[논문리뷰] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Paper Reviews
목록 보기
9/10
1. Introduction
- 지난 몇 년 동안 LLM의 post training은 중요한 구성 요소로 부상됨
- 추론 작업의 정확도
- 사회적 가치에 부합
- 사용자 선호도에 적응함과 동시에 사전 학습에 비해 상대적으로 최소한의 컴퓨팅 리소스만 필요
- OpenAI o1 시리즈가 최초 도입, CoT process의 길이를 늘림
- 다른 프로세스 기반 보상 모델, 강화학습, 몬테카를로 트린 검색 및 beam search 등의 다양한 방법들이 시도됨
- 하지만 o1에 필적하는 성능은 없음
- 순수 강화 학습만을 사용해 추론 능력 향상하고자 하였음
- 자기 진화에 초점을 맞춰 supervised data가 없이도 추론 능력을 개발할 수 있는 잠재력을 탐구함
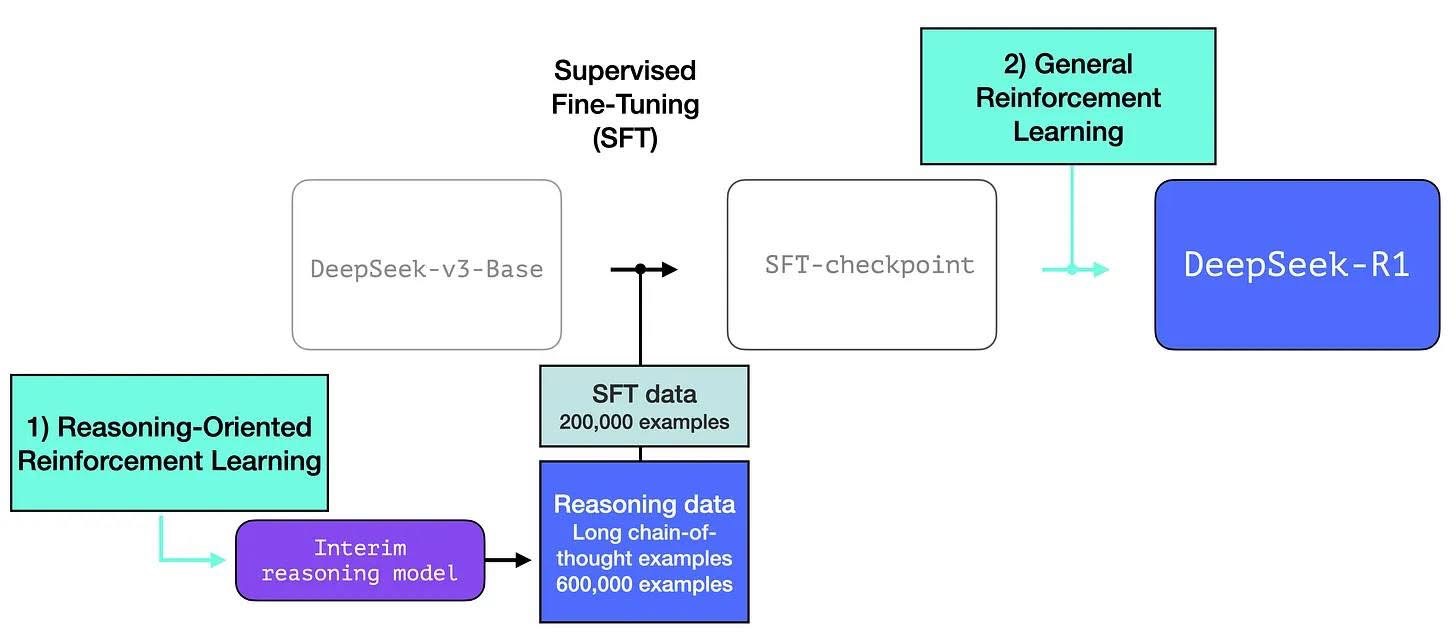
- DeepSeek-V3-Base 기본 모델 → GRPO RL 프레임워크 사용 → DeepSeek-R1-Zero
- 추론 벤치마크에서 뛰어난 성능을 보이게 됨
- 하지만 DeepSeek-R1-Zero는 가독성 저하, 언어 혼용 문제 직면
- DeepSeek-R1
- 수천 개의 cold start 데이터로 DeepSeek-V3-Base를 fine tuning
- DeepSeek-R1-Zero와 같은 추론 지향 RL 수행
- RL 프로세스에서 수렴에 가까워지면 RL 체크포인트에서 rejection sampling을 통해 새로운 SFT 데이터를 생성
- factual QA, writing, self-cognition과 같은 영역에서 supervised-data와 결합하여 재학습
- 모든 시나리오의 프롬프트를 고려하여 추가 RL 프로세스 거침
- OpenAI-o1-1217과 동등한 성능을 달성한 DeepSeek-R1 체크포인트를 얻음
- Distillaion 모델들도 있음
- Qwen2.5-32B를 기본 모델로 하면 DeepSeek-R1에서 직접 증류하는 것이 RL을 적용하는 것보다 더 낫다고 함.
- 대규모 모델에서 발견한 추론 패턴이 추론 능력을 향상 시키는데 중요함을 시사함
- 주요 기여
- 순수 RL 기반 추론 학습: SFT 없이 대규모 강화학습으로 모델의 Chain-of-Thought(추론 능력)을 발전시켜 DeepSeek-R1-Zero를 성공적으로 구현.
- 이중 RL + SFT 파이프라인: 두 단계의 RL과 SFT를 결합해 모델이 고차원적 추론과 일반적 대화 기능을 모두 학습하도록 설계.
- 추론 패턴 증류(Distillation): 대형 모델에서 습득한 고성능 추론 패턴을 소형 모델에 전수해, 단순 RL보다 뛰어난 성능을 얻음.
- 평가 결과 요약
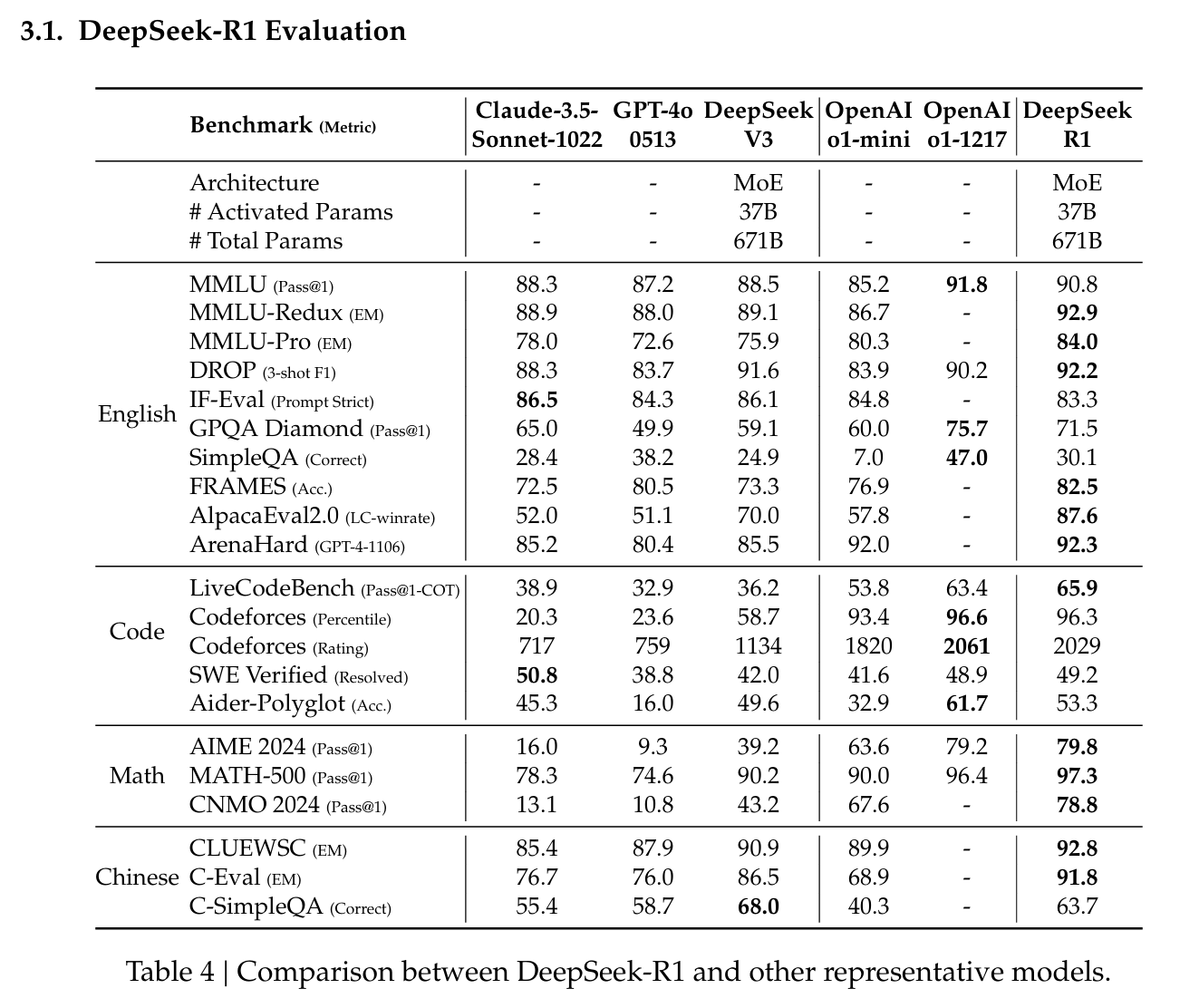
- 수리·논리 추론(AIME, MATH-500): AIME에서 Pass@1 기준 79.8%, MATH-500에서 97.3%로 상위권 모델과 대등한 성능.
- 코딩·엔지니어링: Codeforces Elo 2,029로 96.3%의 인간 참가자보다 우수하고, 실무 엔지니어링 과제에서도 DeepSeek-V3보다 개선된 결과.
- 지식 평가(MMLU 등): MMLU 90.8%, GPQA Diamond 71.5%로 DeepSeek-V3를 크게 앞지르며, 다른 비공개 모델과도 경쟁력 확인.
- 기타 창의적 과제: AlpacaEval 2.0(승률 87.6%), ArenaHard(92.3%) 등에서 우수한 성능으로 장문·비시험용 질의까지 안정적 대응 가능.
2. Approach
2.1 개요
- 기존 강화 학습 방법론들은 추론 작업에서 효과가 상당했으나 supervised data에 크게 의존함
- 순수 강화 학습 과정을 통해 self-evolution에 초점을 맞춰 supervised data 없이도 추론 능력을 개발할 수 있는 LLM의 잠재력을 살펴봄
2.2 DeepSeek-R1-Zero: base model + RL
2.2.1 Group Relative Policy Optimization(GRPO)
- 일반적으로 정책 모델(policy model)과 비슷한 크기의 비평가 모델(critic model)이 필요하지만, GRPO는 비평가 모델을 제거하고 대신 그룹 점수를 사용해 기준선을 추정
- 정책 모델: 최적의 행동 학습
- 비평가 모델 : 현재 정책이 얼마나 나은지 비교하고 평가하는데 사용, 정책 모델만큼 큰 경우가 보통 많아 계산 비용이 큼
- GRPO는 비평가 모델 사용 X, 과거 정책에서 샘플링된 여러 결과물()의 그룹 점수를 기반으로 기준선을 계산함
- 특정 작업에서 생성된 여러 결과물의 평균과 분산을 활용하여 각 결과물의 상대적 성과를 평가하는 방식임
- GRPO의 최적화 목표는 다음과 같은 수식으로 표현:
- 이 수식은 크게 두 부분으로 나뉨.
- 정책 업데이트: 정책 를 업데이트하면서 클리핑(clipping)을 통해 정책 변화가 너무 크지 않도록 제한
- KL-발산 제한: 현재 정책 가 기준 정책 와 너무 멀어지지 않도록 KL 발산을 추가
- 입력과 출력
- : 질문(입력)
- : 정책 모델이 생성한 i번째 출력
- : 한 그룹에 속한 출력 개수 (예: 5개의 출력)
- : 현재 정책 가 에서 를 선택할 확률
- : 과거 정책이 에서 를 선택할 확률
- Advantage () 계산
- : 의 보상
- : 그룹의 평균 보상
- : 그룹의 보상의 표준편차
- 그룹의 평균 보상과 비교해 의 상대적 성과를 계산
- 그룹 점수 기반으로 상대적 이득(advantage)을 평가하므로, 비평가 모델이 없어도 됨.
- Clipping
- 클리핑은 새로운 정책이 과거 정책과 너무 크게 달라지지 않도록 제한
- 은 클리핑 범위를 설정하는 하이퍼파라미터
- KL 발산 ()
- 현재 정책이 기준 정책()과 얼마나 다른지를 측정
- 너무 큰 차이가 나면 패널티를 부여하여 정책 업데이트를 안정적으로 만든다.
- 특징
- 보상(advantage) 극대화: 그룹의 평균보다 좋은 출력을 더 자주 선택하도록 정책을 업데이트
- 정책 변화 제한: 클리핑과 KL 발산으로 인해 정책이 급격히 변하지 않게 함
- 비평가 모델 제거: 계산 비용 감소.
- 그룹 점수 활용: 여러 출력 결과의 상대적 성과를 평가해 효율적 학습 가능.
2.2.2 보상 모델링
- 규칙 기반 보상 시스템
- 정확도 보상 : 정답 여부 평가, 결정론적 결과가 있는 수학 문제의 경우 정답을 지정된 형식으로 제공해야 하므로 규칙에 기반한 신뢰할 수 있는 정답 검증이 가능
- 형식 보상 : 와 태그 사이에 사고 과정을 넣도록 강제하는 형식 보상 모델 사용
- 신경망 기반 보상 모델 사용 안함
- 신경망 기반 보상 모델은 인공지능이 직접 보상을 계산하는 구조를 의미함
- reward hacking 문제나 재학습 비용이 크고, 학습 파이프라인이 복잡해진다는 이유
2.2.3 학습 템플릿
- 지침 준수하는 간단한 템플릿 사용
- 먼저 추론 프로세스를 생성한 다음 최종 답변을 생성하도록 함
- 의도적으로 구조적 형식으로 제약을 제한해서 반성적 추론을 의무화하거나 특정 문제 해결 전략을 장려하는 등의 콘텐츠 별 편견을 피함
- RL 프로세스 중에 모델의 자연스러운 진행을 정확하게 관찰할 수 있도록 하였음

2.2.4 Performance, Self-evolution, Aha Moment
- Performance
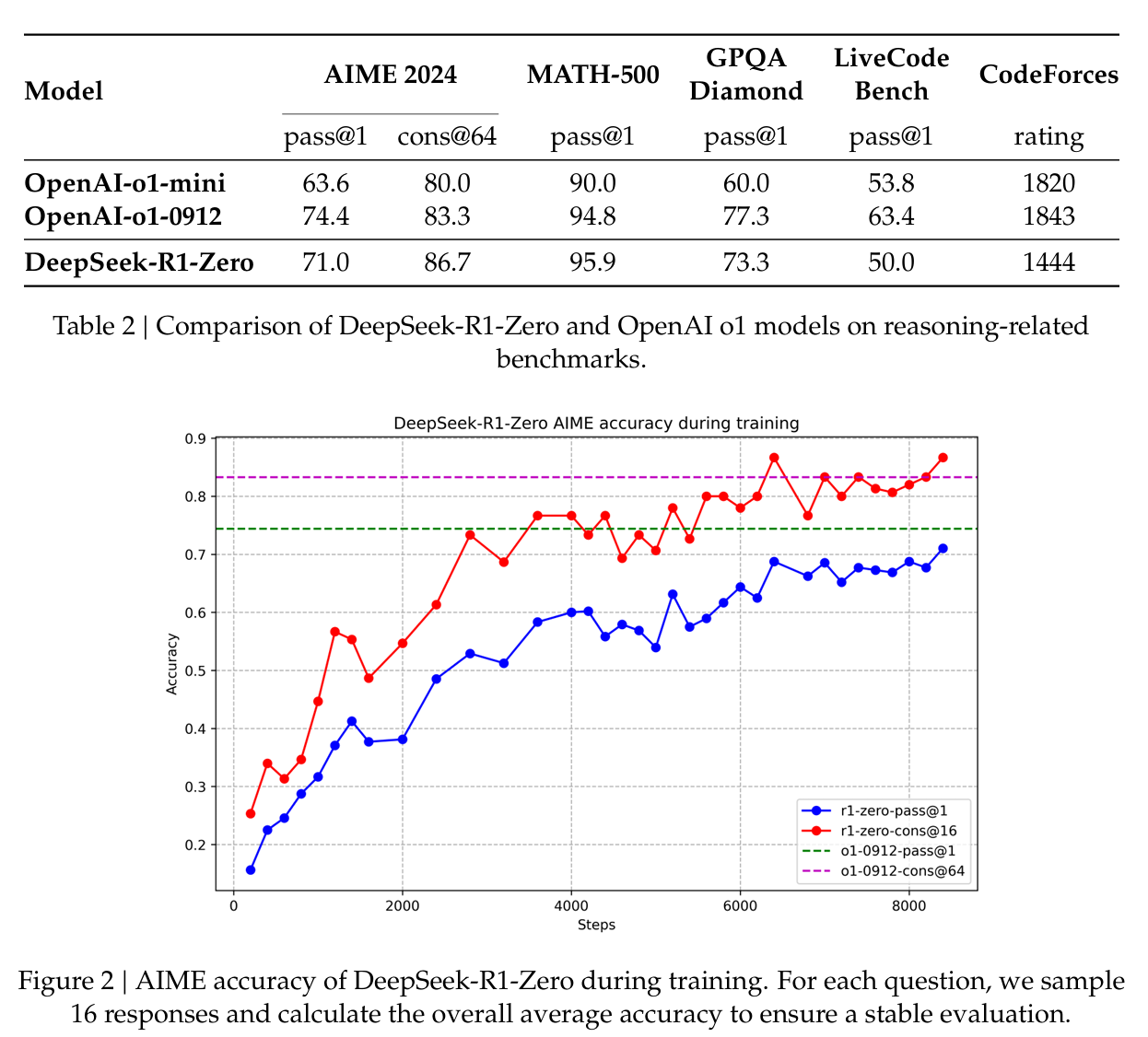
- DeepSeek-R1-Zero는 RL 훈련이 진행됨에 따라 꾸준하고 일관된 성능 향상을 보여줌
- AIME의 경우 평균 합격률이 초기 15.6%에서 71.0%로 크게 상승함
- 각 질문에 대해 16개의 응답을 샘플링하고 전체 평균 정확도를 계산하여 안정적으로 평가했다고 함
- Supervised fine tuning 없이도 강력한 추론 기능 달성 가능했음
- RL 만으로 효과적으로 학습하고 일반화할 수 있는 모델의 능력을 키울 수 있음을 시사함
- 다수결 투표 적용 시 더욱 강화 가능
- Self-evolution Process
- RL이 어떻게 모델을 자율적으로 추론 능력을 향상시킬 수 있는지를 보여줌
- base model에서 직접 RL을 시작함으로써 supervised fine-tuning 없이 모델 진행 상황을 면밀히 모니터링 가능함
- 이 접근 방식은 복잡한 추론 작업을 처리하는 능력 측면에서 시간이 지남에 따라 모델이 어떻게 진화하는지 명확하게 파악할 수 있음
- 놀라운 점은 test-time computation이 증가함에 따라 정교한 행동들이 출현한다는 것임
- ex 1) 이전 단계를 재검토하고 재평가하는 반성
- ex 2) 문제 해결을 위한 대안적 접근 방식의 탐색
- Aha Moment
- 학습하는 동안 관찰된 특히 흥미로운 현상은 아하 모멘트가 발생한다는 것임
- 보통 모델의 중간 버전에서 발생함
- 초기 접근 방식을 재평가하여 문제에 더 많은 사고 시간을 할당하는 방법을 학습함
- 모델의 추론 능력이 성장하고 있다는 증거일 뿐만 아니라 강화 학습이 어떻게 예상치 못한 정교한 결과로 이어질 수 있는지를 보여주는 매력적인 예시임

- 단점
- 가독성 저하 및 언어 혼용 문제로 어려움을 겪고 있음
- 추론 프로세스의 가독성을 높이고 공유하기 위해 인간 친화적인 cold start data로 RL을 활용하는 방법으로 DeepSeek-R1을 고려하였음
2.3 DeepSeek-R1: 콜드 스타트를 사용한 강화 학습
- DeepSeek-R1-Zero의 결과에서 두 가지 질문이 생김
- 소량의 고품질 데이터를 콜드 스타트로 통합하여 추론 능력을 더욱 향상시키거나 융합을 가속화할 수 있을까?
- 명확하고 일관된 CoT를 생성할 뿐만 아니라 강력한 일반화 성능을 보여주는 사용자 친화적인 모델을 어떻게 훈련시킬 수 있을까?
2.3.1 콜드 스타트
- RL 학습의 초기에 불안정한 콜드 스타트 단계 방지를 위해 RL actor로서 fine tuning을 위한 약간의 긴 CoT 데이터를 구축 및 수집함
- 긴 CoT를 예시로 몇 개의 샷으로 프롬프팅
- 모델에 직접 프롬프트하여 반영하고 검증을 통해 상세한 답변 생성
- DeepSeek-R1-Zero 출력을 읽기 쉬운 형식으로 수집하는 방법
- 인간 주석가의 후처리를 통해 결과 개선하는 방법
- DeepSeek-V3-Base를 RL의 시작점으로 fine-tuning함
- 가독성
- 기존의 한계는 콘텐츠가 읽기 적합하지 않았음.
- 여러 언어가 섞여있거나 답변 강조를 위한 마크다운 형식이 부족했음.
- 콜드 스타트 데이터에는 각 응답의 끝에 요약을 포함, 적합하지 않은 응답을 필터링하는 읽기 쉬운 패턴으로 설계
- |special_token|<reasoning_process>|special_token|
- 추론은 쿼리에 대한 CoT이고 요약은 추론 결과를 요약함
- 잠재력
- human priors를 통해 콜드 스타트 데이터의 패턴을 신중하게 설계하여 기존에 비해 더 나은 성능을 냄
- 반복 학습이 추론 모델에 더 나은 방법이라고 믿는다고 한다.
2.3.2 추론 중심의 강화 학습
- 콜드 스타트 데이터로 DeepSeek-V3-Base를 fine-tuning 한 후 DeepSeek-R1-Zero와 동일한 대규모 강화 학습 훈련 프로세스를 적용
- 코딩, 수학, 과학, 논리 추론과 같이 잘 정의된 문제와 명확한 해결책을 포함하는 추론 집약적인 작업에 대해서 모델의 추론 능력을 향상시키는데 중점을 두었음
- 언어 혼용 문제 완화를 위해 RL 훈련 중 언어 일관성 보상을 도입함
- CoT에서 목표 언어 단어의 비율로 계산
- 성능은 약간 저하되지만 인간의 선호도와 일치하여 가독성을 높여주었음
- 추론 작업의 정확도와 언어 일관성에 대한 보상을 직접 합산하여 최종 보상 구성
2.3.3 거부 샘플링(Rejection Sampling)과 감독 미세 조정(Supervised Fine-tuning)
- 추론 중심의 RL이 수렴되면 그 체크포인트를 활용해 다음 라운드를 위한 SFT 데이터 수집
- 이 단계에서는 다른 영역의 데이터를 통합하여 글쓰기, 롤플레잉 및 기타 범용 작업에서의 모델 기능을 위해 데이터를 생성해서 모델을 미세 조정함.
- 추론 데이터
- 데이터 생성 방법:
- Rejection Sampling: 강화학습(RL) 훈련 중 생성된 체크포인트에서 샘플링하여 데이터 생성.
- 잘못된 데이터는 걸러내고, 올바른 샘플만 채택.
- 추가 데이터 통합: 일부는 생성형 보상 모델(generative reward model)을 사용해 평가.
- 예: DeepSeek-V3 모델에 정답과 예측을 입력해 적합성을 판단.
- 데이터 필터링:
- 혼합 언어(mixed languages) 사용된 응답.
- 지나치게 긴 문단.
- 복잡한 코드 블록.
- 위 항목을 제거하여 데이터 품질 개선.
- Rejection Sampling: 강화학습(RL) 훈련 중 생성된 체크포인트에서 샘플링하여 데이터 생성.
- 결과:
- 최종적으로 약 60만 개의 Reasoning 데이터를 수집.
- 비추론 데이터
- 데이터 유형:
- 쓰기(Writing), 사실 기반 QA(Factual QA), 자기 인식(Self-cognition), 번역(Translation) 등.
- 데이터 생성 방법:
- DeepSeek-V3 파이프라인을 사용해 데이터 생성.
- 간단한 작업(예: "hello")에는 CoT를 제공하지 않음.
- 기존 DeepSeek-V3의 SFT(Supervised Fine-Tuning) 데이터셋 재사용.
- 결과:
- 최종적으로 약 20만 개의 Non-Reasoning 데이터를 수집.
2.3.4 모든 시나리오를 위한 강화 학습
- 모델을 인간 선호도에 맞추기 위해 2차 강화학습(secondary reinforcement learning) 단계 수행.
- 2차 강화학습 단계에서는 추론 능력을 유지하며, 모델의 유용성과 무해성을 강화하기 위해 다양한 보상 신호와 데이터를 사용
- 보상 신호(reward signals)와 다양한 프롬프트 분포를 사용해 모델을 훈련.
- 추론 데이터(Reasoning Data) : 수학, 코드, 논리적 추론 등과 같은 도메인에서 규칙 기반 보상(rule-based rewards) 사용.
- DeepSeek-R1-Zero에서 사용된 방법론을 그대로 적용.
- 일반 데이터(General Data)
- 보상 모델(reward models)을 사용해 복잡하고 미묘한 상황에서의 인간 선호도를 학습.
- DeepSeek-V3 파이프라인 기반의 훈련 데이터와 프롬프트 분포 사용.
- 유용성(Helpfulness) 및 무해성(Harmlessness) 평가
- 유용성 평가
- 최종 요약(summary)에 중점
- 요약의 유용성과 관련성을 강조.
- 추론 과정에 불필요한 간섭을 최소화.
- 무해성 평가
- 응답 전체(추론 과정 + 요약)을 평가:
- 잠재적인 위험 요소, 편향, 유해한 콘텐츠를 탐지하고 제거.
- 유용성 평가
2.4 Distillation: 추론 기능으로 소규모 모델 역량 강화
- 위의 80만 개 샘프롤 Qwen, Llama와 같은 오픈소스 모델을 직접 fine-tuning 함
- 간단한 증류 방법이 소규모 모델의 추론 능력을 크게 향상시킴
- RL 도 적용하면 모델 성능 크게 향상시킬 수 있으나 여기에선 증류 기법의 효과만 입증함
- 나머지는 커뮤니티에게 맡김 ㅎㅎ
3. 실험
1. 벤치마크
- 추론 중심 벤치마크:
- MMLU, MMLU-Redux, MMLU-Pro, C-Eval, CMMLU, GPQA Diamond, SimpleQA, C-SimpleQA, FRAMES.
- 코드 및 수학 중심 벤치마크:
- SWE-Bench Verified, LiveCodeBench, Codeforces, AIME 2024, CNMO 2024, MATH-500.
- 오픈 엔드 생성 평가:
- AlpacaEval 2.0, Arena-Hard: GPT-4-Turbo-1106을 판별 기준으로 사용.
2. 평가 프롬프트
- 표준 벤치마크:
- SimpleQA, GPQA Diamond 등은 simple-evals 프레임워크를 사용.
- MMLU-Redux: Zero-Eval 프롬프트 사용 (제로샷 설정).
- 몇몇 데이터셋(MMLU-Pro, C-Eval 등): 기존의 few-shot 프롬프트를 제로샷으로 변형.
- 코드 및 수학 데이터셋:
- HumanEval-Mul: 8개 주요 프로그래밍 언어(Python, Java, C++ 등) 지원.
- LiveCodeBench: CoT 형식으로 평가.
- Codeforces: Div.2 문제와 전문가 제작 테스트 케이스로 평가.
3. 베이스라인 모델
- 기준 모델:
- DeepSeek-V3, Claude-Sonnet-3.5-1022, GPT-4o-0513, OpenAI-o1-mini, OpenAI-o1-1217.
- 오픈소스 모델:
- QwQ-32B-Preview와 성능 비교.
4. 평가 방법
- 출력 길이 제한:
- 최대 32,768 토큰.
- 평가 지표:
- Pass@1: k개의 응답 중 첫 번째 응답의 정확도를 계산.
- Sampling 설정: 온도(temperature) = 0.6, top-p = 0.95 사용.
- AIME 2024: 다수결(majority vote)을 통한 cons@64 결과도 제공.
- 평가 방식:
- Greedy decoding은 반복률이 높아지므로, 샘플링 기반 평가를 채택.
3.1 DeepSeek-R1 평가
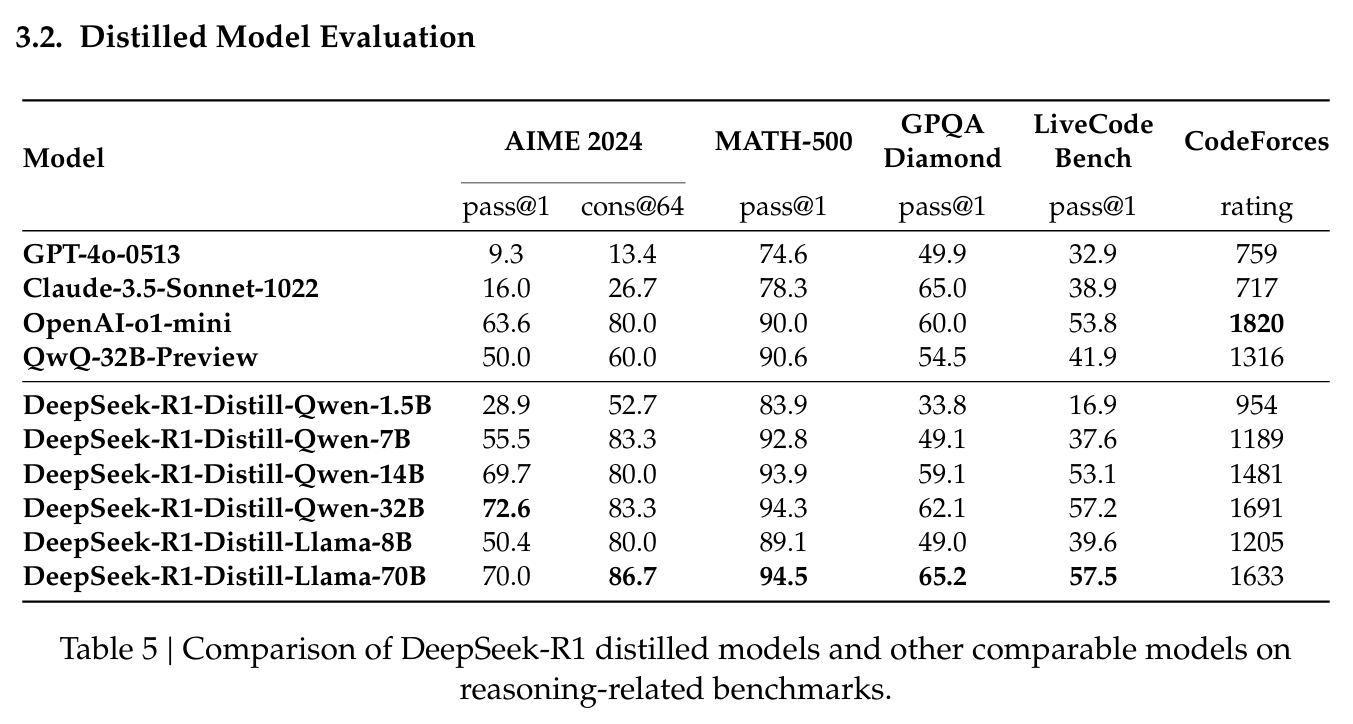
3.2 Distillation 모델 평가
4. Discussion
1. Distillation vs Reinforcement Learning (RL)
- 실험:
- Qwen-32B-Base 모델에 대해 수학, 코드, STEM 데이터를 사용한 대규모 RL(10k 스텝) 실험.
- 결과:
- RL로 훈련한 DeepSeek-R1-Zero-Qwen-32B는 QwQ-32B-Preview와 비슷한 성능 달성.
- 그러나, DeepSeek-R1에서 Distillation한 DeepSeek-R1-Distill-Qwen-32B가 모든 벤치마크에서 월등히 우수한 성능을 보임.
- 결론:
- Distillation의 장점:
- 강력한 대형 모델을 Distillation하면 소형 모델도 뛰어난 성능을 발휘 가능.
- 경제적이고 효율적.
- RL의 한계:
- 소형 모델이 RL만으로 Distillation 성능에 도달하려면 막대한 계산 자원이 필요하며, 실현 가능성이 낮음.
- 향후 과제:
- 인공지능의 경계를 넘어서기 위해서는 더 강력한 기본 모델과 대규모 RL이 필요.
- Distillation의 장점:
2. 실패 사례
Process Reward Model (PRM)
- 아이디어: 추론 단계별로 모델을 가이드하기 위해 과정 기반 보상 모델 사용.
- 문제점:
- 세부적인 추론 단계를 명확히 정의하기 어렵다.
- 각 중간 단계의 정답 여부를 판별하는 것이 복잡하다.
- 보상 해킹(reward hacking) 문제:
- 모델이 잘못된 방식으로 보상을 극대화하려 함.
- 재훈련 비용 증가:
- 보상 모델을 자주 업데이트해야 하므로 학습 파이프라인이 복잡해짐.
- 결론: PRM은 일부 활용 가능하나, 대규모 RL에는 적합하지 않음.
Monte Carlo Tree Search (MCTS)
- 아이디어: AlphaGo/AlphaZero에서 영감을 받아, 답변을 작은 단계로 나누어 체계적으로 탐색.
- 문제점:
- 탐색 공간이 너무 큼:
- 체스와 달리, 토큰 생성은 탐색 공간이 기하급수적으로 증가.
- 노드 확장을 제한하면 지역 최적해(local optima)에 갇힐 위험.
- Value 모델의 한계:
- 각 단계의 품질을 평가하는 Value 모델 훈련이 어려움.
- AlphaGo의 원리를 토큰 생성에 적용하기 어려움.
- 탐색 공간이 너무 큼:
- 결론:
- 사전 학습된 Value 모델과 함께 사용하면 추론 성능 향상이 가능하나, 반복적으로 성능을 높이기 위한 자가 탐색(self-search)은 큰 도전 과제.
5. 결론, 한계점 및 미래 계획
결론
- DeepSeek-R1-Zero: 순수한 강화학습(RL) 접근법을 사용하며 초기 데이터를 활용하지 않고도 다양한 작업에서 강력한 성능 달성.
- DeepSeek-R1: 초기 데이터(cold-start data)와 반복적인 RL 미세조정으로 더 강력한 성능을 발휘.
- OpenAI-o1-1217과 유사한 성능 달성.
- Distillation:
- DeepSeek-R1에서 생성된 80만 개의 학습 샘플을 사용해 소형 모델을 미세조정.
- 결과적으로 소형 모델(DeepSeek-R1-Distill-Qwen-1.5B)이 GPT-4o와 Claude-3.5-Sonnet을 수학 벤치마크에서 능가.
한계점
- 일반적 기능 부족:
- DeepSeek-V3에 비해 함수 호출, 멀티턴 대화, 복잡한 역할 수행, JSON 출력 등에서 부족.
- 언어 혼합 문제:
- 영어와 중국어에 최적화되어 있어 다른 언어 쿼리를 처리할 때 영어로 응답하는 문제가 발생.
- 프롬프트 민감성:
- Few-shot 프롬프트는 성능 저하를 유발.
- 제로샷 프롬프트를 사용해 문제를 명확히 서술하고 출력 형식을 지정해야 최적 성능 발휘.
- 소프트웨어 엔지니어링 작업:
- 장시간 평가로 인해 소프트웨어 작업에 대규모 RL이 충분히 적용되지 못함.
- DeepSeek-R1은 소프트웨어 엔지니어링 벤치마크에서 DeepSeek-V3 대비 큰 향상을 보여주지 못함.
미래 계획
- 일반 기능 강화:
- 긴 Chain-of-Thought(CoT)를 활용해 함수 호출, 복잡한 역할 수행 등을 개선.
- 언어 혼합 문제 해결:
- 다국어 쿼리 대응을 개선해 영어와 중국어 외의 언어에서도 적절한 언어를 사용하도록 업데이트.
- 프롬프트 최적화:
- 프롬프트 엔지니어링을 통해 민감성을 줄이고 제로샷 설정에서 성능 최적화.
- 소프트웨어 엔지니어링 개선:
- 소프트웨어 데이터를 활용한 Rejection Sampling과 비동기 평가(asynchronous evaluations)를 도입해 RL 효율성 향상.
6. 출처

hi!