🖊️Abstract 🖊️
The dominant sequence transduction models are based on complex recurrent or
convolutional neural networks that include an encoder and a decoder. The best
performing models also connect the encoder and decoder through an attention
mechanism. We propose a new simple network architecture, the Transformer,
based solely on attention mechanisms, dispensing with recurrence and convolutions
entirely. Experiments on two machine translation tasks show these models to
be superior in quality while being more parallelizable and requiring significantly
less time to train. Our model achieves 28.4 BLEU on the WMT 2014 Englishto-
German translation task, improving over the existing best results, including
ensembles, by over 2 BLEU. On the WMT 2014 English-to-French translation task,
our model establishes a new single-model state-of-the-art BLEU score of 41.8 after
training for 3.5 days on eight GPUs, a small fraction of the training costs of the
best models from the literature. We show that the Transformer generalizes well to
other tasks by applying it successfully to English constituency parsing both with
large and limited training data.
📖 세 줄 요약 📖
- attention 만 사용한 transformer 구조
- recurrent 연산이 없기 때문에 데이터 병렬화를 통한 연산 이득과 성능 개선
- 이후 BERT, GPT와 같은 LLM 발전으로 이어지는 시발점
❔ 질문 ❔
왜 이 논문을 선택했나요?
Transformer 구조의 시초가 되는 논문을 읽고 기본원리를 파악하기 위해서이다. 구현된 코드와 함께 읽어보며 논문에 코드로 구현되는 방법을 함께 공부하고 싶었다.
어떤 문제를 해결하는 논문인가요?
기존 언어모델 (RNN, LSTM, GRU 등..)들은 time sequence에 따라 output을 생성하기에 훈련 sample들을 병렬화하기 힘들어 computing problem이 있었고 긴 sequence를 처리하기 힘들었다. 이 논문에선 오직 attention mechanism만 활용하여 문장 전체를 한꺼번에 입력받아 병렬처리가 가능하게 했다. GPU활용도가 뛰어나며 성능역시 기존 모델들을 뛰어넘었다.
왜 해당 문제를 푸는 것이 중요한가요?
기존엔 sequence 연산이 순차적으로 이루어져야 하기에 병렬처리가 불가해 computing resource가 너무 많이 들었지만 attention과 position encoding을 통해 해결하고 성능과 연산능력 모두 올려 거대언어모델 학습의 기조를 마련하였다.
기존 연구가 어느정도로 이루어졌나요?
이미 attention machnism을 사용하거나 encoder-decoder 구조를 활용하는 방법은 제안되었고 사용되어 왔으나 기본은 RNN, LSTM, GRU와 같은 구조를 사용하고 부가적으로 ansemble하는 방법들이였다. attention만을 사용한 구조는 이 논문이 처음 제안하였다.
기존의 문제점을 해결할 수 있는 새로운 방향성을 잘 제안했나요?
encoder-decoder 구조의 seq2seq 모델을 attention 만을 이용하여 구현해서 LLM 학습으로의 확장가능성을 열어주었다. 또한 결과론적인 이야기이지만 encoder와 decoder 구조를 각각 따로 활용한 BERT와 GPT, 둘의 장점을 합친 BART와 같은 모델로 발전할 수 있는 방향도 제시해주었다.
제안한 방식의 실험 또는 이론적 결과가 어떤가요?
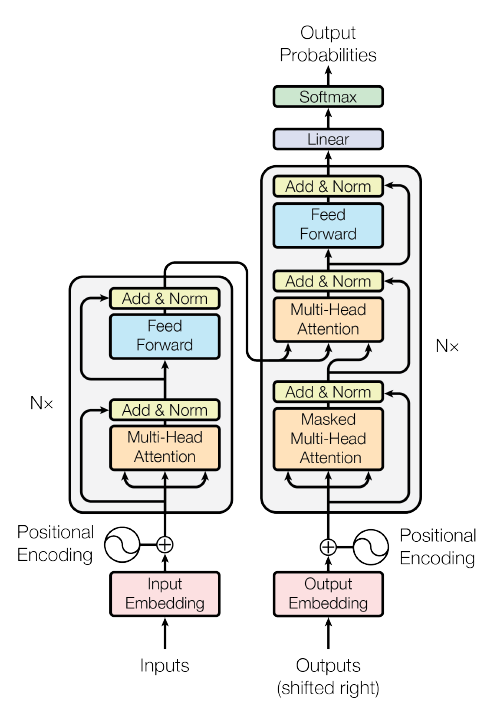
1) 모델 구조
- Encoder
- Feed Forward 부분과 Multi-Head Attention 부분으로 나뉘어짐
- 논문에선 6개의 동일한 layer를 쌓았음.
- Decoder
- encoder와 구조적으로 거의 비슷하지만 Masked Multi-Head Attention 부분이 추가.
- 이는 autoregressive property를 보존해야 하기에 현재시점 이후 미래의 정보를 masking 하기 위함이다. 미래를 미리 보면 치팅이다~
2) Attention
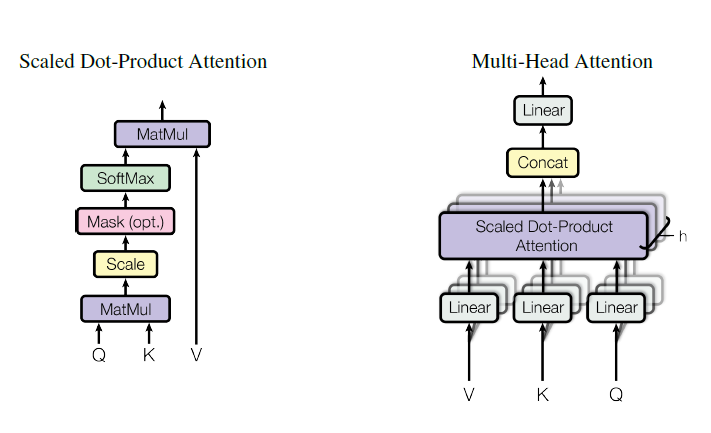
- Scaled Dot-Product Attention
-
Query, Key, Value
-
어떤 단어를 나타내는 Query와 문장 내 모든 단어드레 대한 vector를 stack해놓은 Key를 곱해서 attention score 를 만든다.
-
이는 query에 해당하는 단어와 문장 내 다른 단어와의 관계를 나타낸다.
-
루트 d_k로 scaling해주는 것은 softmax가 0 근처에서 gradient가 높고, magnitude에선 dot product 값이 커져서 매우 낮은 gradient를 가지기에 학습이 되지 않아서라고한다.
-
softmax를 통해 query 단어가 다른 단어들과 어느 정도의 correlation이 있는지를 확률 분포 형태로 만들고 value matrix와 dot product를 해줌으로써 기존 vector에 query와 key 간의 correlation 정보를 더한 vector를 만든다.
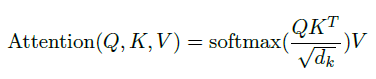
-
- Multi-Head Attention
- attention 한번 하는 것보단 여러번 하는 것이 낫다
- dk, dk and dv에 각각 linear projection을 통해 다른 값을 입력으로 하는 여러 개의 attention function을 만드는 것이 효율적이다.
- 논문에선 head를 8개를 사용했고 얘넨 attention 이후 concat 한다음 linear layer를 거쳐서 합쳐진다.

3) Attention의 종류
- encoder-decoder attention
- decoder에서 attention 이후 적용되는 layer
- query는 이전 decoder layer에서, key와 value는 encoder의 output에서 가져온다.
- decoder의 sequence vector들이 encoder의 sequence vector들과 어떤 correlation을 가지는지 학습한다.
- encoder contains self-attention layers
- encoder에서 사용되는 self attention
- query, key, value 모두 encoder에서 가져온다.
- 이전 layer의 모든 position의 attention 정보를 가져온다.
- 즉, 한 단어가 다른 단어들 중 누구와 correlation이 높은지 낮은지를 학습
- decoder contains self-attention layers
- encoder와 동일하나 autoregressive property 보존을 위해 현재 position 이전 벡터만 참고한다.
- 이를 위해 미래 정보에 해당하는 오른쪽 정보는 마스킹 (-♾️) 처리한다.
4) Position-wise Feed-Forward Networks
- attention layer와 함께 사용되는 fully connected feed-forward network가 사용된다.
- input layer, output layer의 차원은 512, inner layer는 2048
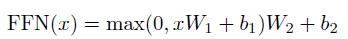
5) Embedding and Softmax
- input, output token을 embedding layer를 거쳐서 학습
- weight matrix를 서로 share 한다고 한다.
- softmax 에서 scaling 해주는 부분이 있다.
6) Positional Encoding
- Transformer의 주요 특징 중 하나이다.
- recurrent 연산이 없어져서 sequence 정보가 사라졌기에 position encoding을 더해준다.
- 논문에선 sin, cos 함수를 사용했는데 어느 시점에서든 관계없이 선형성을 보이기 때문이라고 한다.
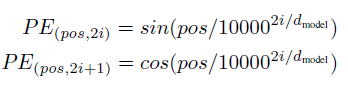
7) Training
- WMT 2014 English-German dataset (4.5M sentence pairs)
- WMT 2014 English-French dataset(36M sentences & 32000 word-piece vocab)
- 8 NVIDIA P100 GPUs
- Adam optimizer(0.9, 0.98)
- Residual Dropout(0.1), Label Smoothing(0.1)
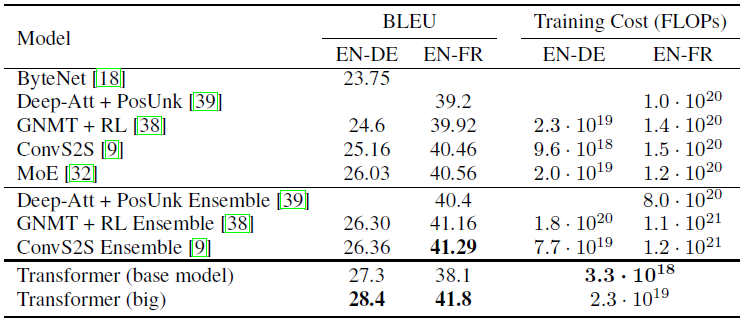
8) Experiments
- Machine Translation
- BLEU 측정 결과 SOTA를 찍었다.
- training cost 역시 낮다.
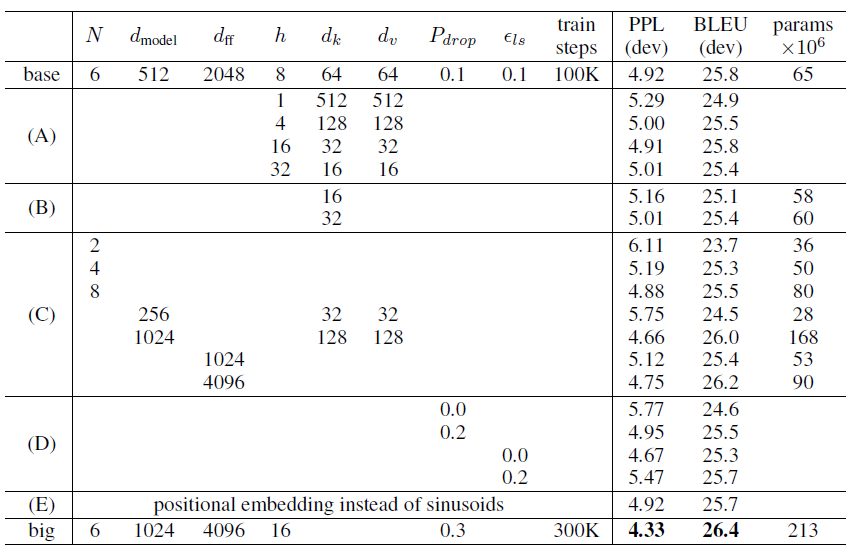
- Model Variations
- key size를 줄이면 안좋고 큰 모델이 성능이 좋으며, dropout이 도움된다.
결론과 시사점을 적어주세요
오직 attention만 사용해서 데이터 병렬화와 연산 감소, 성능 개선까지 이루어내며 Transformer라는 언어모델에서의 기념비적인 구조를 제안해낸 논문이다. 구현된 코드가 많으니 직접 코드와 논문을 함께 살펴보며 코드를 구현하는 방법과 구조를 이해하는 과정을 병행하기에 적절한 논문이다.
같이 읽거나 알아보면 좋을 개념이나 논문 (키워드 + 링크)
- BERT
- GPT
- Sequence to Sequence code
- BLEU
