종류
bagging
-
bootstrap aggregation의 약어
- bootstraping : 표본 복원 재추출 방법 -
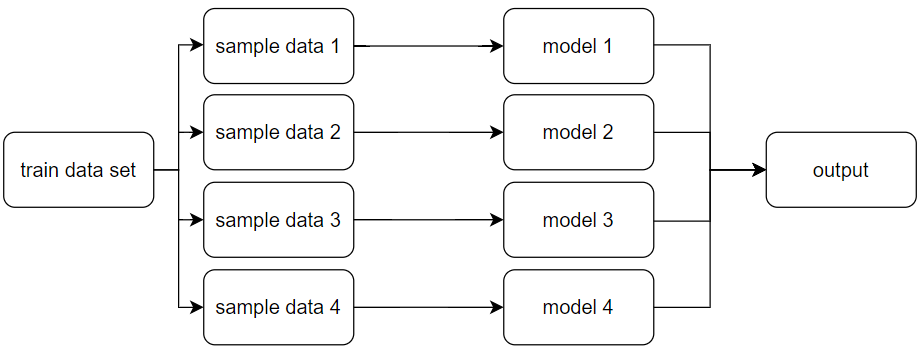
작동원리 : train data set에서 무작위 샘플링을 하여 동일한 알고리즘에 의한 모델링을 수행 > output 평균화
-
각 개별 모델이 임의의 양만큼의 오류를 가지므로 그 결과를 평균화하면 임의의 오류가 상쇄되고 예측이 정답에 가까워짐.
-
집단지성을 통해 오류를 감소시키는 전략
-
머신러닝 모델의 높은 분산 해결에 사용됨
-
대표적인 bagging 앙상블 예시 : random forest
-
사용하는 모델과 알고리즘이 동일하다.
random forest의 경우 하위 모델은 모두 단기 결정트리임.- 학습 성능의 변동이 큰 decision tree의 단점을 보완하기 위한 모델로 잘 알려짐.
-
cov=var(완벽한 상관관계)이면-> 모델 평균화는 전혀 도움이 되지 않음
-
cov=0(완벽한 독립 관계)이면 -> 앙상블 모델의 평균 제곱 오차는 var/k. 예상 제곱 오차는 k(앙상블의 모델 수)가 증가할수록 선형적으로 감소함. -> 모델수가 증가할수록 효과적
boosting
- 원리 : 모델링 결과(잔차)에 대한 패널티를 모델에 다시 반영함.
- 강한 학습기를 만들기 위해 가중 평균을 사용하는 일련의 약한 학습기를 반복적으로 개선
- 개별 구성원 모델보다 머 많은 용량을 가진 앙상블 모델 구성
- 분산보다 편향 감소에 효과적(과소적합에 효과적)
- 대표적인 알고리즘
- AdaBoost- Gradient Boosting Machine(GBM)
- XG boost : 병렬지원. level wise
- LGBM(Light GBM) : leaf wise로 속도가 빠르나 과적합 위험
- CatBoost : 범주형 자료에 효과적
- XG boost : 병렬지원. level wise
- Gradient Boosting Machine(GBM)
+)stacking
- train data set을 이용하여 n개의 서로 다른 모델링을 한 뒤 이를 활용하여 모델링을 한번 더 거치는 것.
- 즉 모델링을 통해 얻은 결과값이 다시 입력값으로 활용된다는 의미
ex) knn, random forest, decision tree 알고리즘을 사용하여 모델링을 통해 얻은 예측값을 logistic regression으로 최종모델링하여 결과를 얻음 - cv와 함께 사용
+)voting
Reference
[stacking]
1) https://techblog-history-younghunjo1.tistory.com/103
2) https://hwi-doc.tistory.com/entry/%EC%8A%A4%ED%83%9C%ED%82%B9Stacking-%EC%99%84%EB%B2%BD-%EC%A0%95%EB%A6%AC
3) https://huidea.tistory.com/35
[gradient boost]

데이터 분석/엔지니어링/ML에 관한 기록