❔ 질문 ❔
왜 이 논문을 선택했나요?
거대 생성모델의 시초가 되는 GPT의 변천 과정을 살펴보기 위해 선택했다.
어떤 문제를 해결하는 논문인가요?
언어 모델이 다운스트림 태스크에서 zero-shot setting 만으로 다양한 분야에서 좋은 성능을 보일 수 있음을 증명하였다.
왜 해당 문제를 푸는 것이 중요한가요?
지금까지의 연구는 단일 과제에 특화된 단일 모델을 개발하는데 치중되어 있었다. 이는 사전학습 + 지도 세부학습으로 일축되는데 만약 지도학습 데이터가 전혀 필요치 않거나 조금만 필요하다면 일반상식 추론이나 감정 분석과 같은 특정 과제들에 대한 발전도 좋아질 것이다.
기존 연구가 어느정도로 이루어졌나요?
단일 task — 단일 모델 —> pre-train moel + supervised fine tuning이 전통적으로 발전해왔고 성능도 좋았다. 또한 큰 데이터셋으로 학습된 언어모델 (ex. scaled RNN based LM)이 있었고 거대 웹페이지 텍스트 말뭉치 필터링하고 구축하는 방법이나 잡담, 대화와 같은 어려운 생성문제를 언어모델 사전학습 후 미세조정 시 성능이 좋아지는 연구들이 있었다.
기존의 문제점을 해결할 수 있는 새로운 방향성을 잘 제안했나요?
zero-shot 만으로 여러 task에 효과적으로 적용시킬 수 있어 발전가능성과 확장성을 잘 보여주었다.
제안한 방식의 실험 또는 이론적 결과가 어떤가요?
Approach
- 언어 모델링 —> 조건부확률의 곱으로 이루어진 symbold에 따른 합동확률
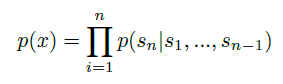
: 조건부확률 만큼이나 p(x)가 다루기 쉬운 샘플링을 가능케함.
- 다중 학습과 메타학습 환경에서 다양한 형식을 갖게 된다.
- 언어는 상황, input, ouput을 유연하게 정의하는 능력이 있다.
- 언어 모델은 supervised label이 없이도 다양한 작업을 배울 수 있는 잠재력을 가지고 있으며, supervised와 unsupervised 학습의 목표의 전역 최솟값은 동일하다.
- 초기 실험 결과, 거대 언어 모델은 다중 작업 학습을 수행할 수 있지만, supervised learning보다 학습 속도는 느리다.
- 목표는 비감독된 목표를 수렴시키는 것에 있다. 인터넷에 방대한 정보를 활용하여 자연 언어를 직접 배우는 모델을 개발하는 것이다.
Training Dataset
- 가능한 다양한 도메인의 context를 포함하는 거대하고 다양한 데이터를 구축하는 것이 목표
- 기존에 있던 Common Crawl 데이터가 있으나 품질이 별로라고 판단해서 새로 만들었다.
- WebText :
- 웹에서 사람에 의해 필터링된 웹 데이터, 레딧에서 3따봉 이상 받은 글만 스크래핑.
- 중복 제거 + 위키피디아는 제외 + 40GB text
- 품질, 크기, 다양성 모두 잡은 데이터셋

Input Representation
- BPE 사용
- subword 기반, 문자 단위로 단어 분해, 반복을 통해 빈도수 높은 문자 쌍을 지속적으로 vocab에 추가
- OOV에 합리적, 자주 등장하는 입력 - 자주 등장하지 않는 입력 사이 보간 가능
- 문자 수준 이상의 병합 막음 —> voca 공간 최적 활용
Model
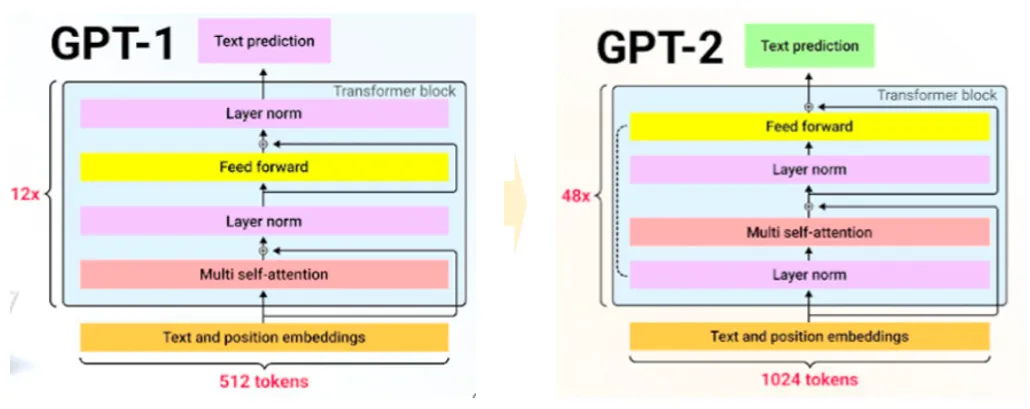
- 기본적으로 GPT-1과 거의 차이가 없다.
- layer normalization이 앞쪽으로 옮겨지고 residual layer 깊이 N에 따라 1/루트 N의 가중치 설정
- voca 사이즈 50257개로 증가하고 context size 1024로 증가했다.
- 배치사이즈가 512로 증가했다.
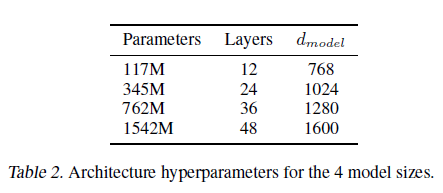
- 가장 작은게 GPT-1 모델이고 가장 큰게 GPT-2 모델이다.
Language Modeling
- byte level로 되어있어 손실있는 전처리나 토큰화가 필요없다.
- WebText 언어모델에 따른 데이터셋의 로그확률을 계산하는 방식으로 통일했다.
- zero-shot setting 만으로 8개 중 7개의 SOTA를 달성했다.
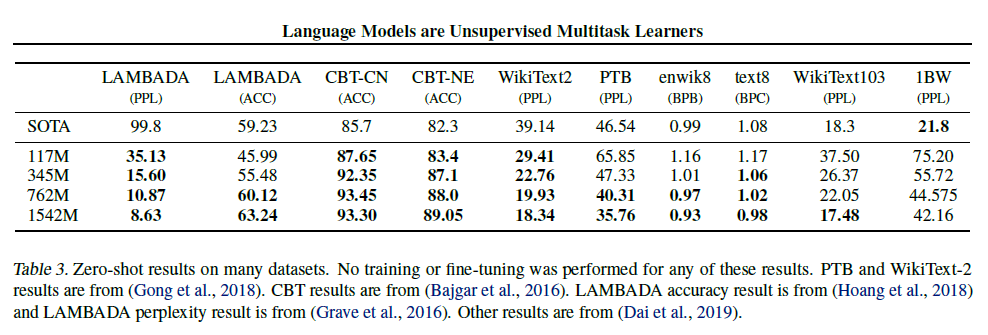
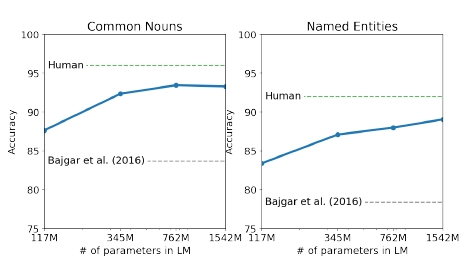
Children’s Book Test
- 고유명사, 명사, 동사, 전치사에 따른 언어모델 성능 측정을 위한 데이터셋
- 원 논문에 따라 각 선택확률과 LM의 선택에 따른 문장 내에서 나머지 부분의 확률을 계산하고, 가장 높은 확률의 선택지를 선택했다.
- 파라미터 사이즈가 커질수록 꾸준히 성능이 올라가고 사람의 능력에도 근접해갔다.
LAMBADA
- 텍스트의 장거리 의존성을 평가한다.
- 대부분의 prediction은 유효한 연속성을 보이지만 마지막 단어로서는 유효하지 않았다.
- 따라서 끝말필터를 추가했고 정확도가 63.24%까지 향상되었다. (최고로부터 4%)
- perlexity는 99.8에서 8.6으로, 정확도는 19%에서 52.66%로 향상시켰다.
Winograd Schema Challenge
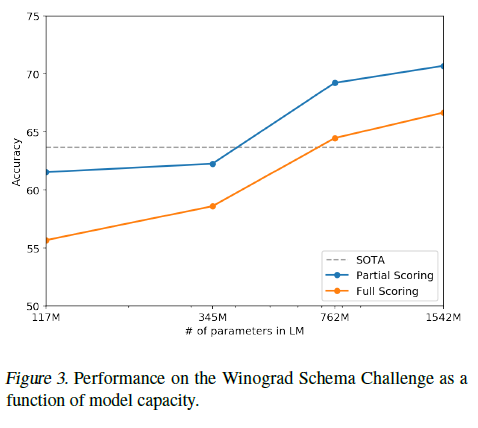
- 텍스트에 존재하는 중의성, 모호한 부분을 해석하는 능력 측정 —> 일반상식 추론
- 기존보다 7% 증가시켜 70.7% 달성
Reading Comprehension
- CoQA(Conversation Question Answering dataset)의 7개 분야에서 가지고온 질문자-답변자 pair 데이터셋이다.
- 독해능력 + 대화에 기반한 언어모델의 능력 평가
- F1 score 55를 달성해 4개 중 3개를 능가했는데 이는 12,700개 이상의 지도학습 데이터셋을 학습시키지 않고도 달성한 성능이다.
- 기존 SOTA인 BERT (F1 89)에도 근접했다고 하는데 무슨 소린진 모르겠다.
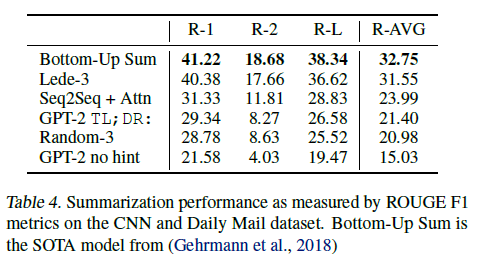
Summarization
- CNN과 Daily Mail dataset으로 요약성능 측정했다.
- 6.4 point 정도 떨어졌다고 한다.
Translation
- english sentence = french sentence 페어로 붙이고 마지막에 english sentence = 라는 마지막 prompt를 붙였다.
- greedy decoding 사용
- WMT-14 French-English test set에서 BLEU score가 11.5정도 나왔다.
- 이는 이전 SOTA모델인 33.5에 미치지 못하지만 저자들은 놀랐다고 한다.
- 전처리 과정에서 영어 제외하고 전부 지웠으며 WebText에서 프랑스어를 검색해본 결과 기존 모델들이 사용한 데이터셋의 500분의 1도 안되는 10mb 정도만 학습에 활용했다고 한다.
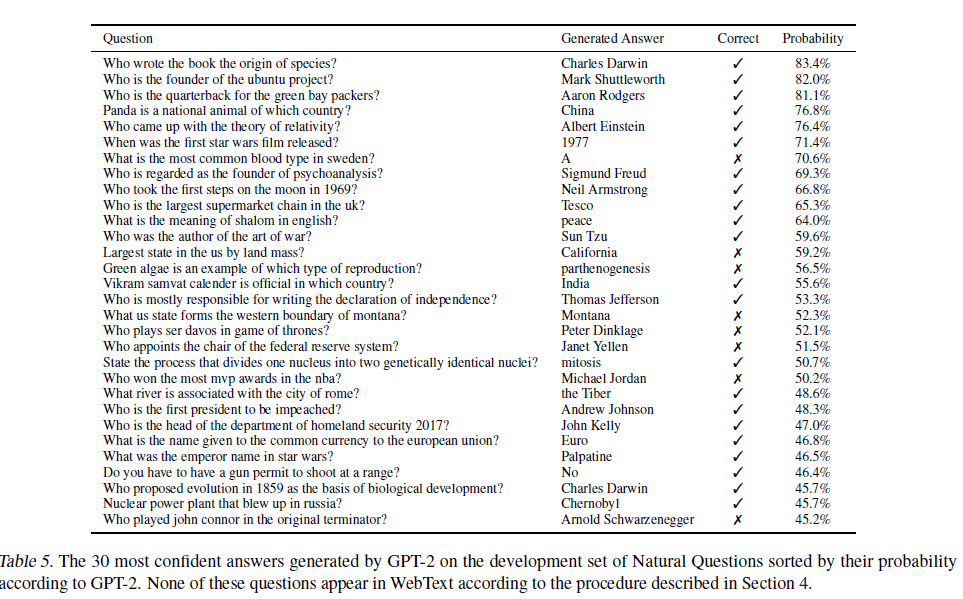
Question Answering
- 답변 결과가 완벽히 일치하는 평가법 쓰면 GPT-2는 4.1% 의 정확도를 보인다. (ex. SQUAD data)
- 가장 작은 모델은 1%도 나오지 않는다.
- 표는 가장 자신있는(아마 probablility가 높은) 답변을 보면 open domain question answering system볻 50%까지 성능이 낮다고 다.
Generalization vs Memorization
- 데이터셋 내에서 train-test간에 overlap이 있는지 확인하는 것은 중요하다.
- 성능 측정에 방해가 되기 때문이고 저자들 역시 WebText에 대해 확인해봤다.
- 8-gram 학습set 토큰을 포함하는 Bloom 필터를 만들어 테스트했다.
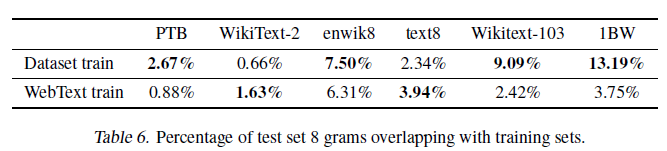
- WebText는 문제 없었다.
- 평균적으로 3.2 %의 overlap이 나타났고 오히려 다른 데이터셋(5.9%)들이 더 심했다.
- 앞으로의 NLP dataset 구축에서 n-gram overlap을 측정해서 train, test를 분리하는 방식을 매우 추천한다고 한다.
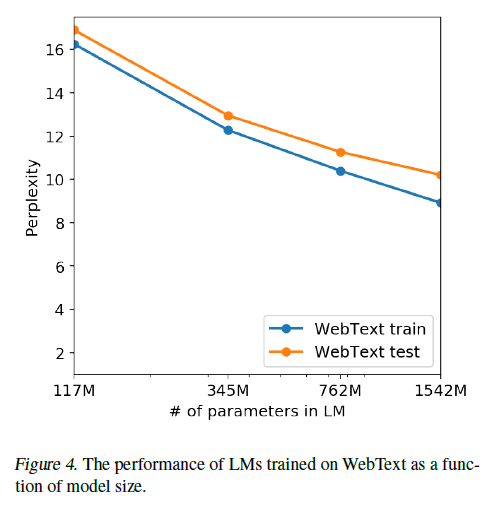
- GPT-2가 모델 사이즈가 커짐에 따라 train, test가 꾸준히 감소한다.
- 즉, 여전히 과소적합되어 있으며 여전히 성능이 증가할 가능성을 보여준다.
결론과 시사점을 적어주세요
- 여전히 비지도학습 연구할 거리가 많이 남아있다.
- GPT-2의 zero-shot 성능은 좋았으나 summarization에선 기본성능밖에 안나왔다.
- fine-tuning 성능에 대한 한계가 명확치 않아 다양한 데이터셋에서 fine-tuning을 계획하고 있다.
- GPT-2의 크기가 BERT에서 말한 단방향 representation의 비효율성을 극복할 수 있을만큼 충분히 큰지도 확실치 않다고 한다.
같이 읽거나 알아보면 좋을 개념이나 논문 (키워드 + 링크)
- GPT-3

hi!