🖊️Abstract 🖊️
As language models become more powerful, training and evaluation are increasingly
bottlenecked by the data and metrics used for a particular task. For example,
summarization models are often trained to predict human reference summaries and
evaluated using ROUGE, but both of these metrics are rough proxies for what we
really care about—summary quality. In this work, we show that it is possible to
significantly improve summary quality by training a model to optimize for human
preferences. We collect a large, high-quality dataset of human comparisons between
summaries, train a model to predict the human-preferred summary, and use
that model as a reward function to fine-tune a summarization policy using reinforcement
learning. We apply our method to a version of the TL;DR dataset of Reddit
posts [63] and find that our models significantly outperform both human reference
summaries and much larger models fine-tuned with supervised learning alone. Our
models also transfer to CNN/DM news articles [22], producing summaries nearly
as good as the human reference without any news-specific fine-tuning.2 We conduct
extensive analyses to understand our human feedback dataset and fine-tuned
models.3 We establish that our reward model generalizes to new datasets, and that
optimizing our reward model results in better summaries than optimizing ROUGE
according to humans. We hope the evidence from our paper motivates machine
learning researchers to pay closer attention to how their training loss affects the
model behavior they actually want.
📖 세 줄 요약 📖
- Instruct GPT
- RHLF
- Human Feedback score
❔ 질문 ❔
왜 이 논문을 선택했나요?
ChatGPT 모델이 학습에 활용한 InstructGPT와 RLHF 방법론을 보면서 인간의 feedback이 모델에 직접 투입되었을 때 output과 학습에 어느정도의 영향을 미치는지 궁금했다.
어떤 문제를 해결하는 논문인가요?
언어모델 학습 시의 목적함수를 가능한한 우리가 원하는 행동을 포착할 수 있게 더 발전된 방법을 고안하는 것이다. 논문에선 인간의 선호가 가미된 데이터를 Reward model을 통해 학습시켜 인간에게 친숙하게 요악한다. 또 강화학습을 통해 이런 보상 score를 최대화하여 완성시켰다.
이를 통해 요약 task에서 인간이 요약한 것처럼 고품질의 모델 output을 얻는다.
왜 해당 문제를 푸는 것이 중요한가요?
요약 task에서 기존의 방법들은 인간이 만든 텍스트들로부터 가능도를 최대로하는 목적함수를 고려하였으나 이는 오류의 중요성(사실을 만들어내거나 동의어 집합에서 정확한 단어를 찾아내는 오류)를 제대로 파악해내지 못했다. 즉, 인간이 생성모델에게 생성하길 기대하는 것과 모델이 실제로 생성하는 것 사이의 괴리를 해결하고자 했다. 따라서 품질을 최적화시키는 것이 이 문제들을 극복할 중요한 키가 된다.
기존 연구가 어느정도로 이루어졌나요?
기존에도 human feedback을 요약 task에 학습시킨 연구가 있었고 보상 함수를 학습하는 강화학습에 기반을 두고 있었다. 하지만 온라인 상의 매너에 관해서만 학습하고 모델 자체가 데이터에서 특성을 추출해내는 것이 그쳤다고 한다. 또한 라벨러들과 연구자 사이에 요약 결과에 있어서 불일치를 보이기도 했다고 한다.
기존의 문제점을 해결할 수 있는 새로운 방향성을 잘 제안했나요?
human feedback을 거대 언어모델에 fine tuning 시키는 방법을 강화학습과 보상모델을 적절히 활용하여 해결했다. 인간이 만든 텍스트를 만들어내야한다는 사실에도 불구하고 기존에는 인간의 관점이 아닌 기계의 확률적 관점으로 텍스트를 생성해나간다는 한계점이 있었다. 이를 직관적인 해결법을 제시하여 성능을 비약적으로 향상시킨 점에서 앞으로 언어모델을 학습시킬 새로운 패러다임을 제시했다고 볼 수 있다.
또한 라벨러와 연구자 사이의 요약 결과의 선호도도 거의 동일하였고 더 큰 모델을 사용했으며 알고리즘적 변화도 주었다.
제안한 방식의 실험 또는 이론적 결과가 어떤가요?
Overview
- summary sample들을 추출해서 인간에게 보낸다. 여기서 Reddit post를 썼다고 한다.
- 인간 라벨러들이 post와 요약본들을 보고 점수를 매겨서 보상 모델을 학습시킨다.
- 로그 오즈를 예측한다고 한다.
- 이는 그림에서 보이다시피 두 개중 뭐가 더 좋은건질 알려준다는 것이다.
- 보상으로 로짓값이 나오고 강화학습, PPO 알고리즘을 통해 최적화시킨다.
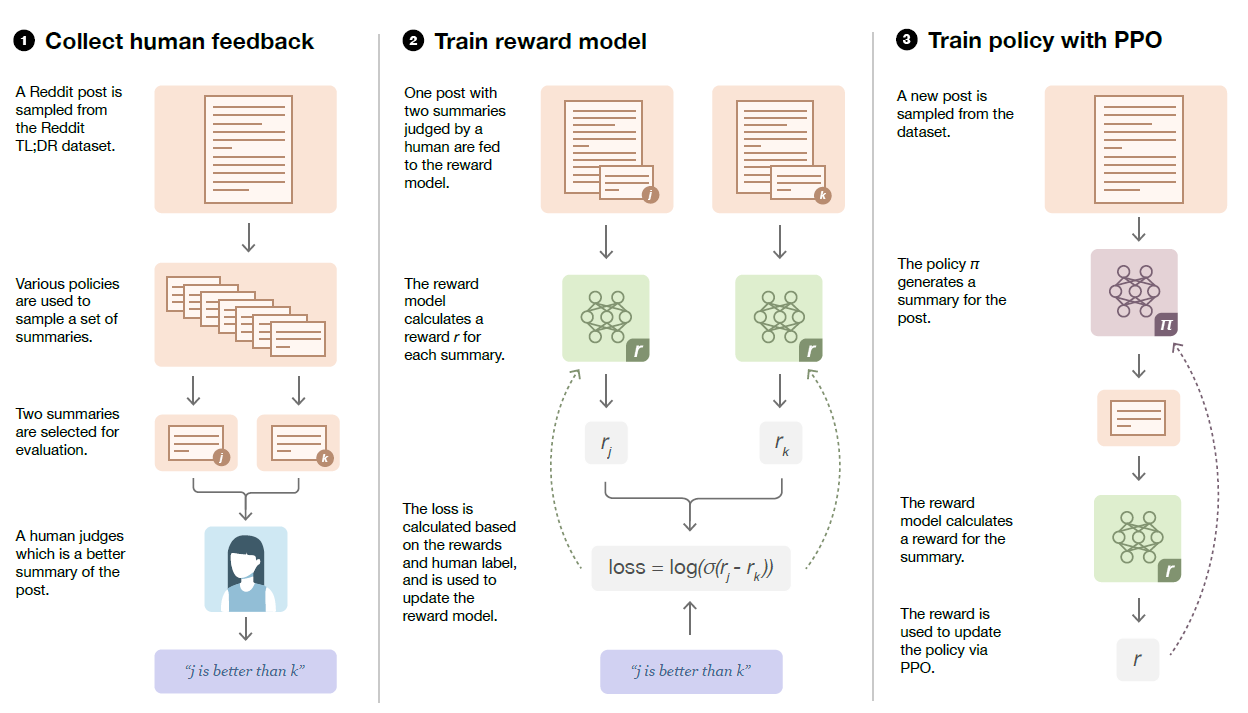
데이터셋
- TL;DR
- reddit에서 뽑아온 post들과 요약본(주인장이 해당 post를 직접 요약해논거)
- 토큰 수도 24~48로 제한하고(길이에 의한 효과 통제)
- 적절히 필터링도 거쳤다고 한다.
- CNN/DM
- CNN과 daily mail에 대한 데이터셋이다.
- 이건 직접 fine tuning 시켰더니 성능이 영 안좋아서 Reddit으로 학습 시킨 후 전이학습 시키는 형태로 확인해봤다고 한다.
- Task
- 요약본만 보고도 전체 내용을 얼마나 충실히 알 수 있는가를 기준으로 두었다.
- 라벨러들을 믿고 맡겼다고 한다. 물론 정말 상세한 가이드라인을 두고!
- 예시

Collecting human feedback
- 오프라인 환경에서 진행했다고 한다.
- researcher와 labeler 사이의 차이가 중요한 쟁점인 것 같다.
- labeler들을 지속적으로 직접 실시간 관리하고 자세히 알려줬다고 한다…ㅋㅋ
- 이런 노력들의 결과 대략 77% 정도 일치했다고 한다.
- 아무래도 연구자들이 원하는 human feedback을 labeler들이 이해못하고 잘못하면 연구 자체가 의미가 없어지니 특히 신경쓴 것 같다.
Model
- pre-trained model로 GPT-3인 1.3B와 6.7B 모델 썼다.
- zero-shot 이다.
- 베이스라인 모델을 TL;DR을 fine tuning해서 세우고 비교한다.
- Reward model
-
theta는 지도학습으로 출발한다.
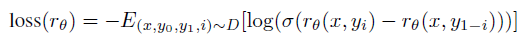
-
- Human feedback policies
- reward를 기반으로 PPO(Proximal Policy Optimization)를 최적화하도록 학습한다.
- 강화학습 모델 (RL)과 원래 지도학습 모델 사이의 KL divergence를 규제 텀으로 뒀다.
- entropy bonus : 요약 결과의 다양성
- reward 모델이 기존 fine-tuning된 모델과 너무 큰 차이가 생기지 않도록 조절
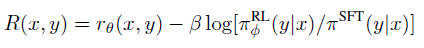
실험 결과
- 모델 사이즈가 커짐에 따라 성능도 향상되었고 베이스라인은 거뜬히 넘겼다.
- 길이에 따라서도 차이를 보인다. T5와 거의 유사한 성능을 보인다. (더 작다)
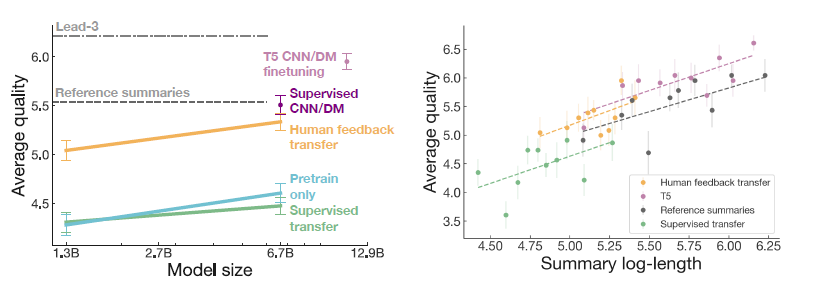
결론과 시사점을 적어주세요
- y축은 평가자가 human reference보다 모델 요약을 더 선호하는 비율로 RL과 RM을 사용하여 human feedback을 적용시킨 모델이 오히려 인간보다 더 좋아진다는 것을 보여준다.
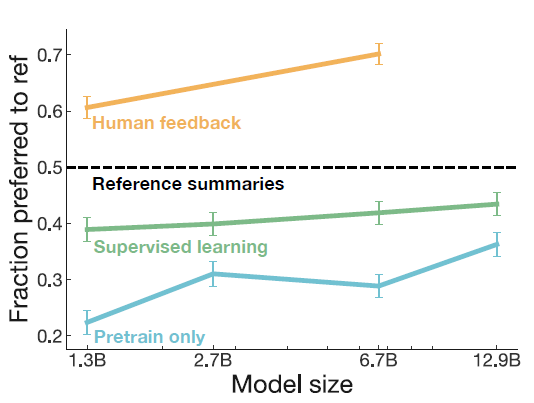
- 또한 RL 기반의 방법은 데이터 도메인이 변화해도 여전히 robust하게 적용된다는 장점을 가진다고 한다.
- 어찌보면 언어 모델을 학습시키는 것, 특히 생성 모델은 인간이 원하는 정보를 얻기 위해 만들기 때문에 지금까지 objective function이나 loss를 알맞지 않게 쓴 것일지도 모른다.
- 다만 학습한 데이터 중 인간혐오적인 발언이나 인종차별과 같은 포스트와 요약본이 있다면 그것에도 적용되어 문제가 생길 여지가 있다. 따라서 product에서 관리될 땐 미리 차단하거나 철저한 검증을 거친 학습이 이루어져야할 것이다.
- 기계에게 인간적인 해답, 언어를 직접 학습시켜주는 개념이 굉장히 신선했고, 성능 또한 월등히 잘 나오는 걸 보면 이제는 학습의 패러다임을 바꾸는 방법들이 등장할 타이밍이 아닐까 싶다.
같이 읽거나 알아보면 좋을 개념이나 논문 (키워드 + 링크)
- PPO algorithm
- RLHF
- GPT3
- ROUGE score
