머신러닝을 조금이라도 공부해본 사람들은 머신러닝을 하기전 학습데이터셋, 검증데이터셋, 테스트데이터셋으로 분류한다는 것을 알고 있을 것이다.
그런데 처음에는 검증데이터와 테스트데이터가 헷갈릴 수 있다.
Validation set vs Test set
-
Test set의 핵심 조건
- 성능평가는 모델튜닝을 위해서가 아닌 최종 결과 확인을 위해 최종적으로 1번 수행됨
- 학습하는데 사용하지 않은 데이터셋
- X값들에 대응하는 Y값이 존재하는 데이터셋 -
Validation set의 핵심 조건
- 성능평가를 통해 최종 모델을 선정하기 위해 여러번 사용되는 데이터셋
모델링 하는 두가지 타입
- Train- test
- 모델끼리 성능을 비교하지 않는 경우
- 특정 알고리즘 성능이 안정적으로 나와서 채택하여 운영하는 경우
- Train - validation - test
- 여러 모델(알고리즘)끼리 비교하는 경우
예시를 통해 이해하기(1)
a지점의 따릉이 일일 대여수 예측 모델링을 하는 상황에서 2022년 1월 1일~2022년 12월 31일까지의 일일 대여수를 알고 있다고 가정해보자.
Y값은 일일대여수.
범위는 2022/1/1~2022/12/31 (365개)이다.
이때 당일을 2022/12/31이라고 하고, 당일이 지나면 데이터 값은 새로 생기는 상황이라고 가정했을 때
케이스별로 나눠 생각해보자
(시계열 데이터관점에서 보지 말고 데이터셋 특징 이해를 위한 관점에서 단순하게 생각하자)
⭐ 인터넷에서 연습하는 타이타닉, 아이리스예제의 경우는 데이터셋의 갯수가 고정된 것이 일반적이지만, 실제 실무에서는 데이터의 갯수가 시간이 지날수록 증가하는 경우가 대부분이다.
CASE 1) train:test=1:0
가지고 있는 범위 전체를 학습시키고
앞으로 얻게 될 당일 이후의 날짜에 대한 데이터를 test로 취급하는 경우다.
하지만 테스트셋이 없을 수는 없고 이미 가지고 있는 데이터셋을 모두 train으로 사용했으므로 미래의 y값을 test로 사용해야한다.
한달치를 test set이라고 할 때, 1/1~1/31까지의 데이터를 test set으로 취급하는 경우는 1/31 이후에야 사용할 수 있다.
이해를 돕기 위한 극단적인 예시이고 보통 이런 케이스는 흔하지 않다.
CASE 2) train:test=3:1
- 주어진 데이터셋 내에서 train과 test를 나누는 경우이다. (비율은 임의)
- train을 2022/01/01~ 2022/9/30로
test를 2022/10/1~2022/12/31까지 나눠
9/30까지 학습시키고 10월부터의 예측치에 대해 성능평가를 한다(1회)
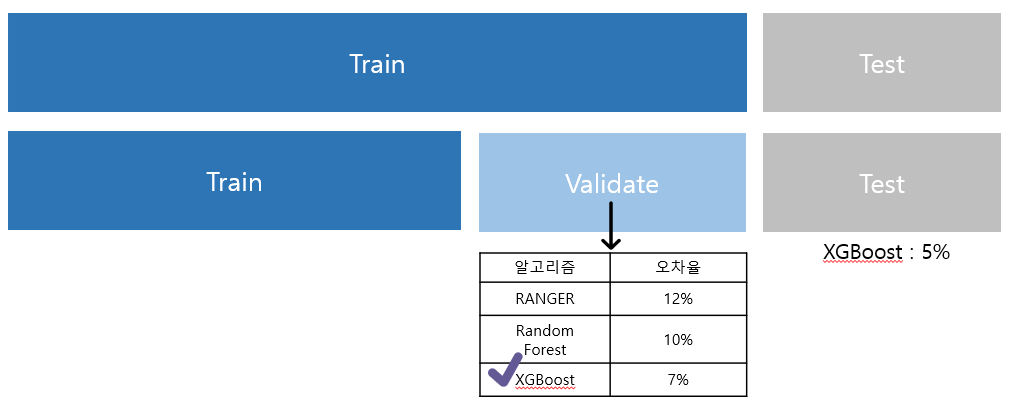
CASE 3) train:validation:test=10:1:1
- 학습데이터를 1월~10월,검증데이터를 11월,테스트데이터를 12월이라고 하자
- a알고리즘, b알고리즘, c알고리즘에 대해
각각 1~10월 값을 학습한다. - 11월 데이터 값에 대해 각각 예측값을 구한 뒤 성능을 측정한다.
- 가장 성능이 좋은 알고리즘을 선택한다.
- best알고리즘을 12월의 y값과 비교하여 최종 성능을 측정한다.
예시를 통해 이해하기(2)
- 더 쉬운 예시를 들어보자면
데이콘에 예측 모델링 대회에 참여했다고 하자.
필요한 train, test 데이터셋을 제공받았을 것이다.
여기서 모델링을 하기 위해선
train으로 제공받은 dataset을 train과 validation으로 나누어 validation set에서 성능을 계속 확인하며 튜닝 후 최선이라 판단되는 모델링 상태에서 test dataset을 넣어 결과를 제출하는 것이다.
POINT
- 모델링을 하면 기본적으로 train, test로 나누는데,
이때 test가 validation dataset으로 분류되며 모델을 test하는 역할을 하는 것인지, test set으로 분류되는 것인지 그 의미를 구분지을 수 있는 것이 중요하다.
참고하면 좋은 사이트

글 잘 봤습니다.