개요
- Google I/O 2025에서 새롭게 공개한 온디바이스 지향 gemma 모델
- 개인정보 보호와 오프라인 실행에 초점
- 텍스트, 오디오, 이미지, 영상 등 다중 모달 처리 지원
- 현재는 텍스트랑 이미지만
- Per-Layer Embeddings 기술과 MatFormer 모델 아키텍쳐를 통해 적은 RAM으로 대규모 모델 구동이 가능해짐
- 원본은 5B(Gemma-3n-E2B-it-int4)와 8B(Gemma-3n-E4B-it-int4)
- 메모리 오버헤드는 2B, 4B 모델과 유사함
- 각각 2GB와 3GB의 동적 메모리 사용량으로 동작 가능함
- Per-Layer Embeddings 이건 아직 논문으로나 보고서로 밝혀진 바가 없는 기술임
- 높은 multi-lingual 성능을 갖추며 실제 환경에서 실시간 상호작용 경험을 지원함
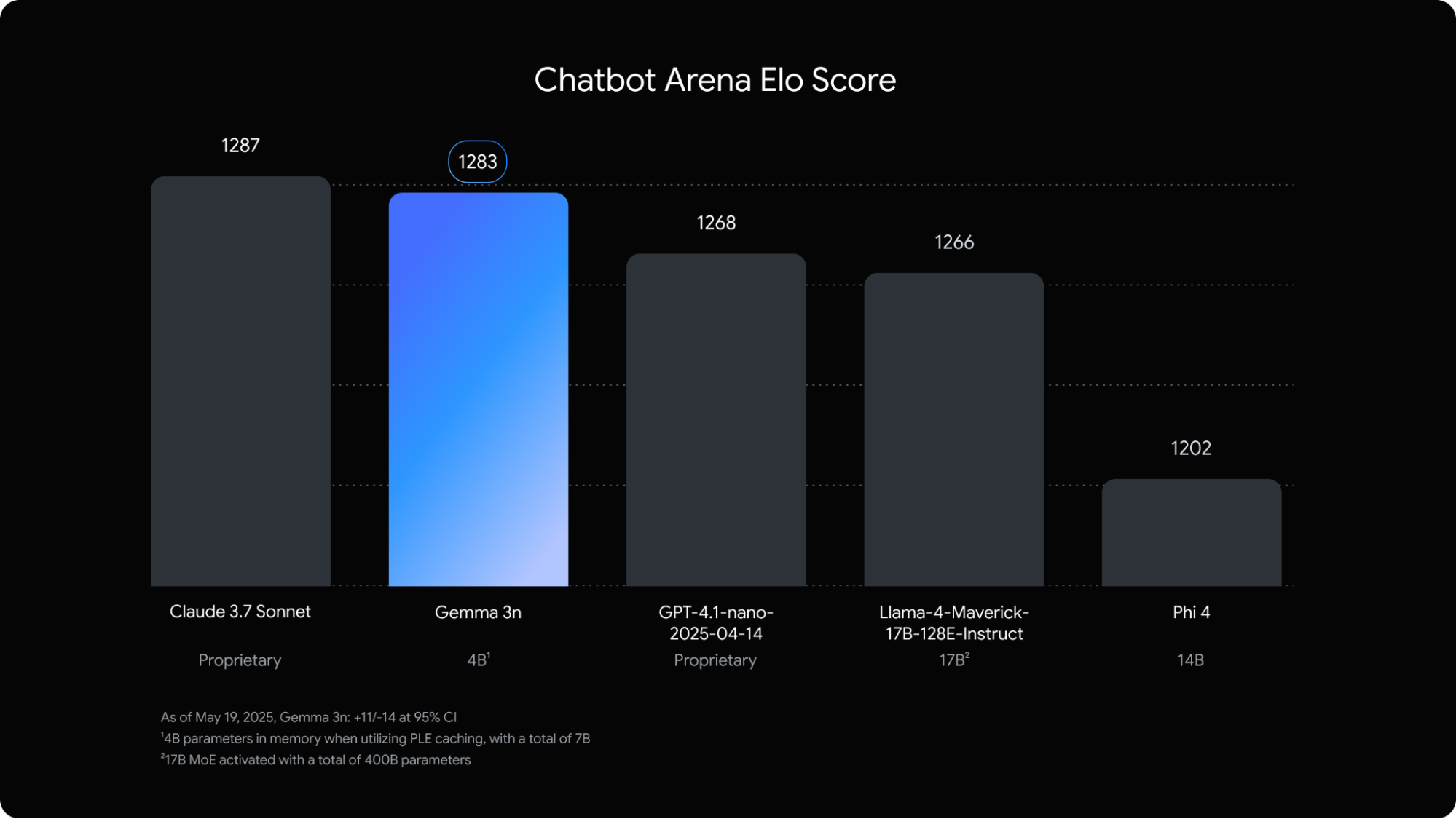
- 무려 claude 3.7 sonnet과도 비슷한 성능을 보인다고 주장함
- 상업 라이센스
주요 기능
- 오디오 입력
- 음성 인식, 번역, 오디오 데이터 분석을 위해 사운드 데이터를 처리
- 시각적 및 텍스트 입력
- 다중 모드 기능을 사용하면 시각, 소리, 텍스트를 처리하여 주변 세계를 이해하고 분석하는 데 도움
- PLE(Pre-Layer Embeddings) 캐싱
- 레이어별 임베딩(PLE) 매개변수를 빠른 로컬 저장소에 캐싱하여 모델 메모리 실행 비용을 줄임
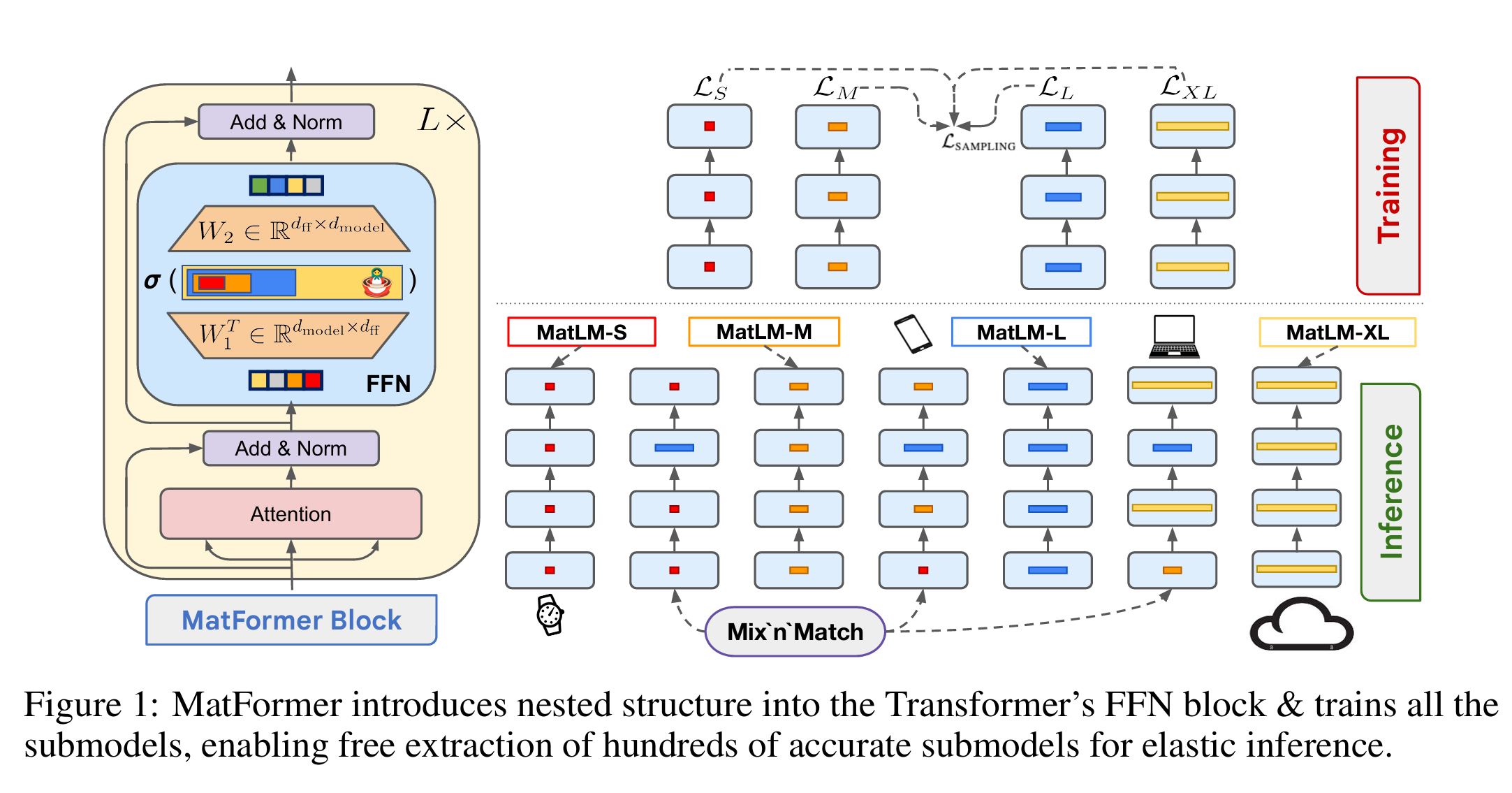
- MatFormer 아키텍처
- Matryoshka Transformer 아키텍처는 요청 별로 모델 매개변수를 선택적으로 활성화하여 컴퓨팅 비용과 응답 시간을 단축함
- 별도의 모델 배포 없이, 품질 및 지연시간의 균형을 즉시 맞출 수 있는 mix’n’match 기능 제공
- 조건부 매개변수 로딩
- 모델에서 시각 및 청각 매개변수 로딩을 우회하여 로드되는 매개변수의 총 개수를 줄이고 메모리 리소스를 절약
- 다양한 언어 지원
- 140개 이상의 언어로 훈련된 다양한 언어 능력.
- 32K 토큰 컨텍스트
- 모바일 용 경량 모델치고 매우 훌륭한 컨텍스트
모델 구조
- 텍스트, 시각, 오디오, 레이어별 임베딩 총 네 가지 주요 그룹으로 매개변수 그룹을 나눔
- E2B 모델을 표준으로 실행 시에 50억개 이상이 로드됨
- 매개변수 스킵 및 PLE 캐싱 기술 사용 시 약 20억개의 매개변수를 효과적으로 메모리에 로드하여 운영 가능함
- 기기 성능이나 작업 요구사항에 따라 모델 기능을 확장하거나 축소 가능
1. Pre-Layer Embedding Caching(PLE Caching)
- 모델 실행 중 각 모델 계층의 성능을 향상시키는 데이터를 생성하는데 사용되는 계층별 임베딩 매개변수
- 모델의 운영 메모리 외부에서 별도로 생성, 고속 저장소에 캐시된 후 각 계층이 실행될 때 모델 추론 프로세스에 추가될 수 있음
- 리소스 소비를 줄임과 동시에 품질 향상시키기 위해 고려됨
2. MatFormer architecture
- 하나의 큰 모델 내에 중첩된 작은 모델들을 포함하는 마트료시카 트랜스포머(MatForemr 모델) 을 차용
- 중첩된 하위 모델은 요청에 응답할 떄 주변 모델의 매개변수를 활성화하지 않고 추론에 사용될 수 있음
- 더 작은 핵심 모델만 실행하여 컴퓨팅 비용, 응답 시간 및 에너지 사용량을 줄일 수 있음
- 매개변수 선택해서 2B에서 4B 사이의 중간 크기 모델로 조립도 가능함
2-1. structure
MatFormer에서 “내포된(중첩된)” FFN(Feed-Forward Network) 블록 구조는, 말 그대로 하나의 FFN 은닉층을 여러 크기의 작은 블록들로 나누되, 이 블록들이 서로 포함(⊂) 관계를 이루도록 설계한 것입니다. 아주 쉽게 비유하자면, 마트료시카(러시아 인형)처럼 작은 인형이 큰 인형 안에 들어있는 구조를 떠올리시면 됩니다.
-
기존 FFN 블록은 이랬어요
- 한 층의 FFN은, 입력 차원 에서 시작해 은닉 차원 를 거쳐 다시 로 돌아오는 두 개의 선형 변환(그리고 비선형 활성화 함수)으로 구성됩니다.
- 즉,여기서 , , 는 GELU 같은 활성화 함수입니다.
-
MatFormer가 추가한 아이디어
- 이 개의 은닉 뉴런(또는 채널)을, 크기가 점점 커지는 개의 “중첩된” 블록으로 나눕니다.
- 예를 들어 라 하면, 은닉 뉴런 개수 를이렇게 4단계로 쪼개는데, 예시로 등이 쓰입니다.
-
블록 간 포함 관계
- 블록 은 첫 개의 뉴런만,
- 블록 는 첫 개의 뉴런(즉 1번 블록의 뉴런 + 그다음 뉴런들)만,
- …
- 블록 는 전체 개의 뉴런을 사용합니다.
- 따라서 가 성립합니다.
-
수식으로 보면
여기서 는 의 “윗부분” 행만 취한 부분행렬을, 는 마찬가지로 첫 열만 취한 부분행렬을 뜻합니다.
-
왜 이렇게 하나요?
- 훈련 중에 이 4가지(혹은 가지) 블록을 골고루 학습시키면, 훈련 후에는 하나의 “보편 모델” 안에서 원하는 만큼 작은 모델(sub-model)을 추출만으로 꺼내 쓸 수 있습니다.
- 예를 들어 “전체 절반 규모”로 쓰고 싶으면 블록만, “최대 규모”로 쓰고 싶으면 전체 뉴런 블록()만 각각 골라 쓰는 식이죠.
- 이렇게 하면 추가 훈련 없이 여러 크기의 모델을 자유롭게 얻을 수 있어, 다양한 추론(latency/비용) 제약에 탄력적으로 대응할 수 있습니다.
-
정리하자면….
- FFN 은닉층의 뉴런을 “작은 것→큰 것” 순으로 겹쳐 놓은 블록으로 나눕니다.
- 가장 작은 블록은 가장 중요한 뉴런만, 큰 블록일수록 작은 블록을 포함해 점점 더 많은 뉴런을 씁니다.
- 덕분에 훈련된 단일 네트워크에서 원하는 크기만큼 꺼내 쓸 수 있어, 추가 훈련 없이 여러 크기의 모델을 자유자재로 활용할 수 있습니다.
2-2. Training
MatFormer은 한 번에 여러 크기의 모델을 따로따로 훈련시키는 대신, 하나의 큰 모델 안에 숨어 있는 개의 “중첩된(submodel)”을 무작위로 골라가며 훈련합니다.
- 매 스텝마다
- 중 하나의 서브모델 을 균등 확률로 뽑고,
- 해당 모델의 출력 과 정답 사이의 손실 을 계산한 뒤,
- 그 손실에 대해 표준 그래디언트 최적화를 수행합니다.
- 왜 이렇게 하냐면?
- 서브모델들은 서로 포함 관계로 묶여 있기 때문에, 큰 모델을 업데이트하면 그 안에 포함된 작은 모델들도 함께 갱신됩니다.
- 결과적으로 매 스텝마다 뽑힌 하나의 서브모델만 명시적으로 학습하지만, 모두가 골고루 여러 번 업데이트되어 까지 차례로 정확도가 높아집니다.
- 훈련이 끝나면, 추가 비용 없이 개의 서로 다른 크기의 모델을 한 번에 얻는 셈입니다.
2.3 Mix’n’Match
훈련 후에는, 본래 명시적으로 최적화한 개의 서브모델뿐 아니라, 조합만으로도 수백 가지 다른 크기의 모델을 뽑아낼 수 있습니다. 이 절차가 바로 Mix’n’Match입니다.
- 기본 추출
- 층(layer)마다 같은 번째 블록 를 골라 쌓으면 모델이 되고,
- 예를 들어 전부 만 쓰면 중간 크기 서브모델이, 전부 만 쓰면 최대 크기 모델이 됩니다.
- Mix’n’Match – 층별로 다르게 골라보기
- 하지만 이보다 더 재미있는 건, 층마다 다른 를 섞어 쓰는 것!
- 예컨대 앞 8개 층엔 , 뒤 8개 층엔 을 쓰면, 원래 훈련하지 않은 “중간중간” 크기의 서브모델이 만들어집니다.
- 최적 서브모델 고르는 법 (Heuristic)
- 가능한 조합이 엄청나게 많지만, “계단처럼 한 번에 하나씩만 조금씩 크기 늘리기” 전략이 잘 작동합니다.
- 즉, 층이 깊어질수록 쓰는 블록의 크기도 최소한 전 층 크기보다 같거나 커지도록 골라서,
- 예를 들어 처럼 완만하게 바꾸는 방식이, 처럼 갑자기 확 커졌다가 좁아지는 것보다 성능이 좋았습니다.
- 이 간단한 “기울기 최소한 증가” 전략으로도, 복잡한 NAS(Neural Architecture Search) 못지않은 Pareto-optimal 해를 거의 추가 비용 없이 찾을 수 있었습니다.
이렇게 MatFormer는
- 훈련 중엔 무작위로 서브모델을 골라 골고루 키우고,
- 추론 때는 층별 블록을 조합해 더 많은 모델을 꺼내 쓸 수 있게 함으로써,
- 추가 훈련 비용 없이 다양하고 효율적인 모델 활용을 가능하게 합니다.
2.4 Deployment
- 정적 워크로드(static)
- 상황 예시
- 예를 들어, 어떤 서비스가 40B 파라미터 규모의 Llama-2 모델을 지연(latency) 예산상 감당할 수 있지만, 실제로 호스팅 가능한 모델은 34B뿐인 경우를 생각해보세요.
- 일반적으로 “40B 모델을 처음부터 훈련”하려면 막대한 연산(4.8×10²³ FLOPs)이 필요하지만, 이미 훈련된 34B 모델(4.08×10²³ FLOPs)과 70B 모델(8.4×10²³ FLOPs)이 있을 때는, 40B 모델을 얻기 위해선 결국 새 훈련이 필수였습니다.
- MatFormer의 해결법
- MatFormer를 쓰면, 추가 훈련 비용 없이(0 FLOPs 추가) 정확도가 가장 뛰어난 40B 규모의 서브모델을 뽑아 쓸 수 있습니다.
- 방법은 간단히, Mix’n’Match 히어리스틱으로 사전에 정의된 서브모델들(S, M, L, XL) 중에서 “40B에 가장 가까운” 조합을 찾아 쓰는 것 뿐입니다.
- 즉, 배포 전에 컴퓨트 자원과 입력 난이도가 일정하다면, 이 제약 하에서 가장 정확한 서브모델을 손쉽게 선택할 수 있습니다 .
2. 동적 워크로드 (Dynamic Workloads)
- 상황 예시
- 서비스 트래픽이나 요청의 난이도가 실시간으로 변할 때, 또는 GPU/CPU 자원이 동적으로 할당ㆍ회수될 때
- “난이도 높은 쿼리에는 대형 모델을, 간단한 쿼리엔 소형 모델을” 매번 다르게 적용하고 싶다면
- MatFormer의 해결법
- ‘유니버설 모델’(XL) 하나만 서버에 올려둡니다.
- 매 토큰(Token)·쿼리(Query)마다 Mix’n’Match를 통해 최적의 서브모델(S, M, L, XL 중에서 층별로 블록을 조합)만 실시간으로 꺼내 씁니다.
- 예: 앞부분에는 중간 크기 블록(M)을, 뒷부분에는 대형 블록(L)을 섞어 쓰는 식으로.
- 이렇게 해도 출력 행동(behavior)이 일관성 있게 유지되기 때문에,
- 서로 다른 서브모델 간 예측 차이(드리프트)가 거의 없고,
- 예측 안정성이 중요한 speculative decoding 같은 기술과도 잘 어울립니다.
- 또, 모든 서브모델이 모델 가중치를 공유하므로 메모리 상에서 여러 개 모델을 같이 띄울 때도 효율적입니다 .
- 요약
- 정적 워크로드: 한 번에 한 가지 제약(지연·메모리)에 가장 잘 맞는 모델을 Mix’n’Match로 골라 쓰면, 추가 훈련 없이도 “맞춤형” 모델을 바로 배포할 수 있습니다.
- 동적 워크로드: 서비스 조건이 변할 때마다 “하나의 유니버설 모델” 안에서 실시간으로 최적 서브모델을 꺼내 사용해, 자원 활용과 예측 일관성 모두를 잡을 수 있습니다.
- 이로써 MatFormer는 추가 훈련 비용 없이(zero-cost) 고정된 제약에도, 그리고 실시간 변화에도 유연하고 효율적으로 대응할 수 있는 진정한 의미의 “Elastic Deployment”를 실현합니다.
성능
| Weight Quantization | Backend | Prefill (tokens/sec) | Decode (tokens/sec) | Time to first token (sec) | Model size (MB) | Peak RSS Memory (MB) | GPU Memory (MB) |
|---|---|---|---|---|---|---|---|
| dynamic_int4 | CPU | 118 | 12.8 | 9.2 | 4201 | 3924 | 193 |
| dynamic_int4 | GPU | 446 | 16.1 | 15.1 | 4201 | 5504 | 3048 |
실험 구성 (Experiment Setting)
- 모델 구조: MatFormer 기반의 디코더 전용 언어 모델(MatLM)을 g=4개의 중첩된 크기(FFN 비율 0.5, 1, 2, 4)로 훈련하여 각각 {S, M, L, XL} 서브모델을 얻음. MatLM-XL은 ‘유니버설’ 모델 역할을 함.
- 비교 대상: 동일 아키텍처의 별도 훈련된 일반 Transformer 언어 모델(Baseline-{S,M,L,XL}), 그리고 OFA·DynaBERT를 같은 언어 모델링 환경에 적응시킨 모델들과 비교.
- 평가 지표: 개발 셋 상의 로그 퍼플렉시티(validation loss)와 25개 영어 태스크(예: LAMBADA, TriviaQA 등)에서의 평균 정확도(one-shot accuracy)를 측정 .
주요 결과 요약 (Key Results)
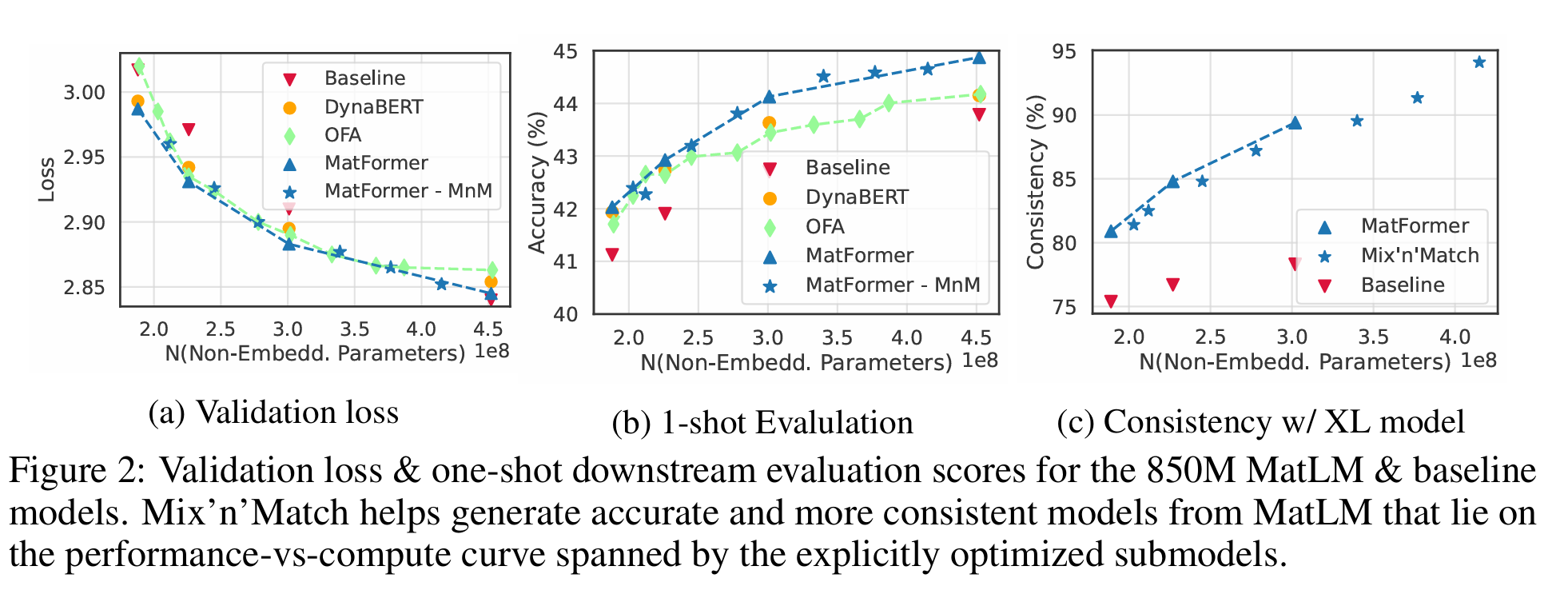
- Validation Loss & 1-Shot Accuracy
- MatLM의 모든 서브모델(S–XL)이 대응 크기의 Baseline 모델을 뛰어넘는 낮은 손실과 높은 정확도를 보임.
- DynaBERT, OFA 대비도 일관되게 우수한 성능 곡선(loss-vs-compute)을 나타냄 .
- Mix’n’Match 효과
- 훈련된 4가지 서브모델 이상의 ‘중간 크기’ 모델들을 층별 조합만으로 추가 훈련 없이 꺼내 쓸 수 있으며, 이들이 성능-대-연산곡선상에 최적 포인트를 메꾸는 것을 확인 .
- Speculative Decoding 속도 향상
- 393M(S) 드래프트 + 850M(XL) 검증기 조합으로 추론 시, Baseline 대비 최대 10%의 가속, MatLM 기반 시 최대 14% 가속(Attention 캐시 공유 시 16%까지) .

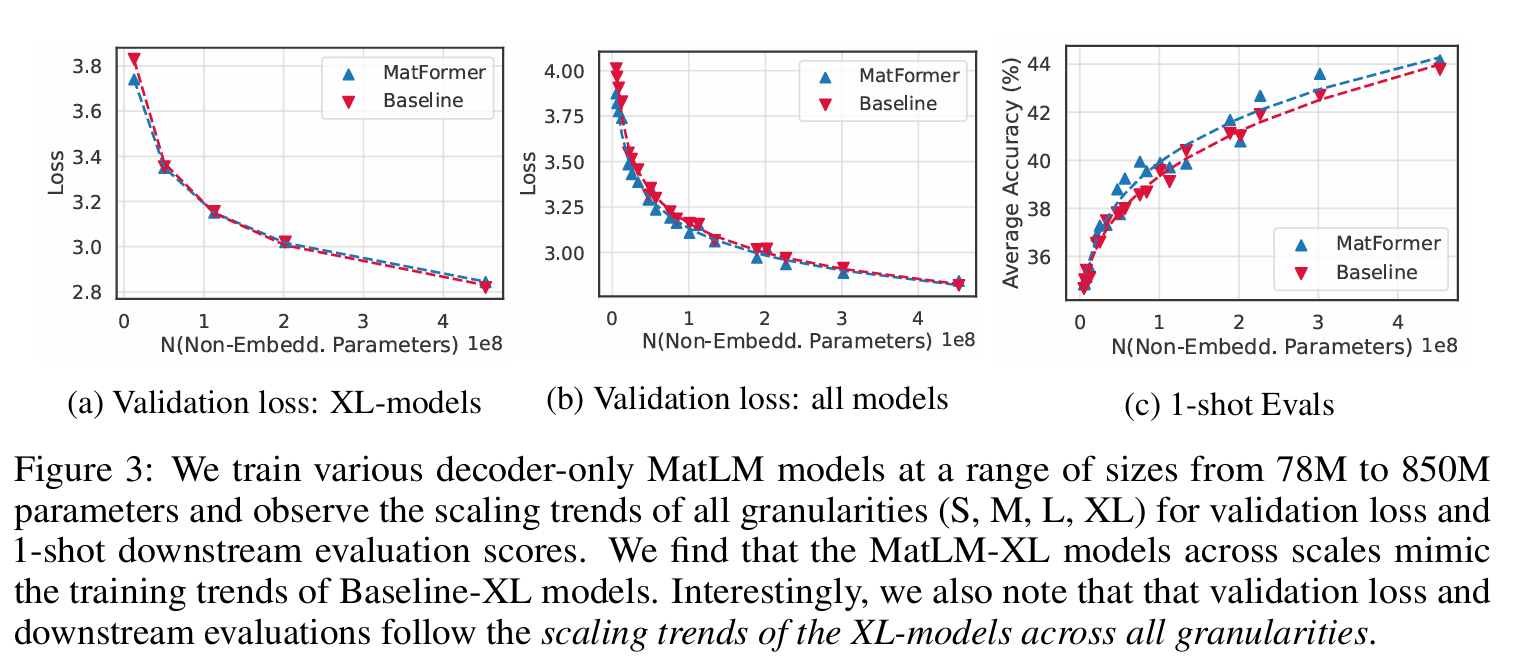
- 스케일링 거동 (Scaling Behavior)
- 78M부터 850M까지 다양한 크기에서도 MatLM-XL 모델은 Baseline-XL과 거의 동일한 손실-파라미터 추세를 보이며, 모든 서브모델 계층에서도 유사한 확장 법칙을 따름
이로써 MatLM은 추가 비용 없이(zero-cost) 다양한 크기의 모델을 한 번에 훈련·배포할 수 있음을 간단히 보여줍니다.

hi!