[논문리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Paper Reviews
🖊️Abstract 🖊️
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications.
BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE score to 80.5% (7.7% point absolute improvement), MultiNLI accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute improvement) and SQuAD v2.0 Test F1 to 83.1 (5.1 point absolute improvement).
📖 세 줄 요약 📖
- Deep bidrectional transformer
- Masked Language Model & Next Sentence Predict
- SOTA & pre-training and fine tuning!
❔ 질문 ❔
왜 이 논문을 선택했나요?
나온지 꽤 됐지만 여전히 사랑받고 있는 BERT의 초기논문이 어떻게 나왔는지 궁금했다. Transformer based model의 양대산맥 중 하나인 BERT가 어떤 구조로 이루어져있고 GPT에 비해 좋은 점은 무엇인지, RoBERTa나 BART, PaLM을 읽기 위한 초석으로도 적절한 논문이라고 생각했다.
어떤 문제를 해결하는 논문인가요?
더 나은 LLM의 학습 방식을 제안한다. 단방향 모델이 가지는 attention mechanism의 한계를 양방향 transformer 구조로 context의 전체적인 정보를 활용한다.
왜 해당 문제를 푸는 것이 중요한가요?
Decoder 기반의 GPT는 sequential하게 단방향으로 학습하기 때문에 모든 토큰이 이전 토큰과의 attention만 계산해서 문장 수준의 task에선 sub-optimal이 된다고 한다. 전체 문장의 문맥을 더 잘 파악할 수 있고 GPT와 같이 다음 문장도 예측이 가능해지기 때문에 여러 방면에서 GPT에 비해 좋다.
기존 연구가 어느정도로 이루어졌나요?
기존에도 ELMo와 같이 양방향 attention 계산 구조는 존재했으나 단순히 단방향(왼쪽, 오른쪽) 두 layer를 concat하는 데에 그쳤다. 하지만 이럼에도 불구하고 SOTA를 세우는 등 많은 성능 향상을 보였다.
또한 다음 문장 후보 순위 메기기, 이전 문장 주어졌을 때 다음 문장의 left-to-right generating, denoising auto-encoder 파생방법 등이 존재했다.
기존의 문제점을 해결할 수 있는 새로운 방향성을 잘 제안했나요?
fine tuning 단에서 한계를 보였던 단방향 attention 대신 양방향 attention 구조를 MLM 구조를 활용하여 학습시키고 pair 문장 간 연결여부를 추가 학습시켜 NSP task(ex. QA) 까지 가능하게 만들어 간단하고도 강력한 모델을 만들었다.
제안한 방식의 실험 또는 이론적 결과가 어떤가요?
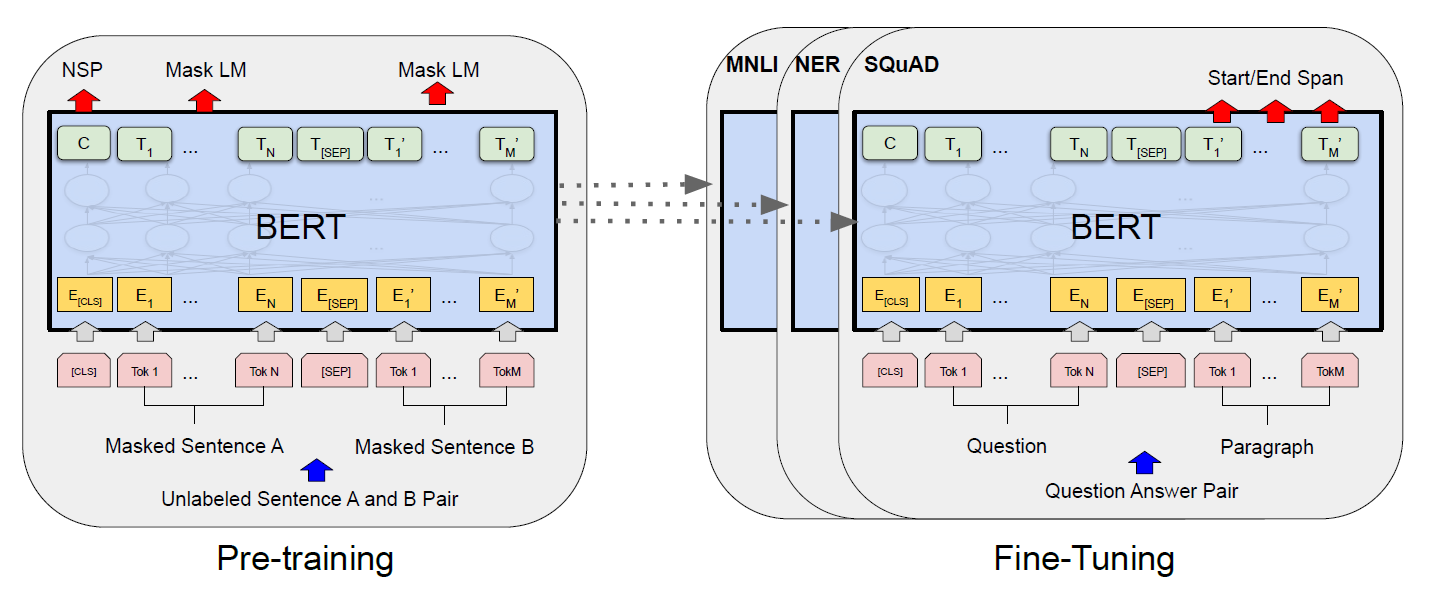
BERT(Bidrectional Encoder Representations from Transformers)
- 왼쪽이 pre-training, 오른쪽이 fine-tuning 구조이다.
- 항상 동일한 pre-trained model parameter가 서로 다른 task에 초기값으로 사용된다.
- 학습 자체는 unlabeld data로 학습되고 downstream task에선 label data로 학습된다.
Model Architecture
- multi-layer bidrectional Transformer encoder를 여러개 쌓은 형태다.
- BERT base : L=12, H=768, A=12, Total Parameters = 110M)
- BERT large : L=24, H=1024, A=16, Total Parameters=340M)
- L : layers(transformer block), H : hidden size, A : num of self-attention head
- GPT랑 비교하려고 파라미터 갯수 맞췄다고 한다 ㅋㅋ
- GPT보다 좋다는걸 상당히 강조한다.
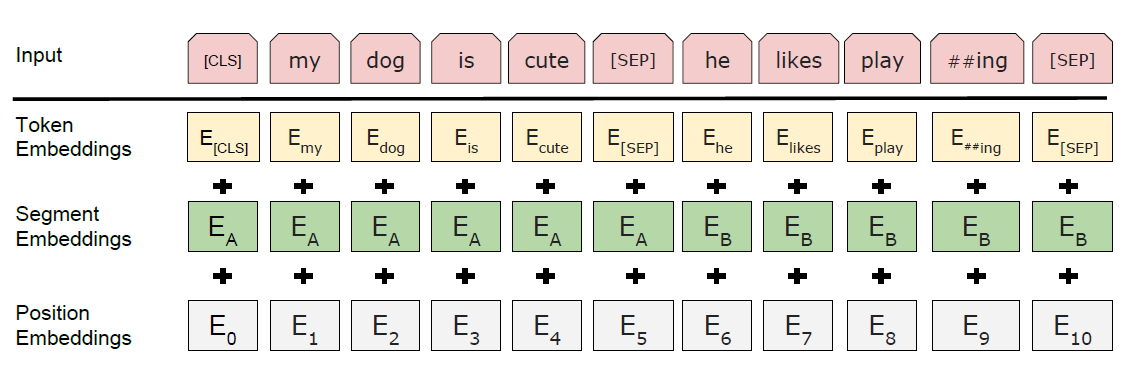
Input/Output Representations
- downstream task에 잘 적용하기 위해 단일 문장과 문장 순서쌍을 하나의 토큰 sequence로 분명히 표현해야 한다.
- WordPiece embedding
- CLS 토큰으로 시작, 이와 대응되는 hidden으로 문장 분류 task에 활용
- 문장 pair는 SEP 토큰을 통해 한 문장으로 이어짐.
- Segment Embeddings
- 두 문장을 구분해주는 부분
- Position Embeddings
- Transformer와 동일한 주기함수(sin, cos) 사용
Pre-training BERT
MLM과 NSP 두가지 unsupervised task를 활용하여 학습시켰다.
-
Masked Language Model
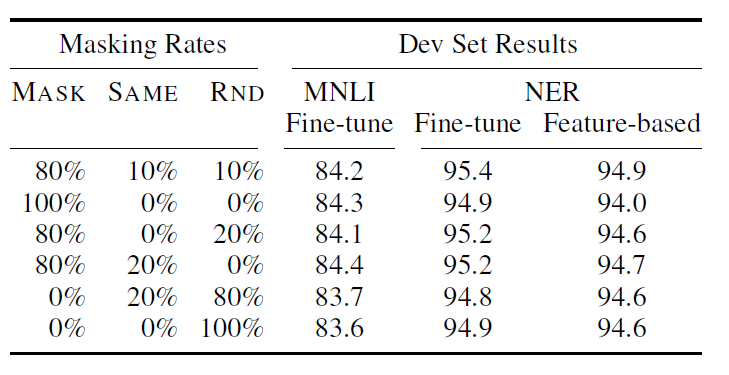
- 매 sequence 마다 15% 의 단어를 masking하고 이게 뭐였는지 맞추는 방식
- 그런데 fine-tuning 시에는 mask가 없기에 mismatch 발생! 이를 위해,
- 15% 중에 80%는 masking 그대로, 10%는 랜덤하게 다른 단어로 바꿔치기하고 나머지 10%는 그대로 둔다. 이 비율이 실험결과 제일 좋았다고 한다.
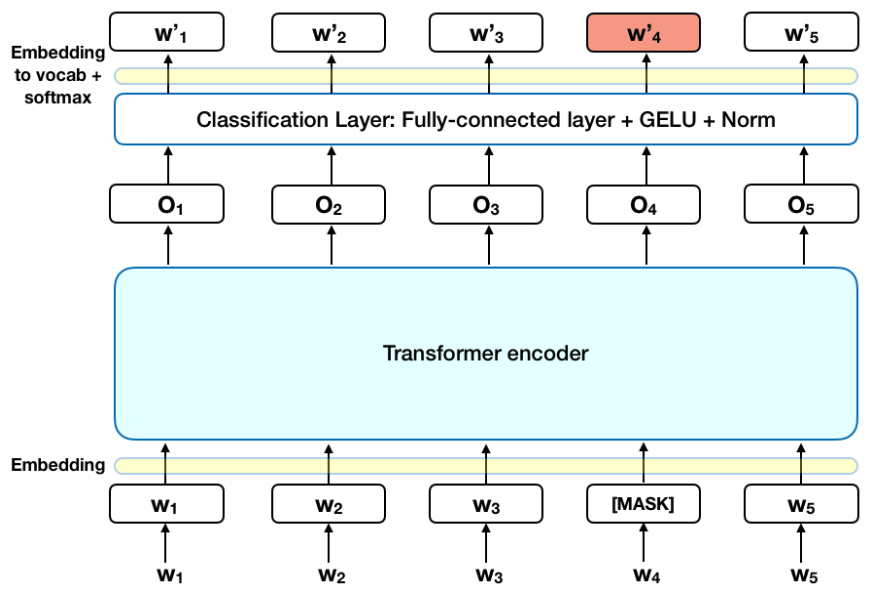
- 이렇게 하면 [MASK] token이 cross entropy loss를 통해 원래 token을 예측한다.
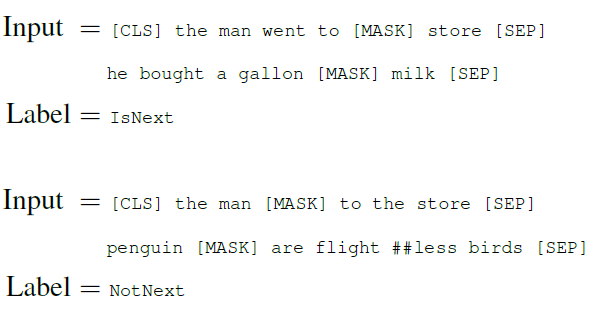
-
Next Sentence Prediction
- QA, NLI와 같이 문장 간 관계를 이해하는 것이 핵심인 task를 위해 추가
- binarized next sentence prediction
- pre-training example 선택 시 문장 A와 B가 있으면,
-
50%는 문장 A 다음에 실제 다음 문장인 B를(IsNext)
-
50%는 랜덤 문장 B를 (NotNext)를 고른다.
-
이를 맞추면서 학습한다.
-
- 위 BERT 그림에서 CLS 토큰 위치의 hidden에 있는 C가 NSP를 위한 것이다.
- 간단한 구조임에도 매우 효과적이였다고 한다.
-
Data
- BooksCorpus(800M words)
- English Wikipedia(2,500M words)
Fine-tuning BERT
- thanks for transformer’s self-attention mechanism!
- 많은 downstream task에 모델링 가능
- task마다 task-specific한 input을 받아 fine-tuning 진행
- sentence pairs in paraphrasing,
- hypothesis-premise pairs in entailment
- question-passage pairs in question answering
- a degenerate text-? pair in text classification or sequence tagging.
- output도 동일하다.
- 분류 문제면, label 갯수에 따라 classification layer를 붙이면 된다. 간단!
Experiments
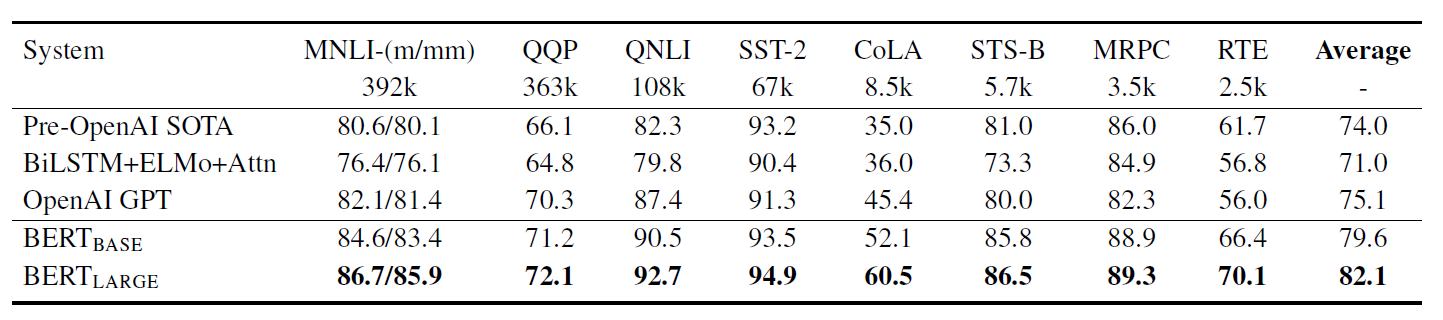
- GLUE(General Language Understanding Evaluation) benchmark
- 모든 task에서 기존 SOTA에 비해 높았다.
- 이는 BERT large 뿐만 아니라 base에서도 관찰되었다.
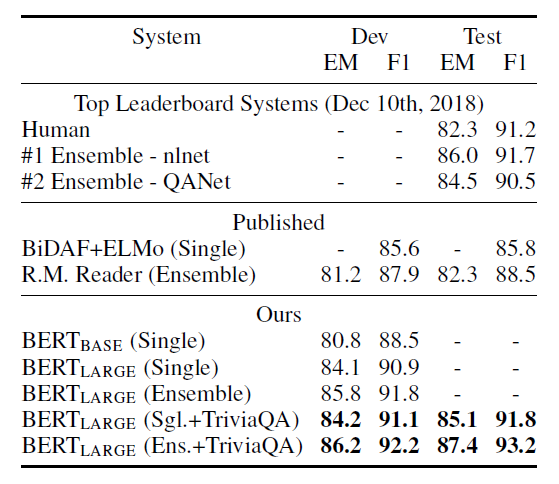
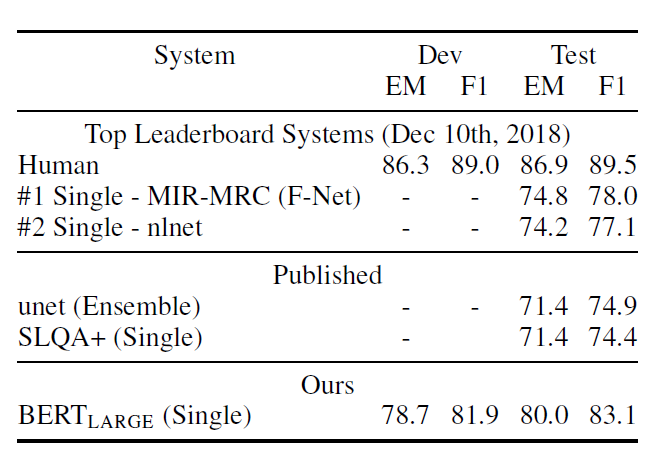
- SQuAD(Standford Question Answering Dataset) v1.1 & 2.0
- 역시나 기존보다 성능이 높았고 1.1의 경우 human 보다도 높았다.
결론과 시사점을 적어주세요
적은 자원(fine tuning)으로도 수많은 NLP task에 Large LM을 적용시켜 해결할 수 있는 지표를 제시해준 기념비적인 논문이다. 이 이후로 수많은 변형들과 최적화, 경량화 모델들이 나와 지금의 NLP model들이 탄생하게 되었다. deep bidirectional architecture를 처음 제시하고 이를 fine tuning에도 적용시킬 수 있는 방법을 간단하고도 강력히 제시하여 해결한 점이 인상깊었다.
같이 읽거나 알아보면 좋을 개념이나 논문 (키워드 + 링크)
- GPT
- attention is all you need
- ELMo
