1. 탐색적 데이터 분석(EDA)과 그래프
그래프를 활용해 데이터가 어떻게 구성돼 있는지, 어떤 피쳐가 중요한지, 어떤 피처를 제거할지, 어떻게 새로운 피처를 만들지 등 모델링에 필요한 다양한 정보를 얻을 수 있다.
이번 포스팅에서는 탐색적 데이터 분석(EDA)에 필요한 주요 그래프 몇 가지를 알아보겠다.
간단한 설명과 코드가 올라갈 예정이다.
2. 수치형 데이터 시각화
수치형 데이터
- 일정한 범위 내에서 어떻게 분포(
distribution)되어있는지가 중요 - 고르게 퍼져 있을 수도, 특정 영역에 몰려 있을 수도 있음.
- 이 분포를 알아야 데이터를 어떻게 변환(
transformation)할지, 어떻게 해석해서 활용할지 판단할 수 있음.
seaborn을 import하고 data loading하는 code
import seaborn as sns
titanic = sns.load_dataset('titanic') # 타이타닉 데이터 불러오기titanic.head()result

데이터를 살펴보니 수치형 데이터(age, fare 등)와 범주형 데이터(sex, embarked, class 등)가 공존한다.
이번 포스팅에서는 수치형 데이터를 시각화하는 예를 살펴보겠다.
다음은 seaborn이 제공하는 주요 분포도 함수이다.
seaborn이 제공하는 주요 분포도 함수
histplot(): 히스토그램kdeplot(): 커널밀도추정 함수 그래프displot(): 분포도rugplot(): 러그플롯
2.1 히스토그램
수치형 데이터의 구간별 빈도수를 나타내는 그래프
titanic데이터의age피처에 대한 히스토그램
sns.histplot(data=titanic, x='age')result
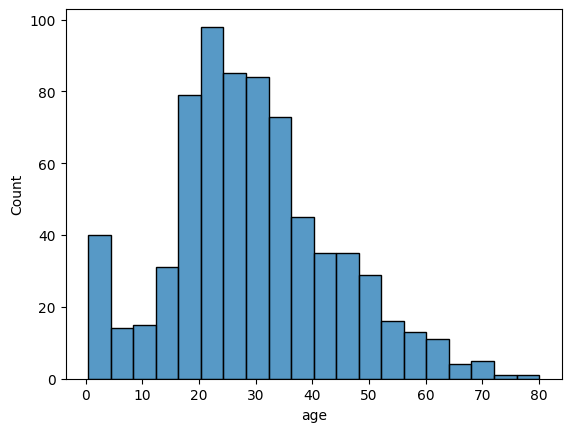
나이를 구간별로 나누어, 각 구간에 해당하는 사람이 몇 명인지 나타낸 그래프
histplot()의 data파라미터에 전체 데이터셋을 DataFrame형식으로 전달하고, x 파라미터에 분포를 파악하려는 피처를 전달하면 된다.
bins 파라미터를 지정하여 구간을 변경할 수 있다.
sns.histplot(data=titanic, x='age', bins=10)result
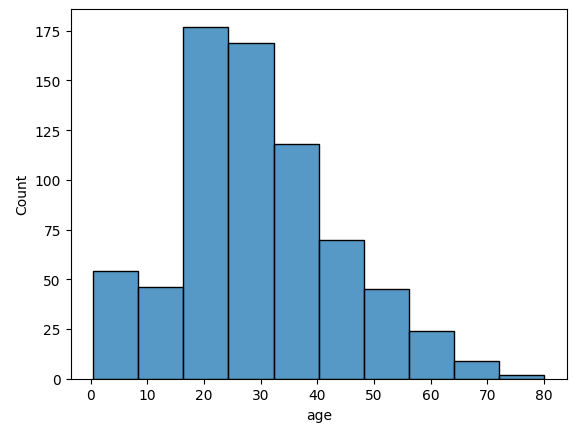
히스토그램은 기본적으로 수치형 데이터 하나에 대한 빈도를 나타낸다.
이 빈도를 특정 범주별로도 구분해서 보고싶다면 hue파라미터에 해당 범주형 데이터를 전달하면 된다.
생존여부(
alive피처)에따른 연령 분포를 그리는 코드
sns.histplot(data=titanic, x='age', hue='alive')*result**
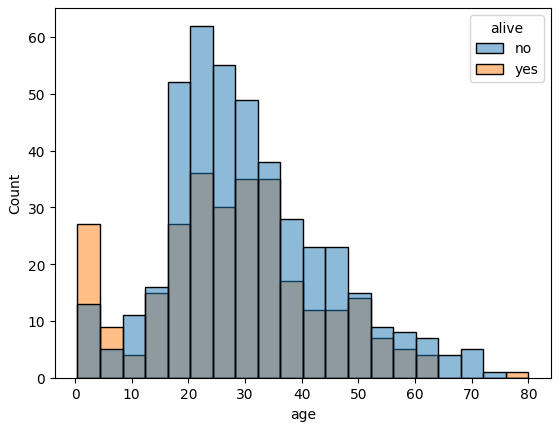
생존자 수 그래프와 사망자 수 그래프가 포개지게 그려졌는데, 회색 구간이 두 그래프가 서로 겹친 부분이다.
포개지 않고 생존자 수와 사망자 수를 누적해 표현하기 위해서는 multiple='stack'을 전달하면 된다.
포개지 않고 그래프를 그리는 코드
sns.histplot(data=titanic, x='age', hue='alive', multiple='stack')result
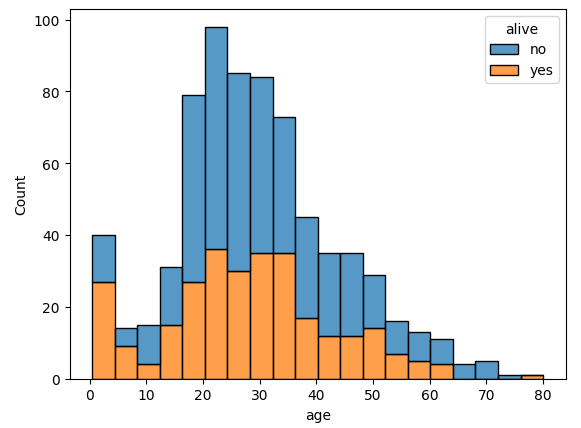
그래프가 훨씬 보기 좋아졌다~!
2.2 커널밀도추정 함수 그래프(kdeplot)
커널밀도추정(kernel density estimation) 히스토그램을 매끄럽게 곡선으로 연결한 그래프로 알고 있으면 된다.
실제로 탐색적 데이터 분석 시에는 많이 쓰지는 않는다고 함!
커널밀도추정 함수를 그리는 code
sns.kdeplot(data=titanic, x='age')result
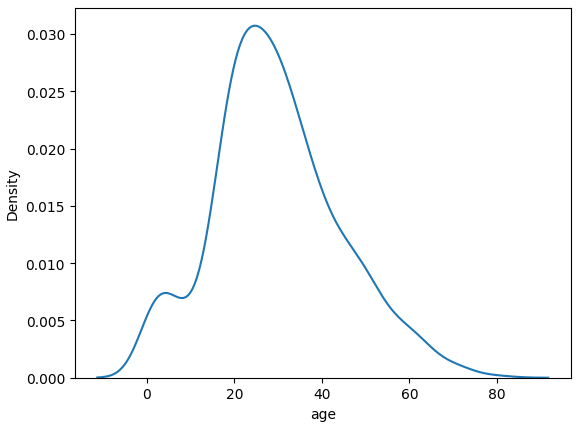
이전의 히스토그램과 비교해보면 히스토그램을 매끄럽게 연결한 모양인 것을 알 수 있다. 히스토그램은 이산적이지만, 커널밀도추정 함수 그래프는 연속적!
이전처럼 파라미터로 hue='alive'와 multiple='stack을 전달하면 다음과 같이 바뀐다.
code
sns.kdeplot(data=titanic, x='age', hue='alive', multiple='stack')result
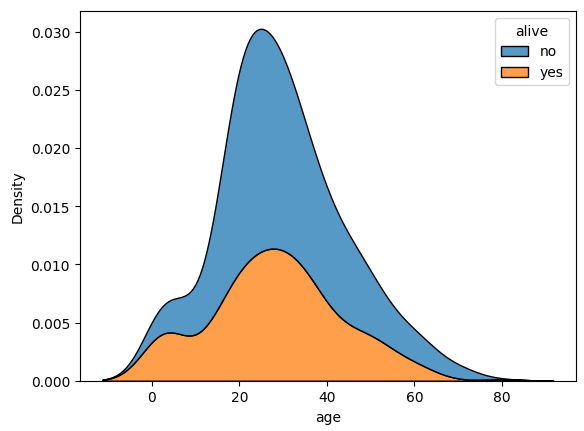
이전의 누적 히스토그램과 비교했을 때, 이산적인지 연속적인지의 차이가 있을 뿐, 전체적인 모양새는 거의 같다.
2.3 분포도(displot)
분포도 : 수치형 데이터 하나의 분포를 나타내는 그래프
파라미터만 조정하면 histplot(). kdeplot()이 제공하는 그래프를 모두 그릴 수 있기 때문에 캐글에서 분포도를 그릴 때 displot()을 많이 사용한다.
seaborn 0.11.0 변경점
- 분포도 함수가
distplot()에서displot()으로 바뀌었음.- 기능은 같아도 세부 파라미터가 다르니 다른 사람이 작성한 코드를 볼 때 유의해야함!
code
sns.displot(data=titanic, x='age')result
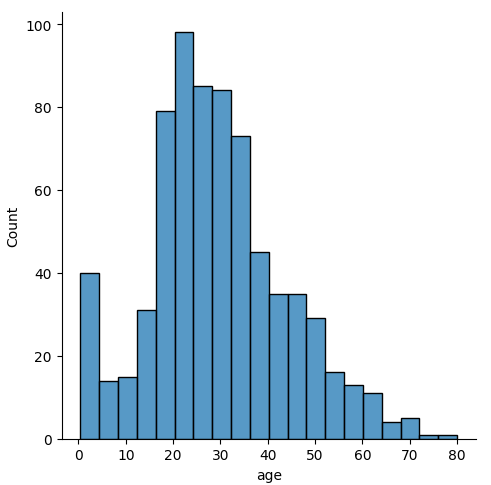
histplot()을 이용해 그린 히스토그램과 비교했을 때, 크기만 다를 뿐이다.
histplot()으로 그린 히스토그램
앞서 그렸던 커널밀도추정 함수 그래프도 그릴 수 있다. kind 파라미터에 kde를 전달하면 된다.
code
sns.displot(data=titanic, x='age', kind='kde')result
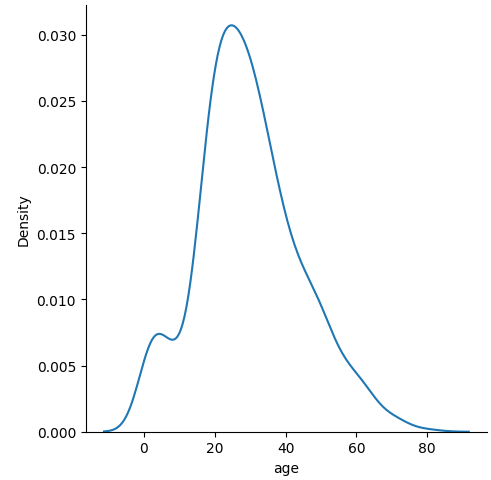
커널밀도추정 함수 그래프도 역시 kdeplot()으로 그린 결과와 그래프 크기만 다르다.
kdeplot()으로 그린 커널밀도추정 함수 그래프
히스토그램과 커널밀도추정 함수 그래프를 동시에 그릴 수도 있다.
kde=True를 파라미터로 전달하면 된다.
code
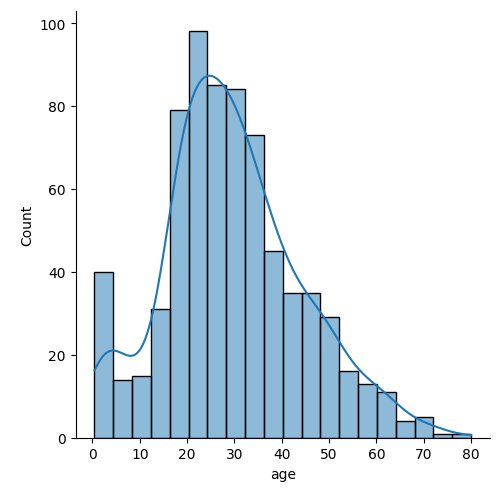
sns.displot(data=titanic, x='age', kde=True)result
2.4 러그플롯(rugplot)
러그플롯 : 주변 분포(marginal distribution)를 나타내는 그래프
주로 다른 분포도 그래프와 함께 사용한다
Using kdeplot and rugplot code
sns.kdeplot(data=titanic, x='age')
sns.rugplot(data=titanic, x='age')result
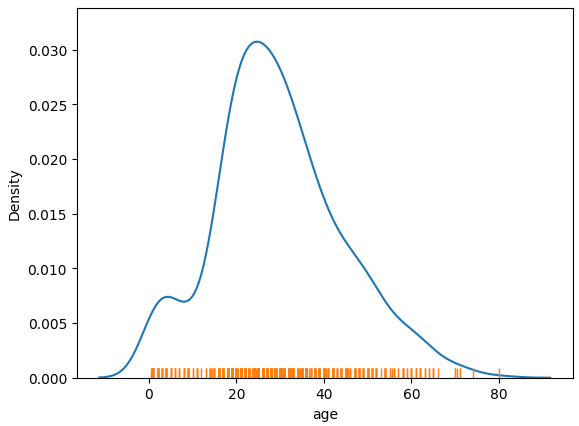
그려진 그래프의 결과와 같이 러그플롯은 단일 피처(age)가 어떻게 분포돼 있는지를 x축 위에 작은 선분(러그)로 표시한다.
값이 밀집되어 있을수록 작은 선분들도 밀집돼 있다.
Wrap Up
- 이번 포스팅에서는 수치형 변수의 시각화 방식을 알아보았다. 다음 포스팅에서는 범주형 데이터를 시각화하는 방법을 알아보는 글을 작성하겠다.
