1. kaggle Notebook 둘러보기
저번 포스팅에서는 kaggle 환경에서 notebook을 실행하기까지 진행했었다. 이번 포스팅에서는 kaggle에서 제공하는 notebook 환경을 둘러보고 여러 기능들을 사용해보는 시간이 되겠다.
캐글 노트북 실행 화면
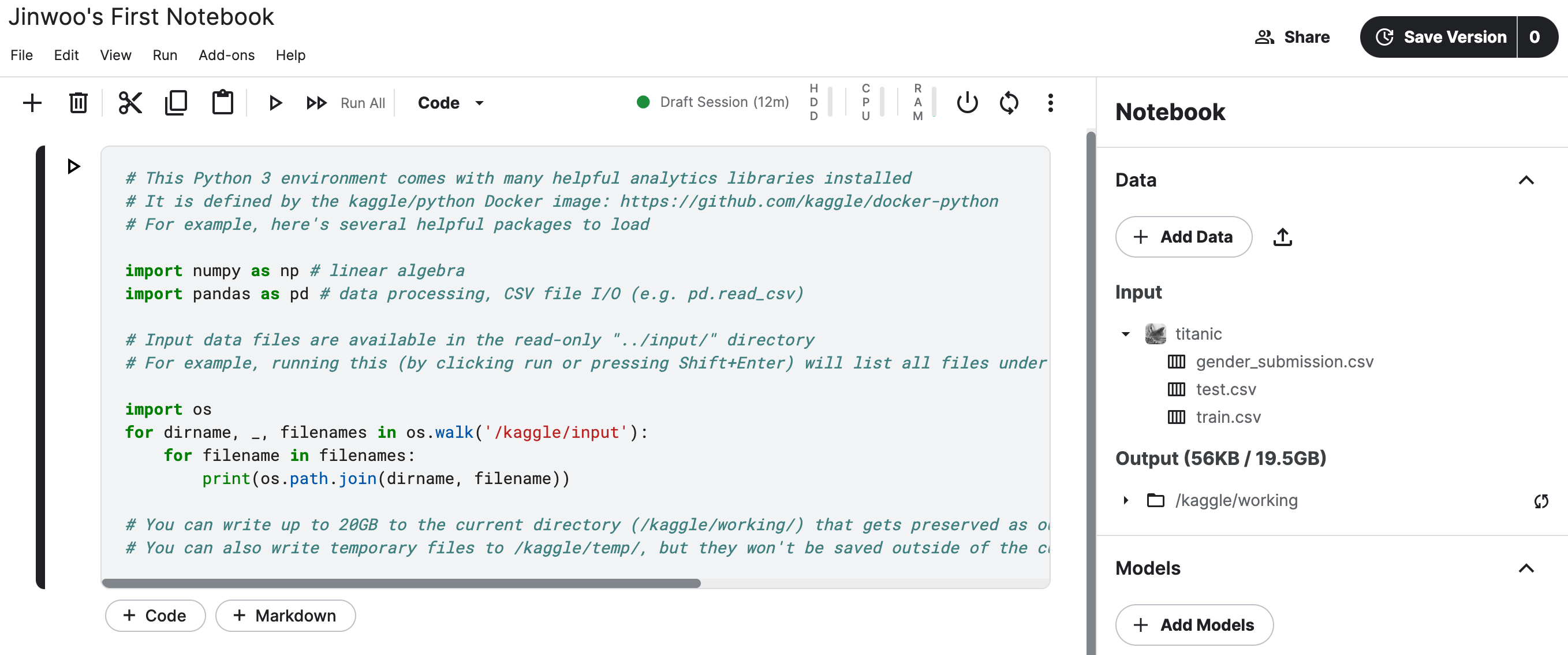
- 왼쪽 최상단은 현재 노트북 제목을 표시하는 영역이다. 기존 랜덤으로 생성된 제목에서
"Jinwoo's First Notebook"으로 변경해 주었다. - 우측의
[Data]탭을 클릭하여 펼치고, 이후[Input]탭을, 마지막으로titanic디렉터리를 다시 펼치면gender_submission.csv,test.csv,train.csv파일이 있다.gender_submission.csv: 제출용 샘플 데이터test.csv: 테스트용 데이터train.csv: 훈련용 데이터
맨 처음 캐글 노트북 실행시 첫 번째 셀(cell)에 다음과 같이 코드가 자동으로 입력되어있음.
이를 실행하고 싶다면
Ctrl+Enter: 현재 cell만 실행Shift+Enter: 현재 cell을 실행하고 다음 셀로 넘어감
실행할 코드
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session실행 결과
/kaggle/input/titanic/train.csv
/kaggle/input/titanic/test.csv
/kaggle/input/titanic/gender_submission.csv실행된 결과는 각 csv 파일이 위치한 결과를 출력한다. 이는 이전의 [Data]탭에서 살펴본 구조 그대로이다.
하지만 root directory인 kaggle은 [Data]탭에 보이지 않는다. 뒤에서 제출 파일을 만들면 제출 파일은 kaggle/output directory에 담길 것임.
경진대회마다 input directory에 들어있는 데이터가 다르기 때문에 대회에 참가하고 노트북을 생성하면 해당 대회를 위한 데이터가 들어있다.
2. kaggle Notebook 만져보기
조작법 살펴보기
책에서는 셀을 다루는 방법, 마크다운 텍스트 작성 방법, 및 다양한 단축키들을 설명하고 있지만 colab이나 jupyter notebook을 다루어 보았기 때문에 본 포스팅에서는 생략하고 다음 파트인 python 및 설치된 library version을 확인하는 코드 작성으로 넘어가겠다.
(혹시라도 시간이 나면 단축키나 자잘한 정보 작성!!)
3. 파이썬 및 설치된 라이브러리 버전 확인하기
캐글 노트북에는 파이썬을 비롯한 기본적인 라이브러리가 모두 설치되어 있다. 먼저 노트북에 설치된 파이썬 버전을 알아보자.
code
import sys
print(sys.version)result
3.10.12 | packaged by conda-forge | (main, Jun 23 2023, 22:40:32) [GCC 12.3.0]현재 포스팅 작성 기준 파이썬 3.10.12 버전이 설치되어 있다.
다음으로는 설치된 라이브러리들의 버전을 확인해보자.
추후 포스팅할 머신러닝 경진대회를 다루는 6~9장에서는 다음과 같은 버전의 라이브러리들을 사용함
code
import numpy, pandas, seaborn, matplotlib, sklearn, scipy, missingno, lightgbm, xgboost
print('numpy :', numpy.__version__)
print('pandas :', pandas.__version__)
print('seaborn :', seaborn.__version__)
print('matplotlib :', matplotlib.__version__)
print('sklearn :', sklearn.__version__)
print('scipy :', scipy.__version__)
print('missingno :', missingno.__version__)
print('lightgbm :', lightgbm.__version__)
print('xgboost :', xgboost.__version__)result
numpy : 1.23.5
pandas : 2.0.3
seaborn : 0.12.2
matplotlib : 3.7.2
sklearn : 1.2.2
scipy : 1.11.2
missingno : 0.5.2
lightgbm : 3.3.2
xgboost : 1.7.6추후 포스팅할 딥러닝 경진대회를 다루는 11~13장에서는 다음과 같은 버전의 라이브러리들을 사용함
code
import numpy, pandas, matplotlib, sklearn, torch, torchvision, cv2, albumentations, transformers
print('numpy :', numpy.__version__)
print('pandas :', pandas.__version__)
print('matplotlib :', matplotlib.__version__)
print('sklearn :', sklearn.__version__)
print('torch :', torch.__version__)
print('torchvision :', torchvision.__version__)
print('cv2 :', cv2.__version__)
print('albumentations :', albumentations.__version__)
print('transformers :', transformers.__version__)result
numpy : 1.23.5
pandas : 2.0.3
matplotlib : 3.7.2
sklearn : 1.2.2
torch : 2.0.0+cpu
torchvision : 0.15.1+cpu
cv2 : 4.8.0
albumentations : 1.3.1
transformers : 4.32.1현재 포스팅을 하며 실행해본 결과 책이랑은 약간 버전이 다르다. 어쩔 수 없는 부분인게 이 책이 집필된지 시간이 지나서 그런 것 같다.
4. 결과 제출하기
제출 파일 생성
캐글에서는 submission 파일을 제출 파일로 내야 한다. 이를 위해 제출 파일을 생성하고 제출하는 절차를 익혀보겠다.
우선 훈련과 예측을 따로 하지 않고 위에서 사용했던 gender_submission.csv 파일의 내용 그대로를 제출 파일로 사용해보겠다.
code
import pandas as pd
submission = pd.read_csv('/kaggle/input/titanic/gender_submission.csv')
submissionresult
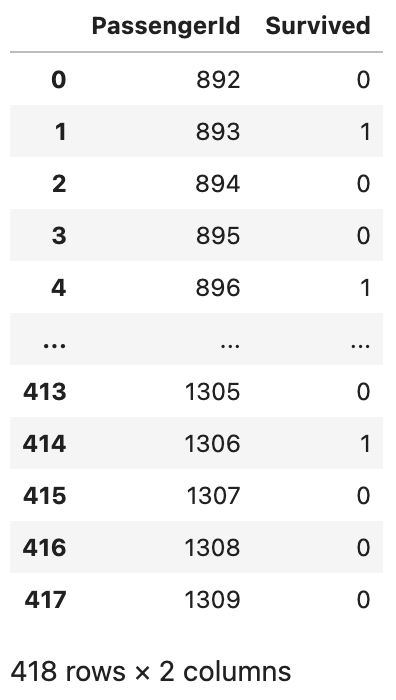
이제 submission 객체를 제출 파일로 변환해보자.
code
submission.to_csv('submission.csv', index=False)result
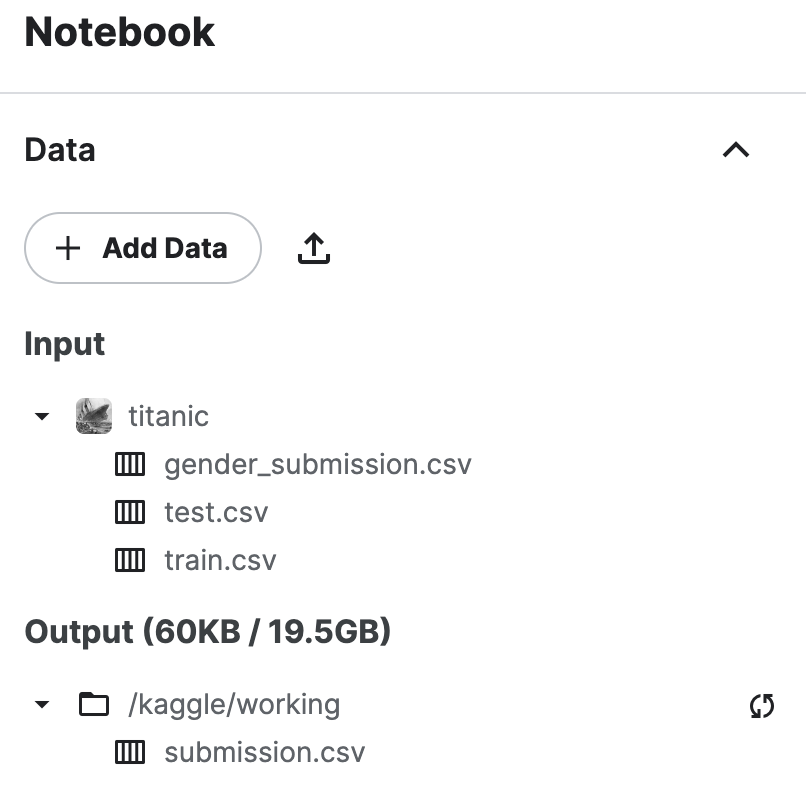
그럼 이제 이렇게 Output 탭에 submission.csv 파일이 생성된다.
커밋하기
생성된 submission.csv 파일을 제출하기 위해 먼저 commit을 해야한다.

노트북 오른쪽 상단에 있는 Save Version 버튼을 누른다.
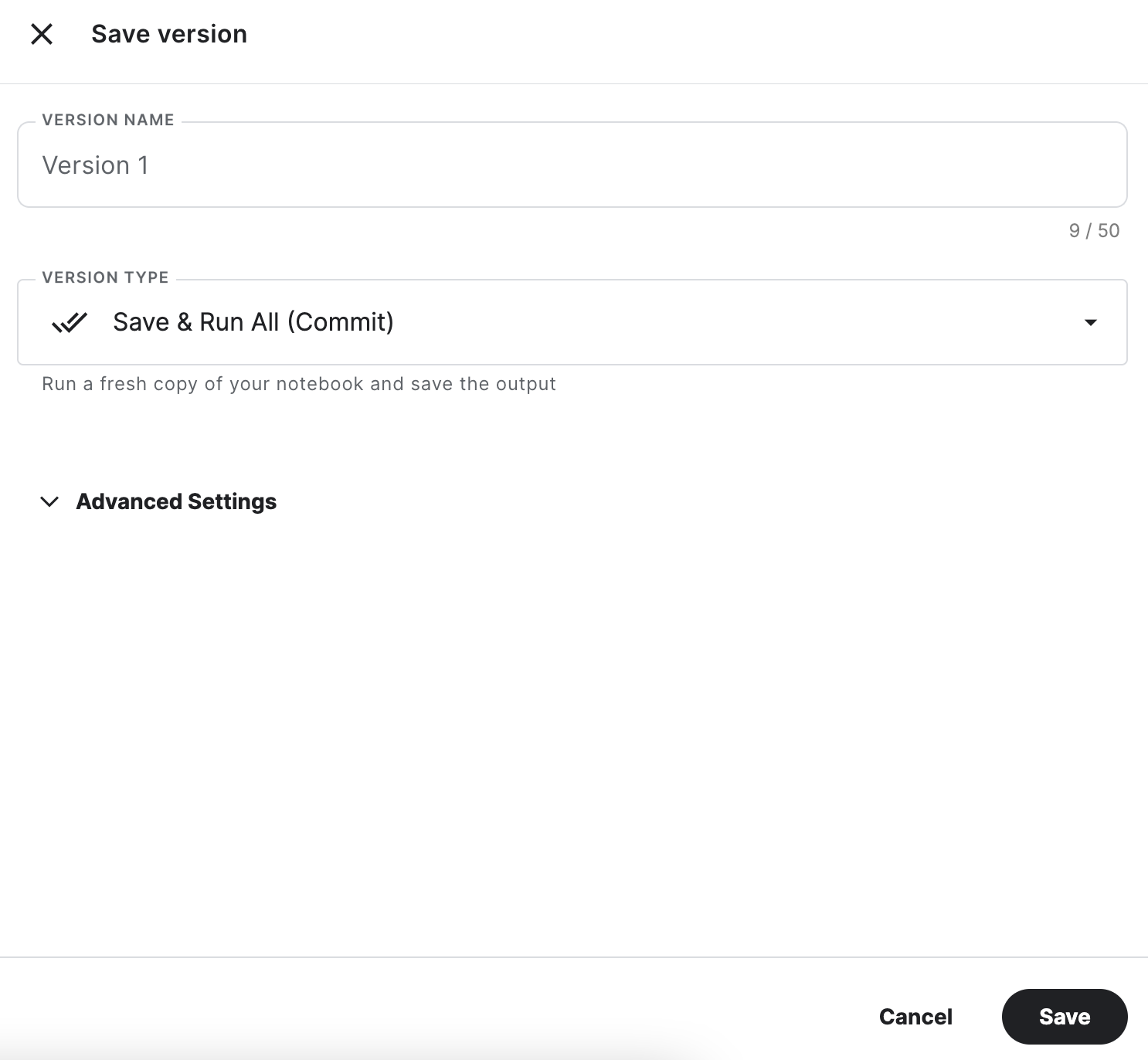
VERSION NAME을 작성하고 [Save] 버튼을 누른다.

그럼 이렇게 커밋이 진행 중임을 알리는 창이 뜨고,

완료되면 다음과 같이 커밋이 완료되었다는 표시가 뜬다.
제출 및 점수 확인하기
커밋을 완료했으니 이제 제출하면 끝이다.

오른쪽 상단의 [Save Version] 옆의 숫자가 0에서 1로 바뀐 것을 확인할 수 있는데, 이는 커밋 횟수를 나타낸다.
이제 이 1로 표시된 영역을 클릭하면 다음과 같은 화면이 나오게 되는데,
오른쪽 상단의 [Go to Viewer]를 클릭하면,
이렇게 내가 지금까지 작성한 code를 볼 수 있다!
책에서는 이 화면에서 [Data] 탭을 클릭해서 제출하는 방식으로 집필이 되어있는데, 시간이 지나면서 조금 변경된 것 같다. 이후는 변경된 방식으로 작성하겠다.
내 노트북 환경에서 오른쪽 탭에서 [Submit to competition] 탭을 클릭하면
이렇게 드로어가 열리는데, [Submit] 버튼을 클릭하면 된다.
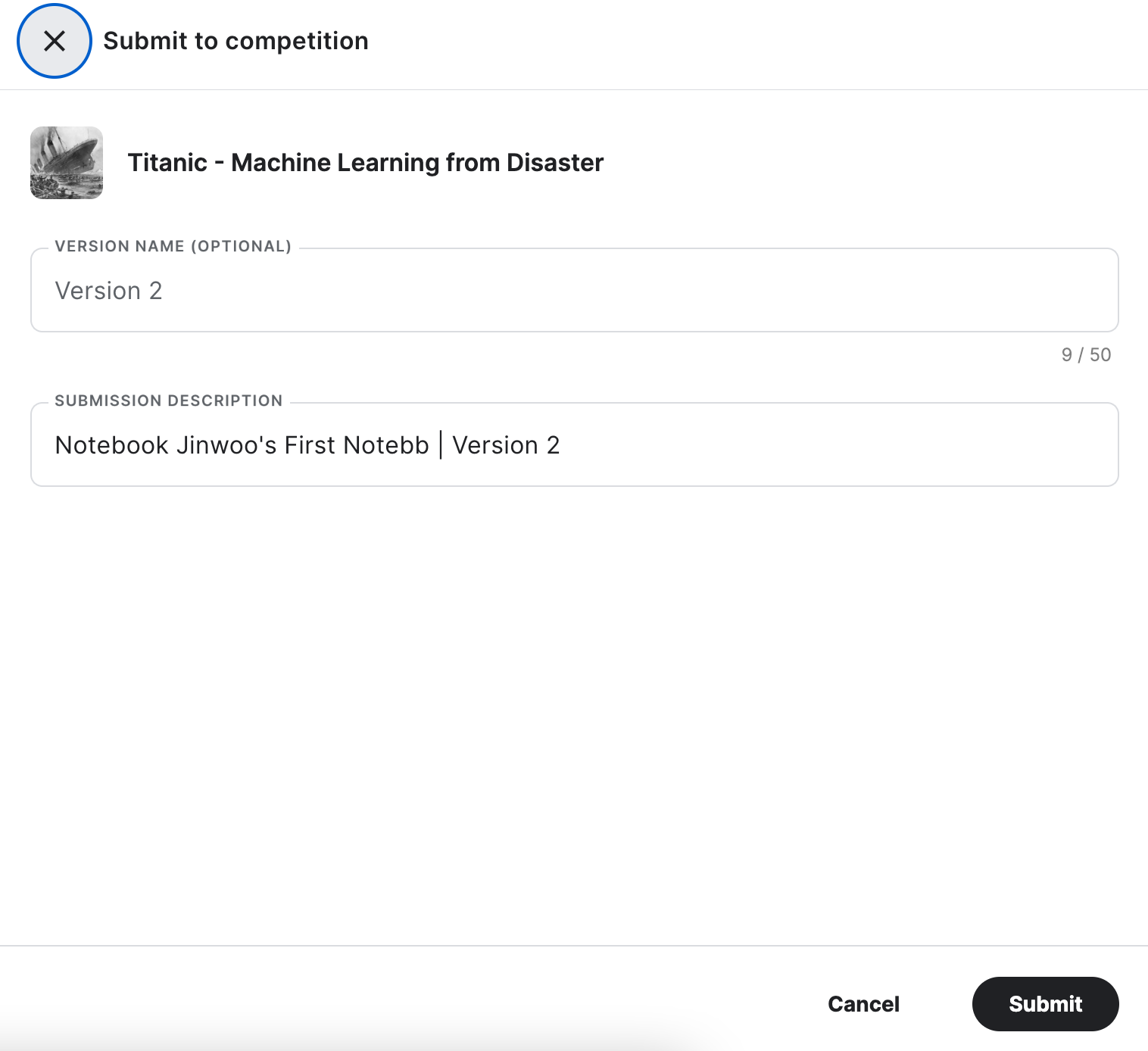
그러면 이렇게 VERSION NAME을 지정할 수 있는 입력 탭과 제출하려는 파일의 설명을 쓸 수 있는 탭이 함께 뜬다. (선택적으로 작성하면 된다.)
이후 [Submit]버튼을 누르게 되면, 다음과 같이 제출중이라는 실행 화면이 뜨고,

제출이 완료됨을 알리는 창과 동시에

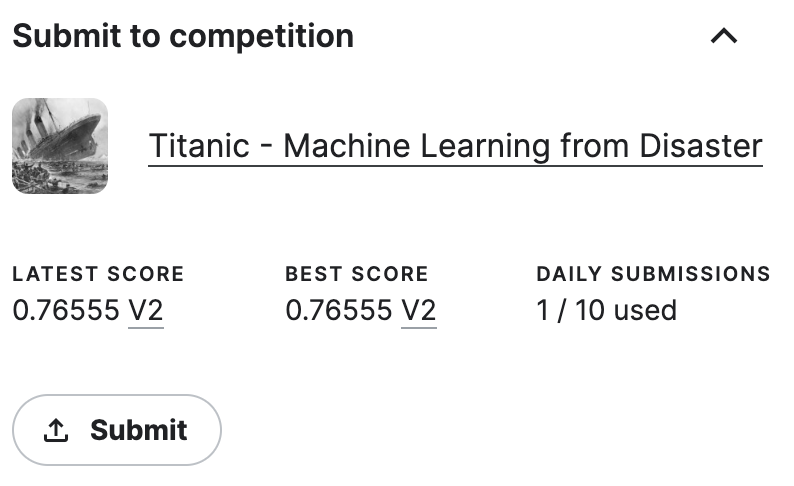
아까 전의 우측 [Submit to competition] 탭에 LATEST SCORE(최근 점수), BEST SCORE(가장 높은 점수), DALY SUBMISSIONS(일일 제출 횟수) 가 뜨게 된다.
이후 몇 등인지 확인하기 위해 Leaderboard 탭으로 이동하여 내 점수(0.76555)점을 확인했고, Jump to your leaderboard position버튼을 클릭하여 전체 제출자 중 몇 등인지 확인해 보았다.
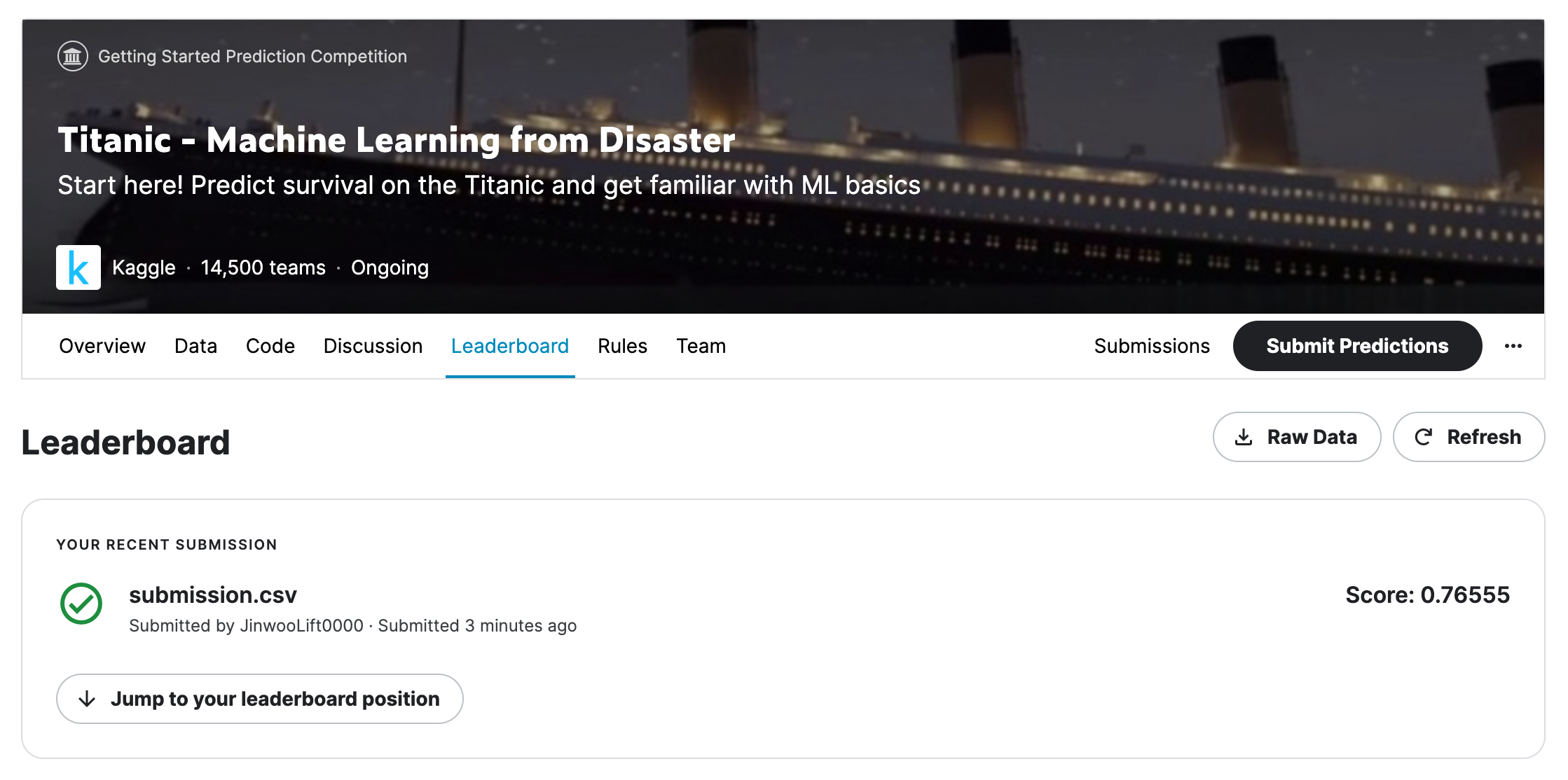
등수 확인
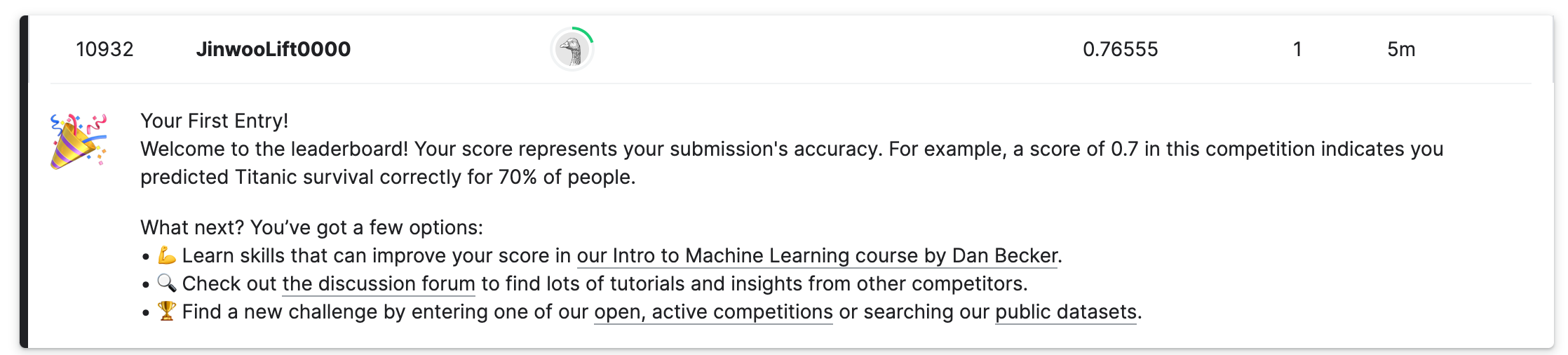
전체 중 10932등으로 확인할 수 있었다. First Entry(첫 제출)이라고 축하를 해준다. 넵 더 열심히 해볼게요
5. 컨트리뷰터(Contributer) 되기
우선 내 Profile로 이동하여 현재 등급이 Novice가 맞는지 확인해 보았다.
확인 결과
Novice가 맞았다.
이후 [Edit Public Profile] 버튼을 클릭하고 편집 화면으로 이동한다.
기본적인 인적 사항을 입력하고 저장했다.
바로 밑에 있는 [Bio] 항목에서 자기소개를 추가했다.

마지막으로 다른 사람 노트북에 추천을 누르고 댓글을 달면 완료이다. 그래서 이후 Code 탭으로 이동해서 맨 첫번 째 보이는 Titanic Tutoral notebook에 추천하고 댓글을 달았다.

두둥!! 나도 이제 Contributor가 되었다!
이렇게 메일까지 날라온다 ㅋㅋ

6. 예제 코드 캐글 노트북 복사하기
책의 모든 예제 코드는 캐글 노트북으로 공유해놨다고 해서 찾아보았다. (제공된 url 주소로 이동하면 됨.)
캐글 노트북을 복사해 실행하는 방법
-
다음 주소로 이동
https://www.kaggle.com/code/werooring/ch0-titanic-basic-solution-using-randomforest
이 책의 저자가 공유해둔 노트북으로, 타이타닉 데이터를 간단히 전처리한 후 랜덤 포레스트 모델로 훈련 및 예측한 코드 -
오른쪽 상단의
[Copy & Edit]버튼 클릭
-
다음과 같이 복사된 notebook을 확인할 수 있다.
-
제대로 복사되었는지 확인 - 상단의
Run All버튼을 클릭하여 전체 셀 한번에 실행해보기(문제 없이 실행이 완료된 모습을 볼 수 있다.)
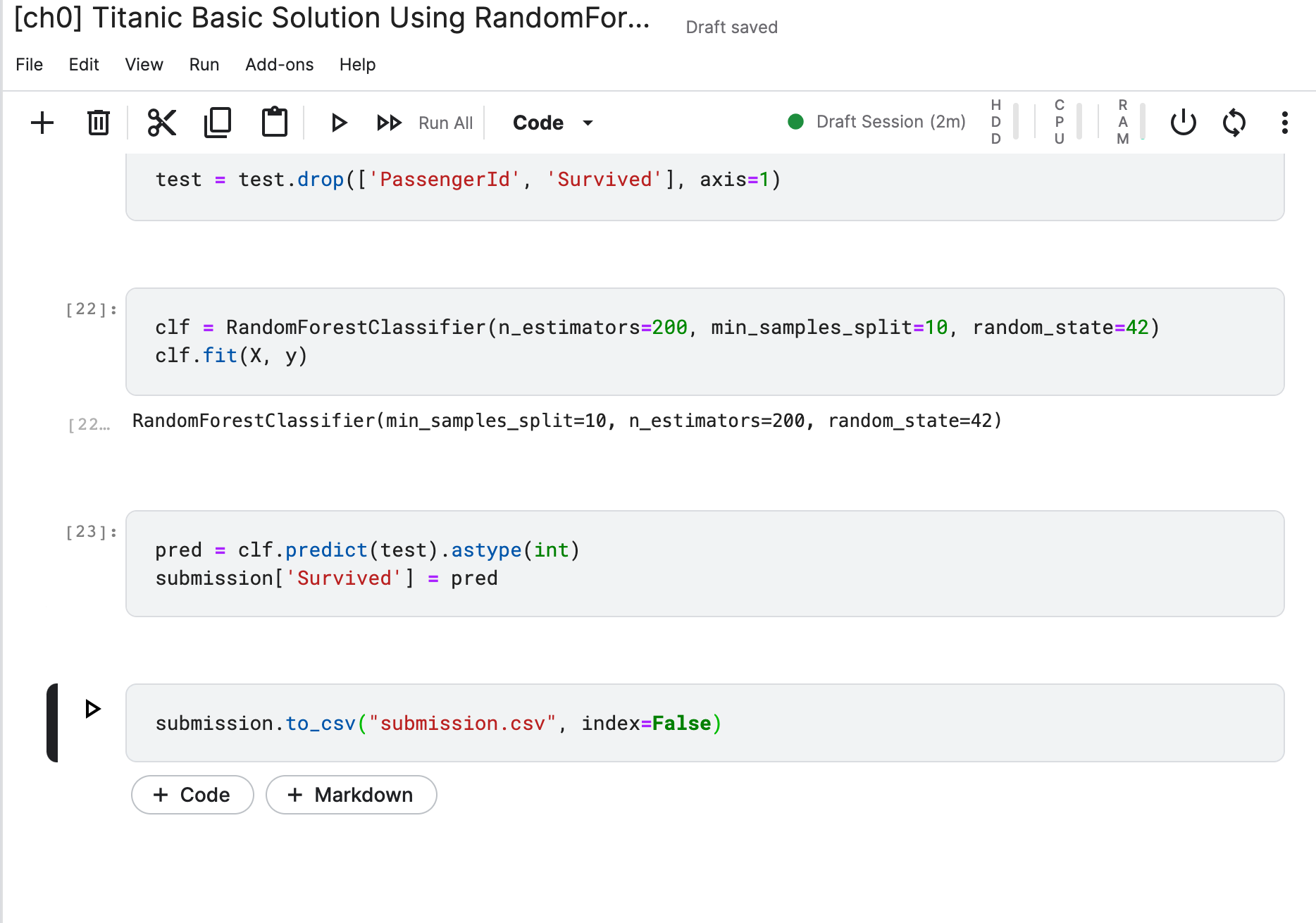
-
커밋 후 제출해보기 - 오른쪽 상단의
[Save Version]버튼을 통해Commit
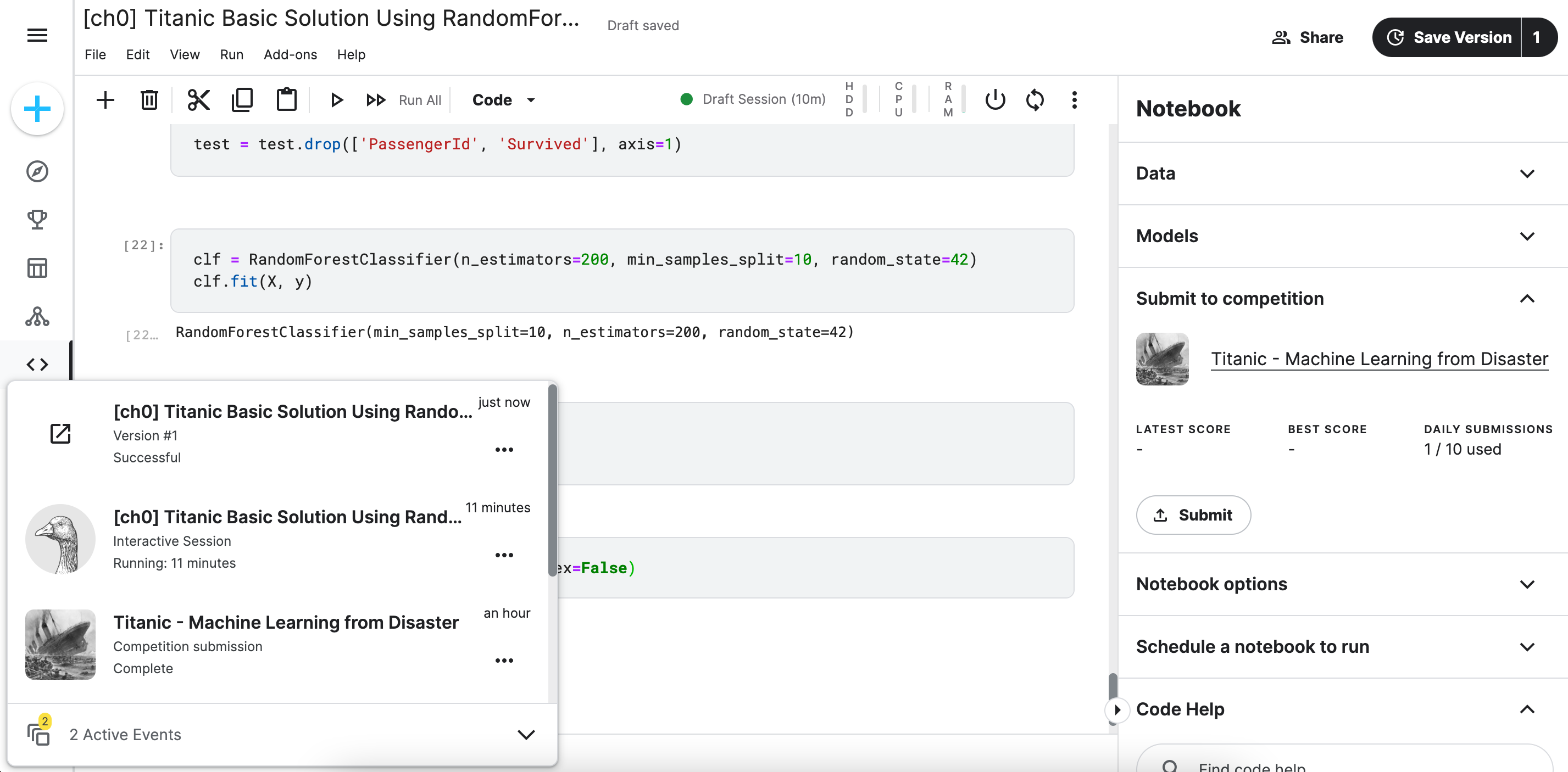
-
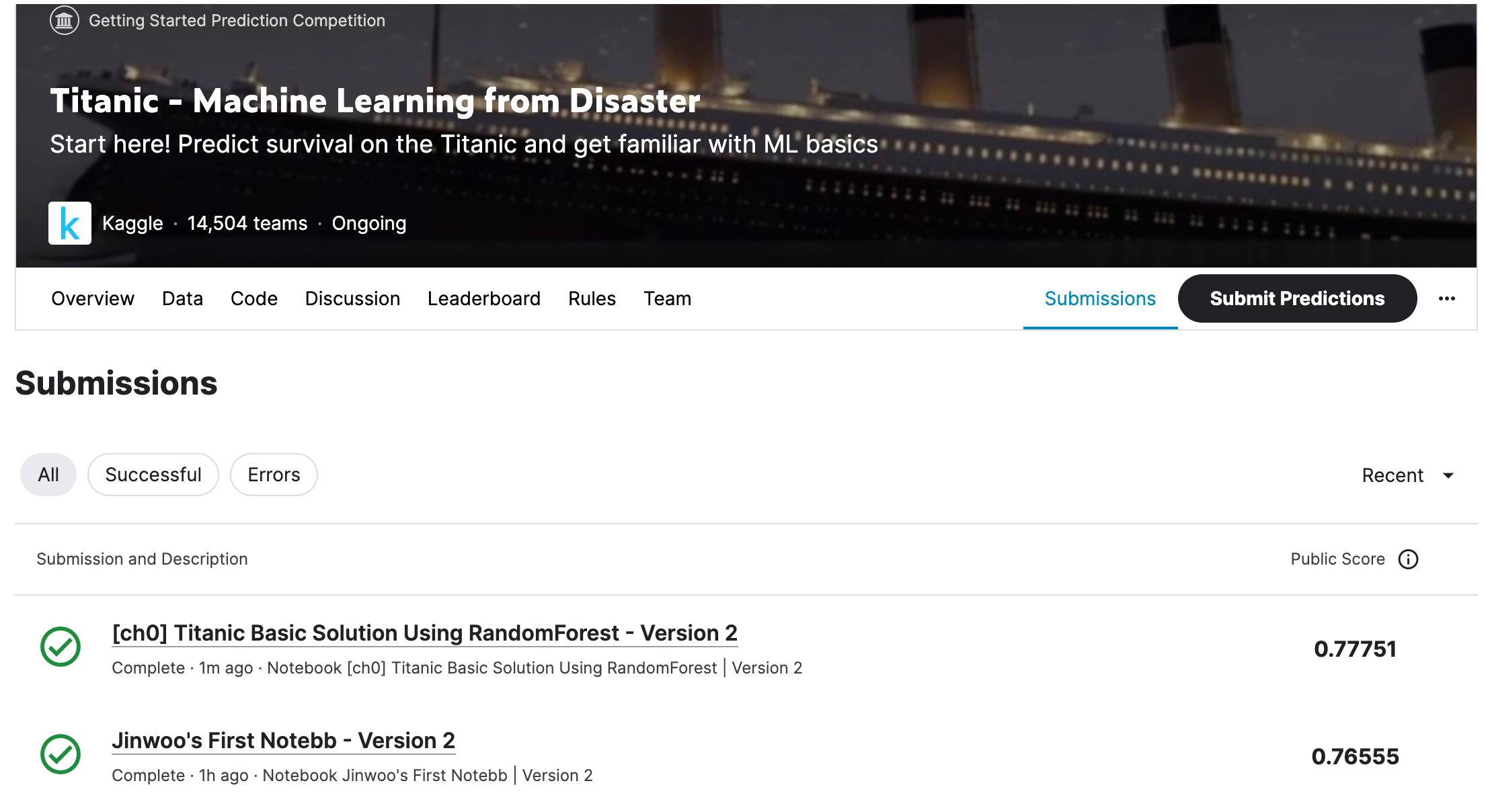
Submit완료 후 점수가 뜬 모습 - 점수가0.77751로 향상 된 것을 볼 수 있었다.

Wrap Up
이번 포스팅에서는 kaggle의 기본적인 기능들을 살펴보고 직접 만져보는 시간이었다. 또한 제출하는 방법을 알아보고 컨트리뷰터가 되어보았다. 마지막으로는 책의 저자가 공유한 예제 노트북을 복사해 실행하는 방법도 알아보았다.
그런데 책에 나온 커밋 후 제출하는 방법은 그냥 [Submit to competition] 탭에서 한번에 해도 되는 것 같다. 그렇게 해도 커밋과 제출을 동시에 할 수 있다.
내용을 적으며 포스팅하기 조금 어려운 면도 있지만, 아직 지치면 안 될것 같다. 더욱 열심히 해보자!! 파이팅!!!
다음 포스팅은 데이터 시각화 파트 내용을 정리하는 포스팅이 될 것 같다!
