ML
1.[ML] Validation set VS Test set 예시를 통해 쉽게 구분하기
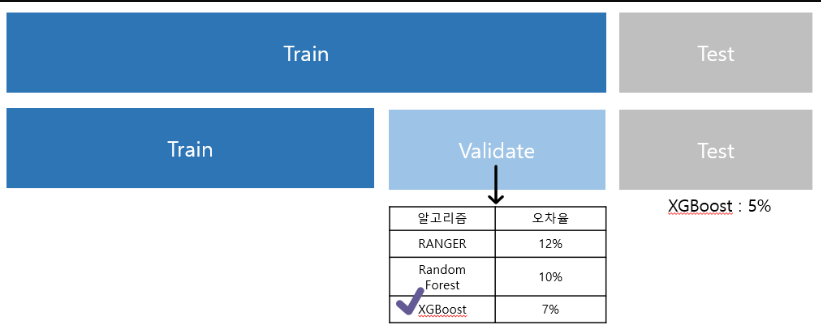
머신러닝을 조금이라도 공부해본 사람들은 머신러닝을 하기전 학습데이터셋, 검증데이터셋, 테스트데이터셋으로 분류한다는 것을 알고 있을 것이다. 그런데 처음에는 검증데이터와 테스트데이터가 헷갈릴 수 있다. Validation set vs Test set Test se
2023년 8월 1일
2.[ML]코드로 이해하는 Ensemble Stacking

유방암 데이터로 양성/악성을 분류 예제실습:knn, random forest, decision tree 알고리즘을 사용하여 모델링을 통해 얻은 예측값을 logistic regression으로 최종모델링하여 결과를 얻음파이썬 머신러닝 완벽 가이드(위키북스)
2023년 10월 7일
3.[ML] 코드로 이해하는 Ensemble Voting
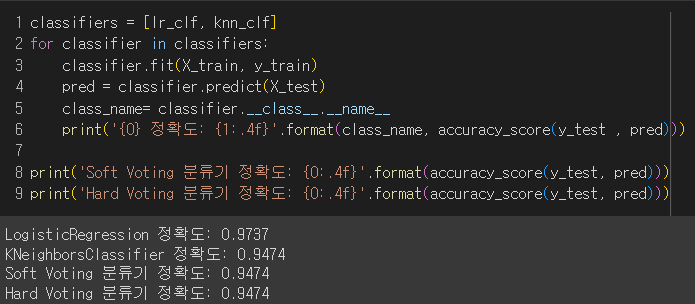
voting은 Ensemble 기법 중 하나이다.특별한 알고리즘을 칭하는 기법이 아니라 기존 모델알고리즘을 어떻게 mix할 것인지에 대한 기법을 의미한다.유방암데이터 실습 코드를 통해 정확히 이해해보자voting 사이킷런 구현
2023년 10월 7일
4.Ensemble 정리

Ensemble 모델의 예측을 합치는 방법 decision tree의 단점을 보완하기 위한 모델 : Random Forest decision tree의 단점 : 학습 성능의 변동이 큼 voting bagging bootstrap aggregation의 약어 bo
2023년 10월 31일
5.[ML]헷갈리기 쉬운 검증데이터 vs 테스트데이터:개념부터 실무 적용 tip까지

머신러닝을 접해본 사람이라면 학습데이터, 검증데이터, 테스트데이터 이렇게 3종류로 나뉜다는 것을 들어봤을거예요. 이제부터 train, validation, test로 표현을 통일할게요. 여기서 헷갈리기 쉬운 개념은 validation data와 test data예
2024년 6월 5일