🖊️Abstract 🖊️
Sentence-level relation extraction (RE) aims at identifying the relationship between two entities in a sentence. Many efforts have been devoted to this problem, while the best performing methods are still far from perfect. In this paper, we revisit two problems that affect the performance of existing RE models, namely entity representation and noisy or ill-defined labels. Our improved RE baseline, incorporated with entity representations with typed markers, achieves an F1 of 74.6% on TACRED, significantly outperforms previous SOTA methods. Furthermore, the presented new baseline achieves an F1 of 91.1% on the refined Re-TACRED dataset, demonstrating that the pretrained language models (PLMs) achieve high performance on this task. We release our code to the community for future research.
📖 세 줄 요약 📖
- sentence-level RE task를 중점으로 모델링
- input에 entitiy name, type을 같이 넣어서 준 모델이 성능 가장 좋다.
- 모델 자체의 노이즈도 신경써야 한다.
❔ 질문 ❔
왜 이 논문을 선택했나요?
KLUE 대회를 대비하여 Relation Extraction task에서 데이터의 특성을 더 잘 반영할 수 있는 방법론 중 하나를 공부하기 위해서이다.
어떤 문제를 해결하는 논문인가요?
typed entitiy marker를 이용해 RE task의 SOTA를 달성하는 새로운 방법론을 제안하였다.
왜 해당 문제를 푸는 것이 중요한가요?
기존의 RE task를 해결하는 방법들은 input 데이터가 가진 정보(entitiy name 등)을 제대로 활용하지 않았고 노이즈가 섞인 데이터가 다수 있었다.
기존 연구가 어느정도로 이루어졌나요?
외부의 직접적인 정보를 plm에 집어넣어서 학습시키거나 관련 내용으로 사전 학습된 adapter를 붙여서 학습시켰다.
기존의 문제점을 해결할 수 있는 새로운 방향성을 잘 제안했나요?
raw text 뿐만 아니라 옆의 side information인 names, spans, types같은 정보를 함께 활용하며 성능을 끌어올렸다. 또한 기존에 사람이 라벨링한 데이터들을 보완하는 새로운 baseline을 제안하여 이후 연구를 도왔다.
제안한 방식의 실험 또는 이론적 결과가 어떤가요?
문제 정의
- 문장 x의 entitiy pair가 각각 subject와 object로 나뉘고 이 둘의 관계를 예측한다.
- 정해진 범주가 관계가 존재하지 않으면 NA로 분류한다.
모델 구조
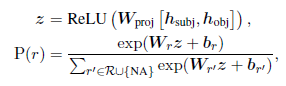
- 기존 PLM 모델을 베이스로 input sentence x와 entitiy span, entitiy type를 모델 입력으로 같이 넣어주고 출력으로 나온 마지막 hidden state로 loss를 계산한다.
Entitiy Representation
- 기본적으로 sentence-level RE를 사용하는데, input으로 문장 뿐만 아니라 subject와 object들의 이름, 구간, NER type도 함께 넣어준다.
| sentence | subject_entitiy | object_entitiy | label |
|---|---|---|---|
| 하비에르 파스토레는 아르헨티나 클럽 타예레스의 유소년팀에서 축구를 시작하였다. | { "word": "하비에르 파스토레", "start_idx": 0, "end_idx": 8, "type": "PER" } | { "word": "아르헨티나", "start_idx": 11, "end_idx": 15, "type": "LOC" } | 17 (per:origin) |
- Entitiy mask
- [SUBJ-TYPE], [OBJ-TYPE]과 같은 special token을 추가하여 대체한다.
- 모델 훈련 중 특정 entitiy에 overfitting 하는 것을 방지한다고 한다.[SUBJ-per]는 [OBJ-origin] 클럽 타예레스의 유소년팀에서 축구를 시작하였다.
- Entitiy marker
- [E1] SUBJ [/E1] ... [E2] OBJ [/E2][E1] 하비에르 파스토레 [/E1]는 [E2] 아르헨티나 [/E2] 클럽 타예레스의 유소년팀에서 축구를 시작하였다.
- Entitiy marker (punct)
- special token을 추가하지 않는 entitiy marker
- “@ SUBJ @ ... # OBJ #@ 하비에르 파스토레 @는 # 아르헨티나 # 클럽 타예레스의 유소년팀에서 축구를 시작하였다.
- Typed entitiy marker
- special token 추가하여 감싸주기. NER 타입을 entitiy marker로 넣어준 방법.
- <S: TYPE> SUBJ </S : TYPE> … <O:TYPE> OBJ </O:TYPE><S: per> 하비에르 파스토레 </S : per>는 <O:origin> 아르헨티나 </O:origin>*클럽 타예레스의 유소년팀에서 축구를 시작하였다.
- Typed entitiy marker (punct)
- 위와 동일하나 special token이 아닌 punctuation을 이용하여 감싼다.
- @ subj-type SUBJ @ … # ^ obj-type ^ OBJ #@ per 하비에르 파스토레 @는 # ^ origin ^ 아르헨티나 # 클럽 타예레스의 유소년팀에서 축구를 시작하였다.
모든 special token의 embedding은 random initialized 되었고 fine-tuning되는 동안 업데이트 된다.

Experiments
- 데이터셋
- TACRED, TACREV, Re-TACRED
- 모델들
- 모델은 다음과 같고 Roberta-large 모델에 typed entitiy marker(punct)를 적용한 경우가 가장 높은 성능을 보였다.
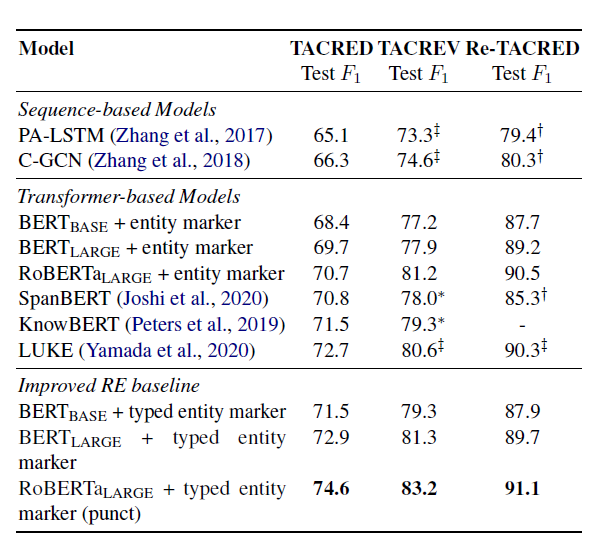
결과 해석
- typed entitiy marker과 같은 entitiy info는 성능향상에 매우 좋다.
- entitiy name을 input에 넣어주는 것은 항상 좋다.
- entitiy marker에 쓰는 기호의 종류도 중요한 영향을 미친다.
- punct 버전과 아닌 버전의 차이를 보면 알 수 있다.
- 데이터셋 자체의 노이즈도 성능에 영향을 크게 미친다.
결론과 시사점을 적어주세요
향상된 entitiy representation 방법을 적용하여 기존을 뛰어넘는 baseline을 세웠다.
같이 읽거나 알아보면 좋을 개념이나 논문 (키워드 + 링크)
KLUE
RoBERTa
