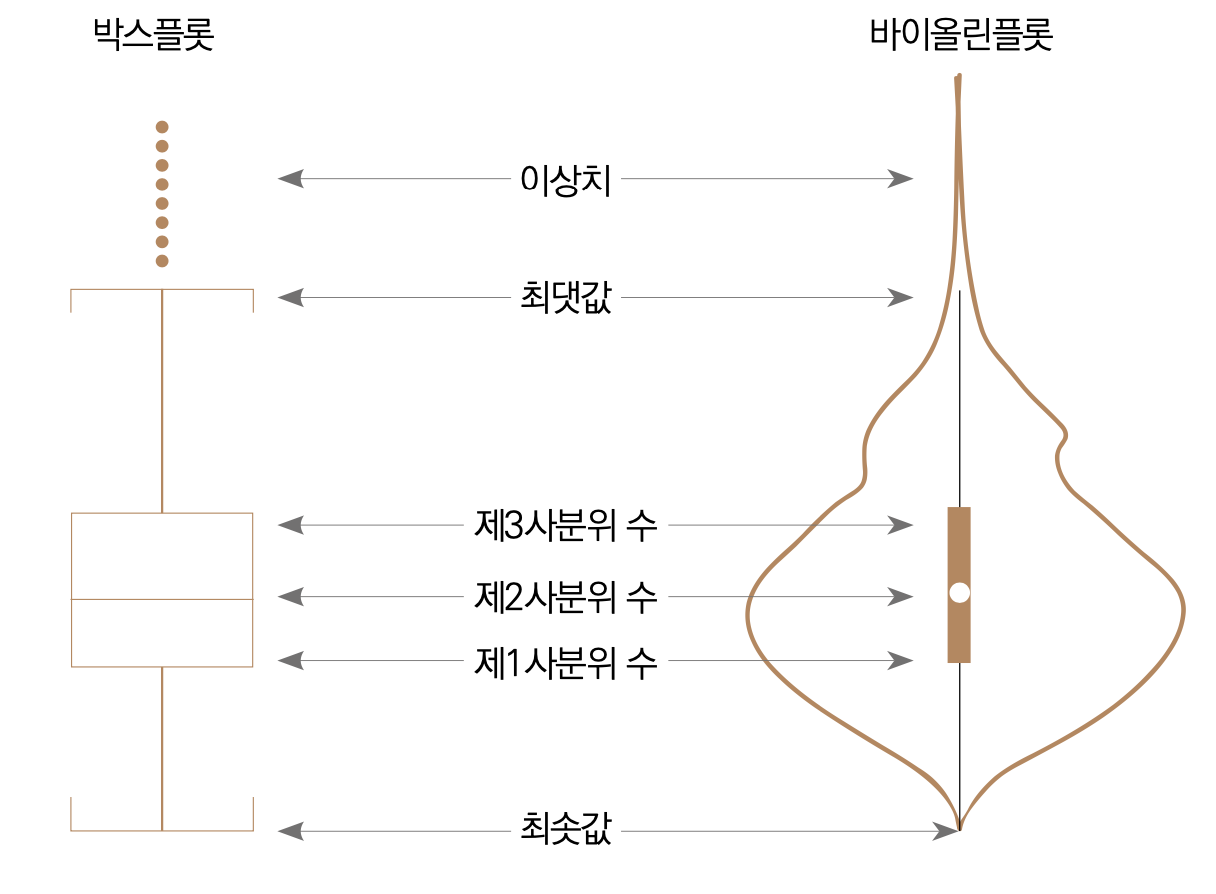
그림 출처 https://goldenrabbit.co.kr/2022/04/18/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D%C2%B7%EB%94%A5%EB%9F%AC%EB%8B%9D-%EB%AC%B8%EC%A0%9C%ED%95%B4%EA%B2%B0-%ED%83%90%EC%83%89%EC%A0%81-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EB%B6%84%EC%84%9D-%EC%8B%9C%EA%B0%81/
바이올린플롯은 violinplot()으로 그릴 수 있다.
앞의 박스플롯과 비교해보기 위해 등급(class)별 나이(age)를 그려보겠다.
Code
sns.violinplot(x='class', y='age', data=titanic)
Result
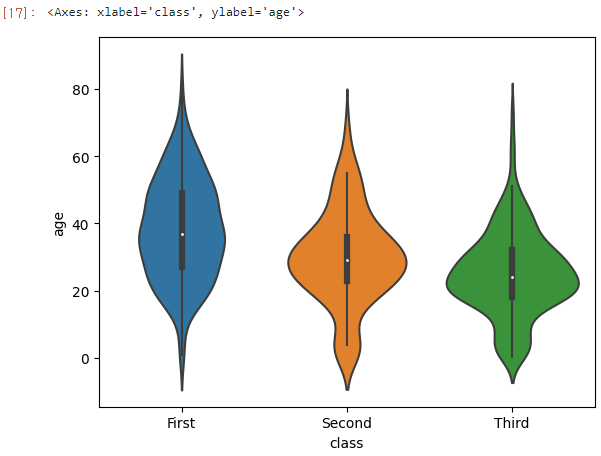
boxplot 그래프와 비교해보았을 때, 각 범주별로 5가지 요약 수치를 한눈에 보고싶으면 boxplot이 좋을 것 같다.
수치형 데이터의 전체적인 분포 양상을 알고 싶다면 violinplot이 좋을 것 같다.
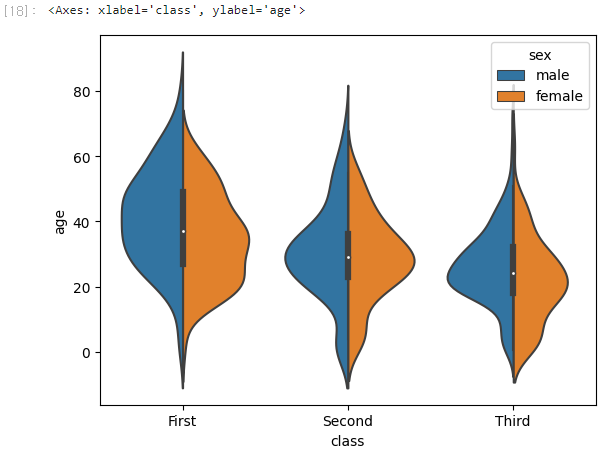
다음으로 성별에 따른 등급별 나이 분포를 살펴보자.
hue='sex'를 파라미터를 추가로 전달하면 된다.
더 나아가서, split=True를 전달하면 hue에 전달한 피처를 반으로 나누어 보여준다.
Code
sns.violinplot(x='class', y='age', hue='sex', data=titanic, split=True)
Result
3.5 카운트플롯(countplot)
카운트플롯 countplot()
- 범주형 데이터의 개수를 확인할 때 사용하는 그래프이다.
countplot()으로 그릴 수 있음.x파라미터에범주형 데이터를 전달하면 된다.
다음은 타이타닉 탑승자의 등급별 인원수를 countplot()으로 그려보자.
Code
sns.countplot(x='class', data=titanic)
Result
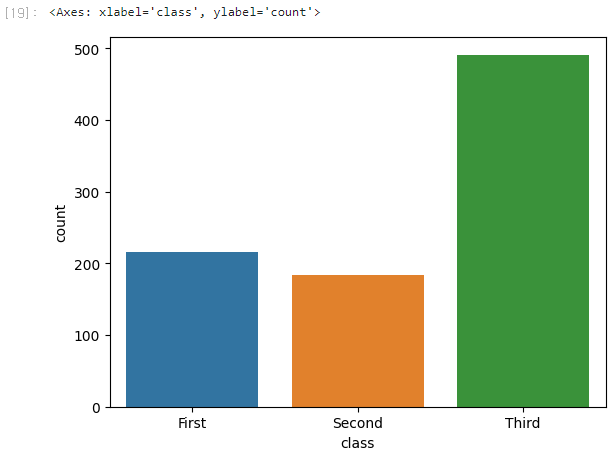
countplot을 사용하여 범주형 데이터의 개수를 파악할 수 있다!!!
Tip!!!
x파라미터를y로 바꾸면 그래프 방향을 바꿀 수 있다.sns.countplot(y='class', data=titanic)
- 이는 범주형 데이터 개수가 많이 그래프가 옆으로 너무 넓어져 보기 불편할 때 유용하다.
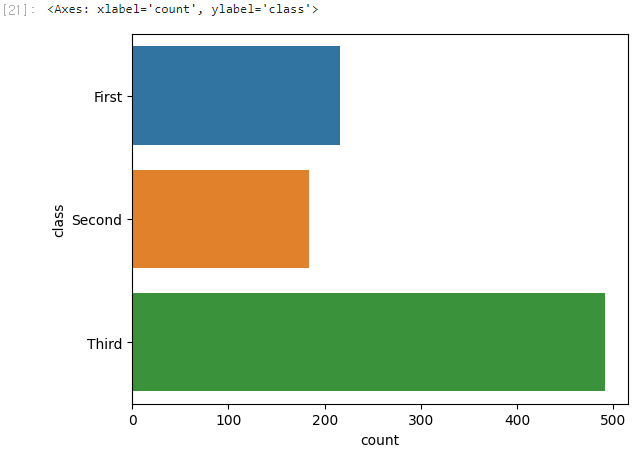
barplot() vs. countplot()
두 그래프는 비슷해보이지만 다르다.
barplot() : 범주형 데이터별 수치형 데이터의 평균을 구해주기 때문에 피처를 두 개 받음.
countplot(): 피처를 범주형 데이터 하나만 받는다.
sns.barplot(x='class', y='fare', data=titanic) # 막대 그래프
sns.countplot(y='class', data=titanic) # 카운트플롯Tip!!!
barplot()으로는 평균이 아닌 중앙값, 최댓값, 최솟값을 구할 수도 있다.sns.barplot(x='class', y='fare', data=titanic, estimator=np.median) # 중앙값
sns.barplot(x='class', y='fare', data=titanic, estimator=np.max) # 최댓값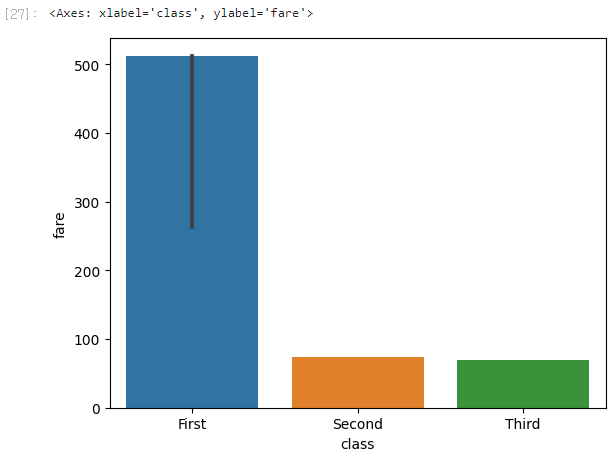
sns.barplot(x='class', y='fare', data=titanic, estimator=np.min) # 최솟값
3.6 파이 그래프(pie)
파이 그래프 pie
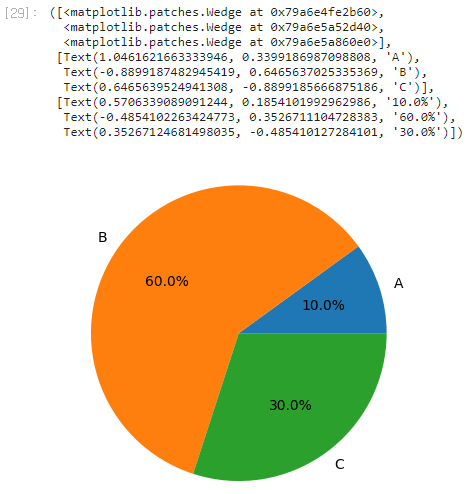
- 범주형 데이터별 비율 을 알아볼 때 사용하기 좋은 그래프다.
- 이는
seaborn에서 지원하지 않기 때문에matplotlib을 사용해서 그려야 한다. pie()함수를 사용하여 그리면 된다.x파라미터에는비율,labels파라미터에는 범주형 데이터 레이블명을 전달하면 된다.autopct파라미터를 통해 비율을 숫자로 나타낼 수 잇다.
Code
import matplotlib.pyplot as pltx = [10, 60, 30] # 범주형 데이터별 파이 그래프의 부채꼴 크기(비율) labels = ['A', 'B', 'C'] # 범주형 데이터 레이블plt.pie(x=x, labels=labels, autopct='%.1f%%')
Result
Wrap Up
이번 포스팅은 범주형 데이터를 시각화하는 여러 방식에 대해서 알아보았다.
사실 데이터 시각화 방식에는 다양한 방법이 있는 걸로 알고 있었지만, 이렇게 기본적으로 많이 쓰이는 방식 위주로 공부한건 처음이라서 기본기부터 다지는 느낌이라 괜찮았다.
다음 포스팅에서는 데이터 관계 시각화에 대해 글을 작성해 보겠다.
