인공지능 기초
AI vs ML vs DL 차이점
- AI :
- Rule - Based : 사럼처럼 행동할 수 있도록 만들기 위해 알고리즘을 사람이 직접 미리 만들어 놓는 방법
- ML:
- Training - based: 규칙을 사람이 만드는 것이 아니라 대량의 데이터를 학습시킴으로써 컴퓨터가 스스로 규칙을 만들게 하는 방법
- 정교하게 프로그램(Rule - Based)되지 않은 채, 경험(Data)으로부터 머신을 러닝하는 것
- 목적 : 좋은 Hypothesis는 Cost가 낮은 Hypothesis이다
- 원리: Cost가 가장 낮을 때의 Weight를 찾는 과정 (Wt+1 = Wt - a * G)
- Hypothesis 결정해주어야 함
- DL:
- 머신러닝 방법론 중 하나로써, 생물의 신경망 원리에 착안하여 만들어진 인공신경망 기법
- 인공신경망 (뉴럴 네트워크) = 다층 퍼셉트론 (3층 이상)
- Hypothesis을 머신이 알아서 결정
Supervised vs Unsupervised Learning 차이점
- Supervised
- 출력값이 존재 → 예측
- Regression : 실제 술자를 예측
- Classification : 숫자로 라벨링된 카테고리를 예측
- Unsupervised
- 출력값이 비존재 → X간의 관계를 학습 ⇒ 군집화, X의 값 변환 → 전처리 수단
- Clustering : X간의 관계 파악 → 그룹화
- Transformation : X간의 관계 파악 → 특성 추출
- 출력값이 비존재 → X간의 관계를 학습 ⇒ 군집화, X의 값 변환 → 전처리 수단
Cost를 낮추는 방법
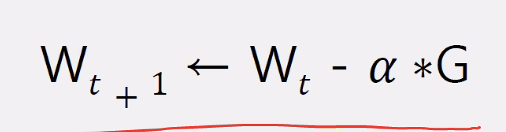
- Gradient Descent :
- Cost가 가장 낮아질 때까지 Weights 업데이트를 반복 (반복 계산)
- 기울기 양수 : Cost 변화 방향과 W의 변화 방향이 같다
- 기울기 음수 : Cost 변화 방향과 W의 변화 방향이 반대 ⇒ 기울기가 양수면 W는 감소해야 하고, 기울기가 음수면 W는 증가해야 한다 (기울기가 0이 될 때까지)
- Optimizer :
- Cost 최소화하는 최적화 모델 선택
- Cost가 최저가 되는 것이지 0이 되는 것은 아님
- Cost 재정의
- Cost = 오차 + W 총크기
- argmin(오차 + W 총 크기)
학습을 잘한다는 것은
- 학습 문제의 전체적인 경향도 잘 팡가해서, 같은 경향의 새로운 문제가 나와도 잘 맞추는 것
- 오차 최소화 (예측값 - 실제값 ⇒ 수치화) + 일반화
- Under fit : 학습/검증 데이터 둘 다 못함
- Over fit : 학습 데이터는 잘하지만 검증 데이터는 못함
- Generalization
- 무제의 복잡도에 적합하게 학습
- 규제화 : 경계선의 복잡도에 제한을 걸어주는 기법
- 복잡도 수치화(norm) : Hypothesis의 Weight의 총 크기
- L2 - Norm : 각 요소를 제곱한 값의 총 합
- L1 - Norm : 각 요소 절대값의 총 합
Over - Fitting 해결
- 모델과 데이터 모두 접근해서 해결해야 한다 (데이터에 초점을 맞추는 것이 좋다)
선형 회귀
- L1 : 가중치의 절댓값의 합을 최소화하는 것
- L2 : 가중치의 제곱의 합을 최소화하는 것
로지스틱 회귀
- L1 : 가중치의 절댓값의 합을 최소화하는 것
- L2 : 가중치의 제곱의 합을 최소화하는 것
SVM
- margin 최대화
결정 트리
- 가지치기
- 파라미터 : max_depht, min_sample_leaf, min_sample_split
MLP
- layer 수 축소
- node 수 축소
- Drop out
데이터의 양 측면에서
- 데이터 양을 늘린다
데이터의 비선형성(복잡도) 측면에서
-
비선형 모델인데 선형 데이터를 사용하면 과대적합이 발생한다
→ 데이터의 복잡도를 높인다
데이터의 피처 개수 측면에서
- 데이터 피처 수가 많을수록 선형적으로 변화한다
- 데이터의 피처 수를 줄인다 (복잡한 문제로 만든다 - 비선형성 증가)
epoch 측면에서
- epoch 수 줄인다

🌳가 되기 위해 🌱부터 시작