Deep Learning
딥러닝
- 머신러닝 방법론 중 하나로써, 생물의 신경망 원리에 착안하여 만들어진 인공신경망 기법
- 딥러닝 = 인공신경망 (뉴럴네트워크) = 다층 퍼셉트론 (MPL)
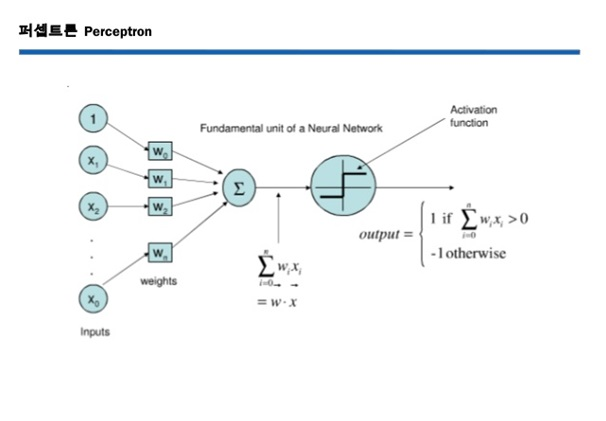
- 퍼셉트론
- 사람의 뇌를 모방한 인공 뉴런 (선형적 계산을 함)
- 가중합 + 활성화 함수
- 비선형 문제를 선형 문제로 변경 + 선형 연산 (선형 분류)
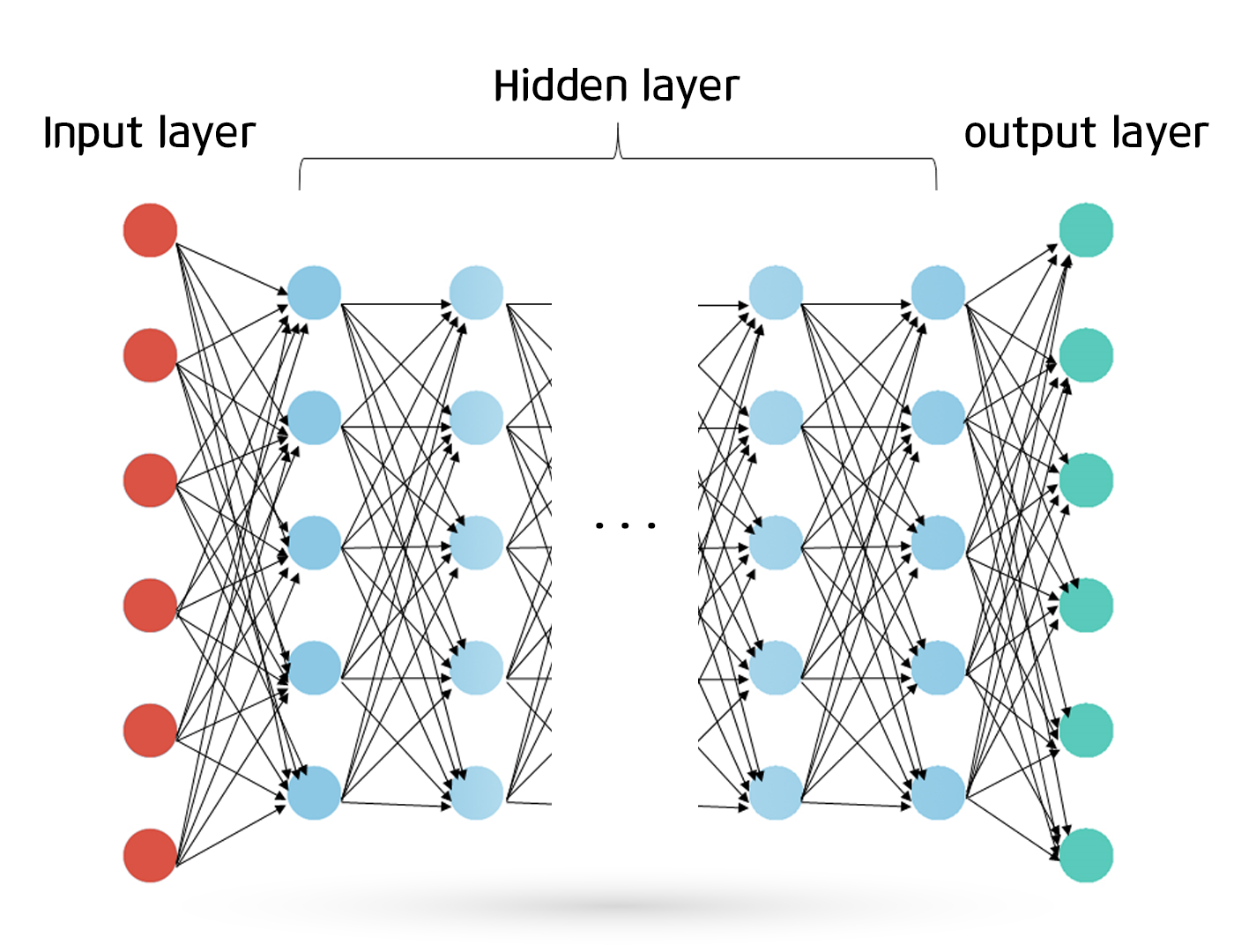
다층 퍼셉트론
- 최소 3층 이상
- 비선형 문제 해결 (비선형 분류 모델)
- 확률 모델
- 비선형 문제를 해결할 수 있는 이유
- 중간에 비선형 함수인 활성화 함수가 경계선의 방정식에 포함되어 있기 때문
- 마지막 층은 단일 퍼셉트론이다
- 마지막에는 선형 경계선을 그린다
- 일반적으로 딥러닝은 차원을 축소시킴
- 층을 계속해서 통과하여 비선형 문제를 선형적으로 해결함
- 층을 조절해야 함 (층 수에 따라 모델 복잡도가 증가한다)
- 층이 너무 많으면 과대적합이 발생
- 노드의 수가 많을수록 모델 복잡도 ㅋ증가
- Drop - Out 방식으로 Weigh의 크기 (학습하는 Weight 개수) 규제 → Over - Training 해소
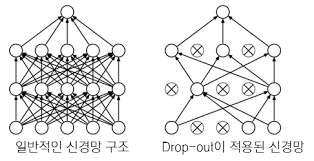
- 층을 조절해야 함 (층 수에 따라 모델 복잡도가 증가한다)
- 다층 퍼셉트론의 Cost
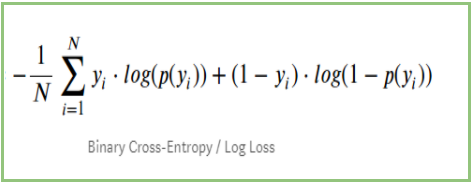
오차 역전파
- 오차를 역방향으로 전파해나가며 출력부와 가까운 층의 Weight들부터 순차적으로 Weight를 업데이트해나가는 방식
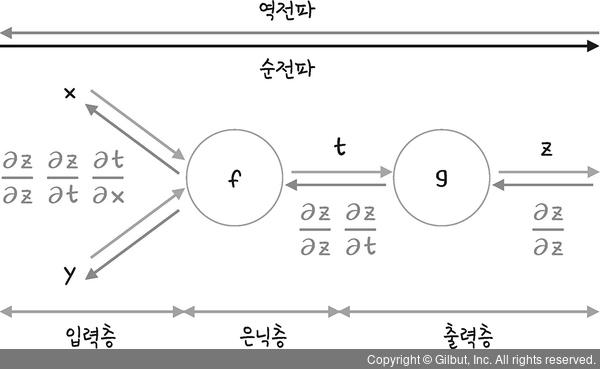
- Chain - Rule
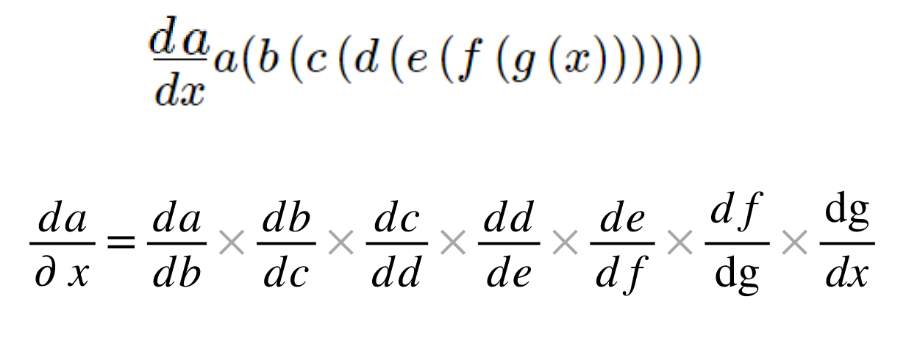
활성화 함수
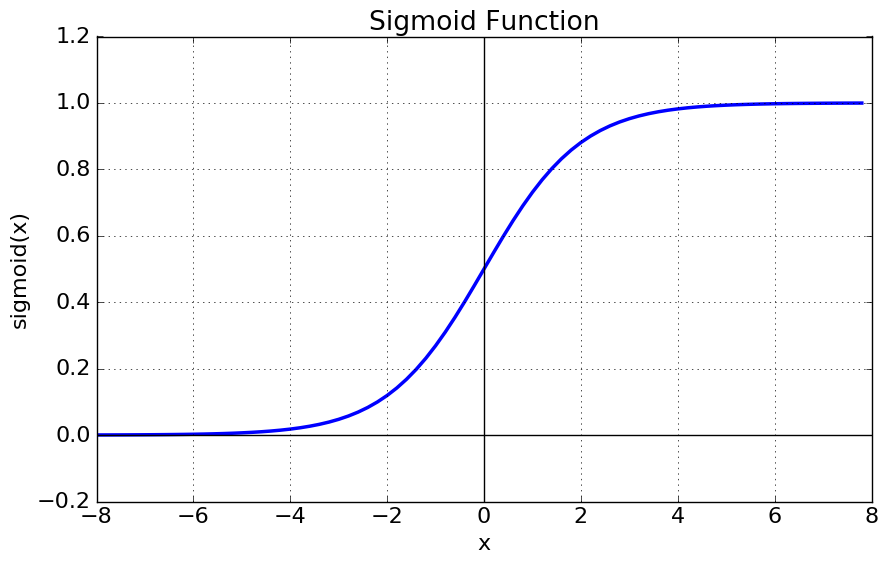
- 시그모이드 함수
-
Wa가 0일 때 기울기가 제일 크다
-
0일 때 기울기 ⇒ 0.25
-
-
기울기 손실
-
시그모이드 함수의 값은 0 ~ 1인데, 층이 깊어지면 입력층에 가까운 weight의 오차 기울기를 계산할 때 0 ~ 0.25 (시그모이드 기울기) 사이 값을 여러 번 곱하게 된다는 것이다
→ 오차가 크게 존재할 경우, 입력층에 가까운 층의 weight값은 업데이트가 이루어지지 않을 수 있다
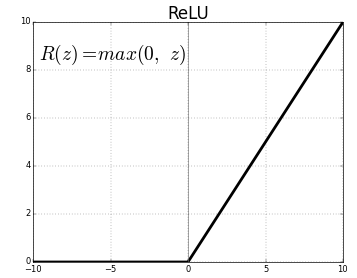
⇒ ReLU
-
입력값이 음수면 0, 양수면 입력값 그대로 반환하는 함수
-
큰 값이 그대로 전달된다
-
기타 ReLU
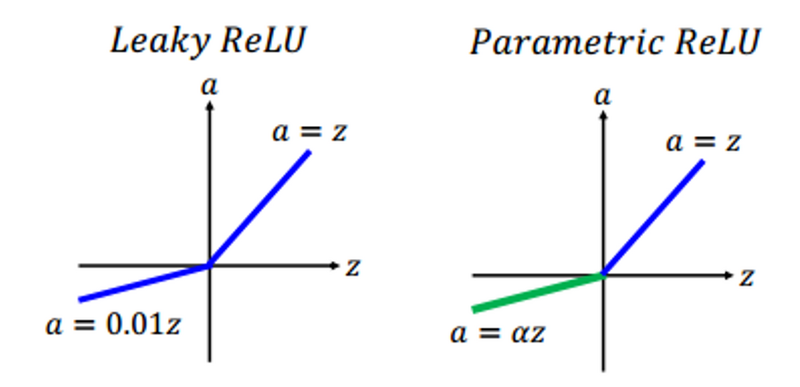
-
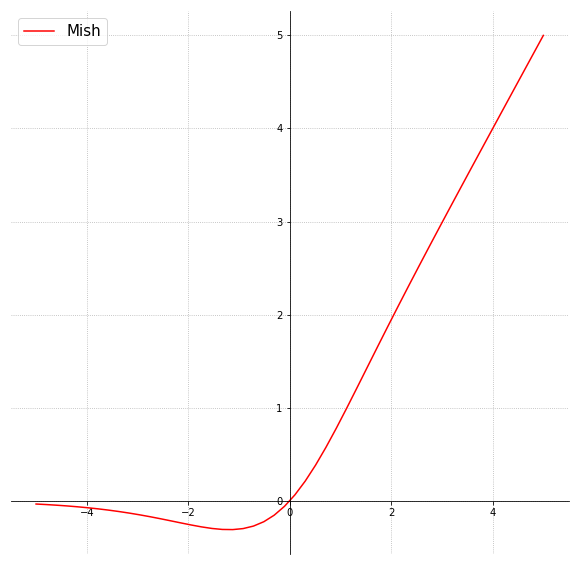
- mish
초기화 방법
-
초기에 Weight 값을 잘 주는 것이 좋음
-
RBM (Restrict Boltzmann Machine, 비지도 학습)
-
사전에 트레이닝을 시켜서 초기에 좋은 Weight값을 주는 방법
-
입력값만을 가지고 비지도 방식으로 사전학습을 통해 weight 초기값을 설정하는 방법
-
굉장히 무거운 계산량을 요구한다
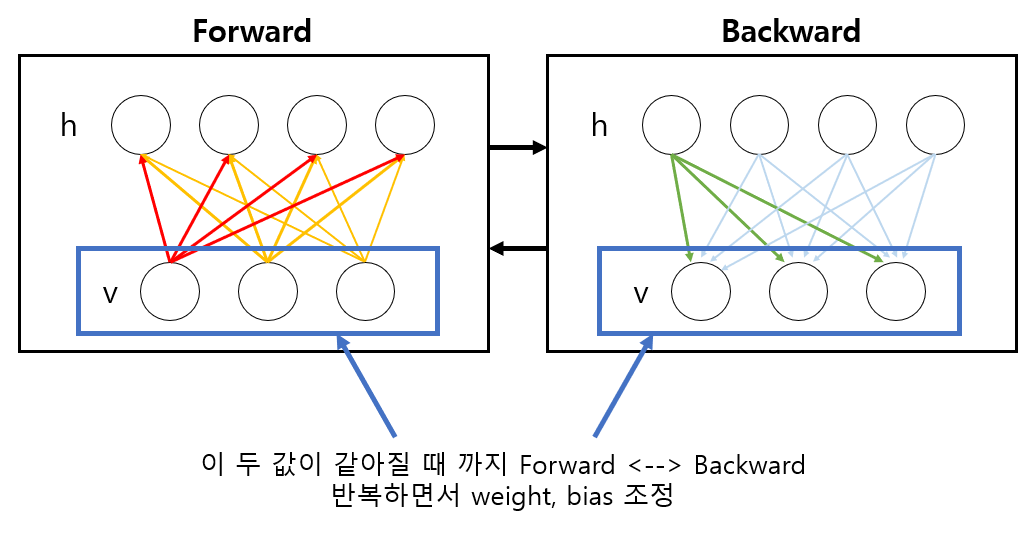
-
-
Xavier (자비에 글로럿)
-
RBM의 무거운 계산량을 계선한 방법론
-
가중치의 분산은 데이터의 분포에 영향을 받고, 데이터의 분포는 데이터의 개수에 영향을 받는다는 가정 하에 제안된 방법
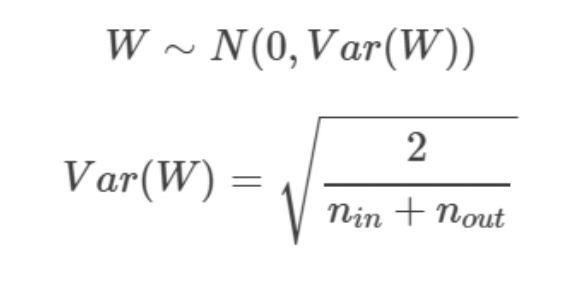
-
- He (케이밍 허)
-
기존 Xavier 초기화에서 앞 층 노드 수를 2로 나눈 후 루트를 씌운 방식으로 Xavie에 비해 분모가 작기 때문에 활성화 함수 값들을 더 넓게 분포 시킨다
-
Xavier와 유사하지만 He는 입력 노드와 출력 노드의 개수를 모두 고려하지 않고 입력 노드 수만 고려한다는 점에서 차이가 있다
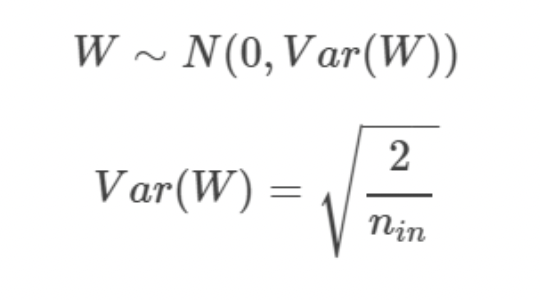
-
미니 배치
- 딥러닝은 데이터를 나누어서 오차를 계산하고 가중치 조절을 여러번 한다
- 부족하면 에포크 수를 늘린다
손실 함수
- 딥러닝의 모델은 복잡하기에 손실 함수도 복잡하다 → 기울기 손실 문제 발생 (local Minimum)

🌳가 되기 위해 🌱부터 시작
정말 유익하네요!