최적화
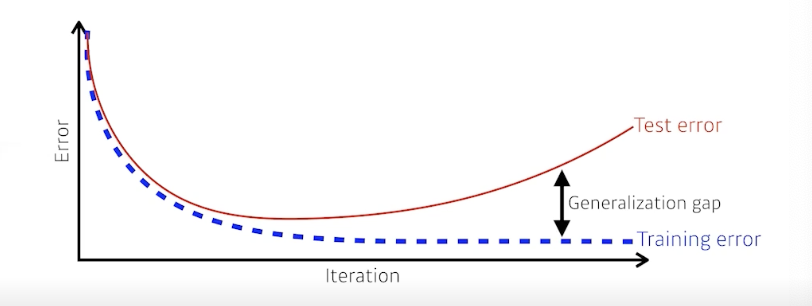
Generalization
- 좋은 Generalization 성능 : 학습시키지 않은 데이터에 대한 성능이 학습 데이터와 비슷하게 나올 것이다
- Generalization Gap = Test Error - Training Error -> 최소화
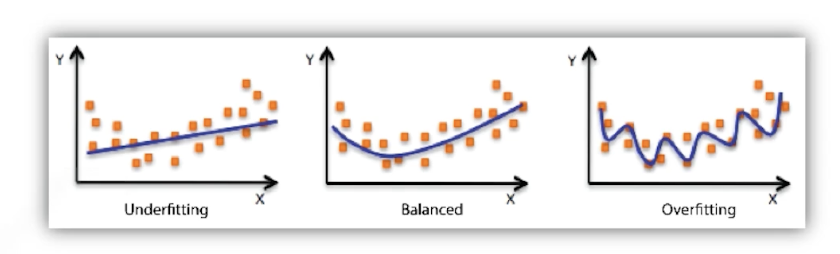
Overfitting / Underfitting
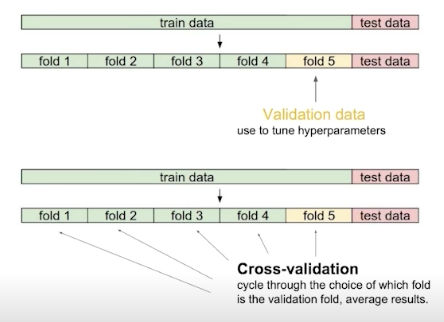
Cross - Validation
- Train • Validation Data Set 나누는 비율 -> 최적의 하이퍼 파라미터 찾음
- 최적의 하이퍼 파리미터로 모든 데이터 셋을 학습
Bias & Variance
- Bias : 평균적으로 Target 잘 접근하는 가
- Variance : Output이 얼마나 일관적으로 나오는 가
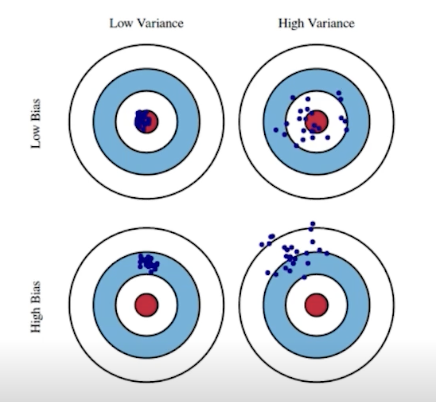
Bias & Variance Trdaeoff

Bootstrapping
- 학습 데이터 중 일부들을 여러번 사용하여 여러 모델들을 생성
- 여러 모델들의 Output들이 얼마나 일치한가
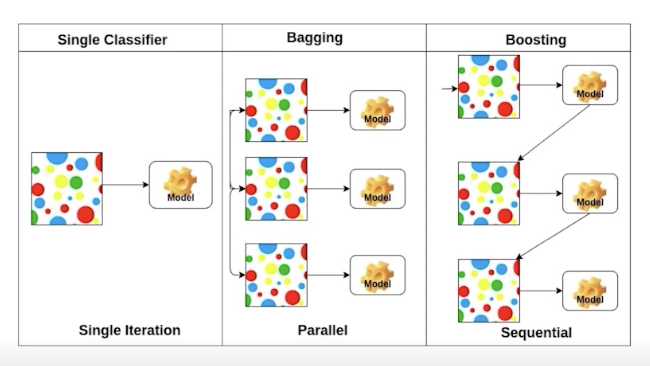
Bagging & Boosting
- Bagging : 일부 데이터셋으로 생성된 n개의 모델들의 결과를 종합
- Boosting : 잘 예측하지 못한 데이터에 대해 잘 예측하는 모델을 생성
Gradient Desent Methods
-
Stochastic Gradient Desent
- 하나의 샘플을 통해서 Gradient를 업데이트
-
Mini-Batch Gradient Desent
- Mini-Batch 마다 Gradient를 업데이트
-
Batch Gradient Desent
- 모든 데이터를 통해 Gradient를 업데이트
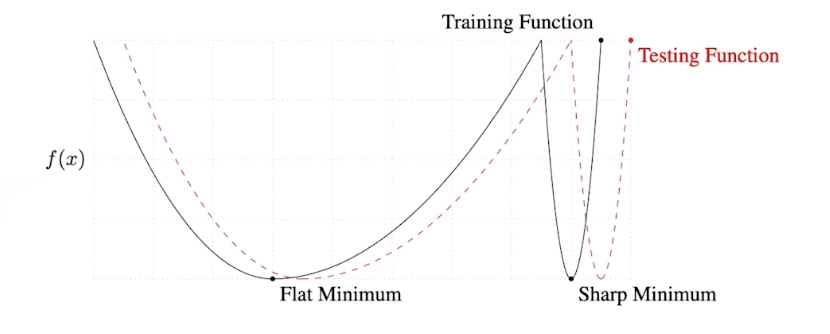
Batch-Size Matters
- 큰 Batch-Size -> Sharp minimizers 도달
- 작은 Batch-Size -> Flat minimizers 도달 : 좋은 Generalization 성능 발휘
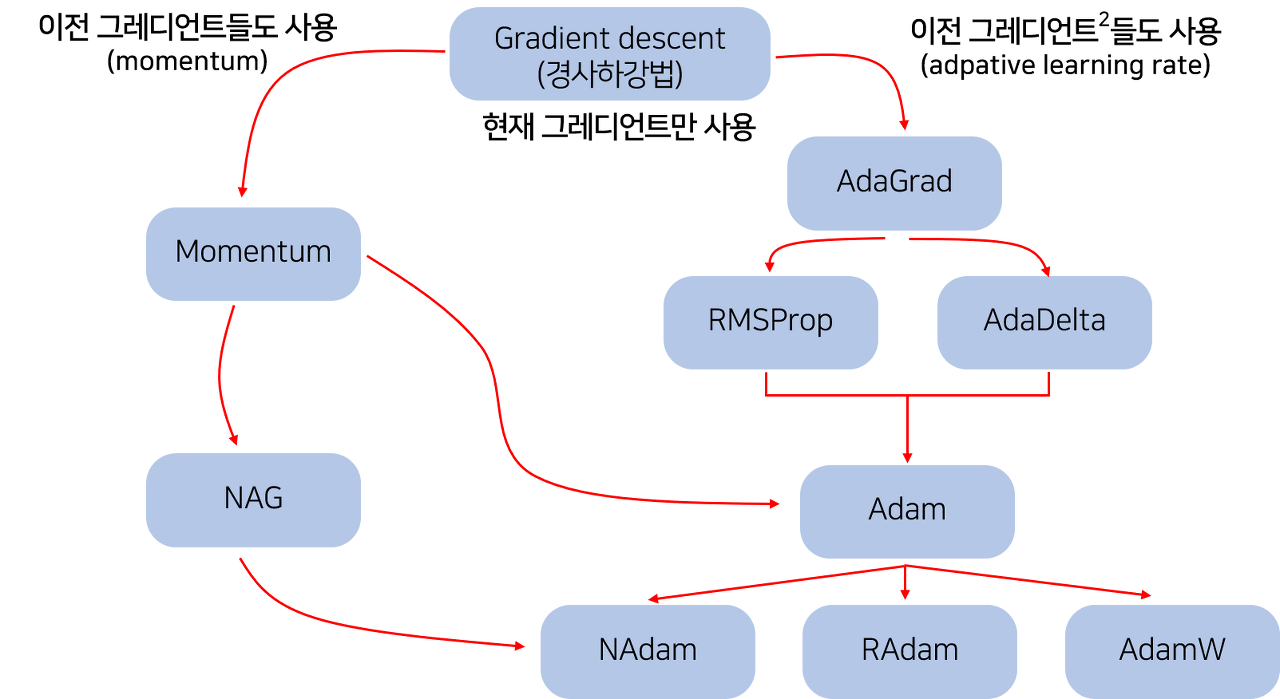
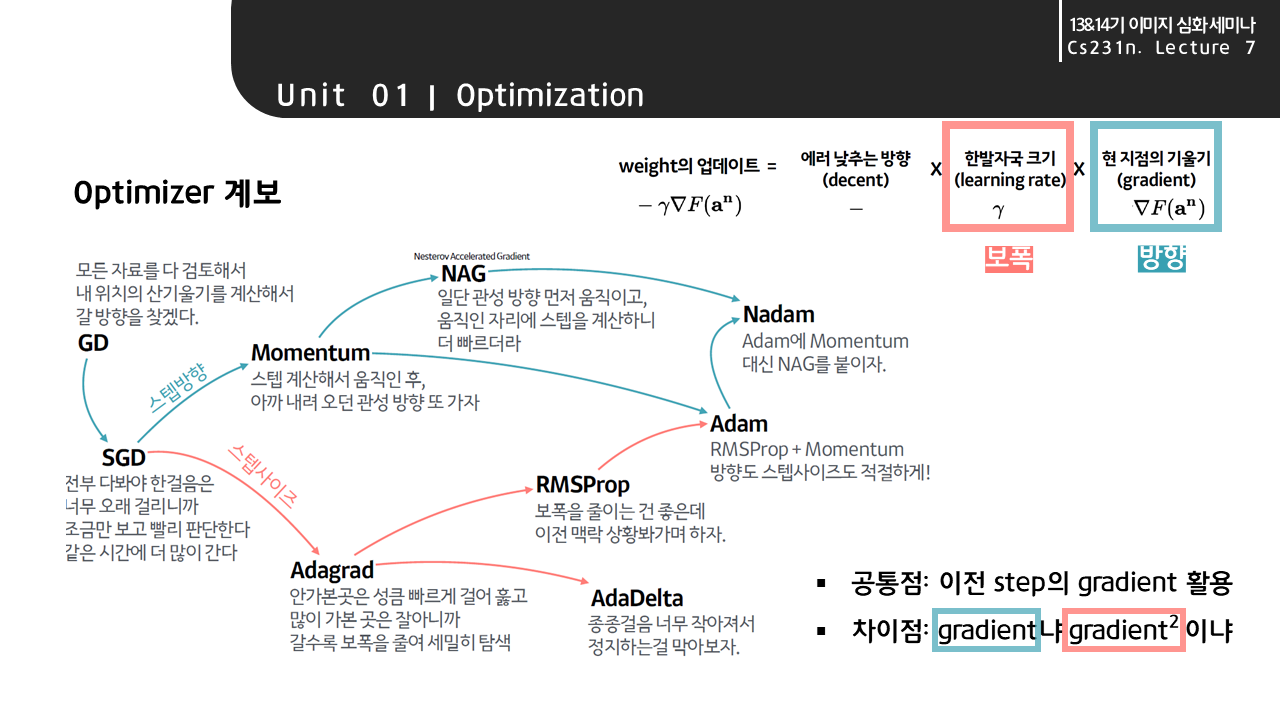
Optimizer
-
Gradient Desent
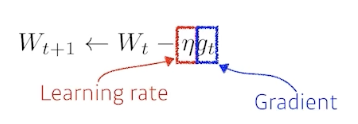
-
Momentum
- 이전 Gradient Desent 활용
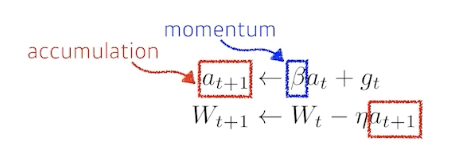
-
Nesterov Accelerated Gradient
- 모멘텀 방향으로 먼저 점프를 하고, 이 방향을 기울기 업데이트와 함께 수정
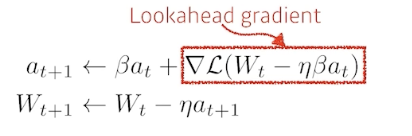
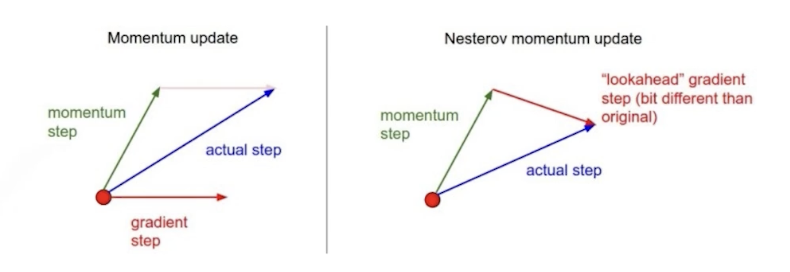
-
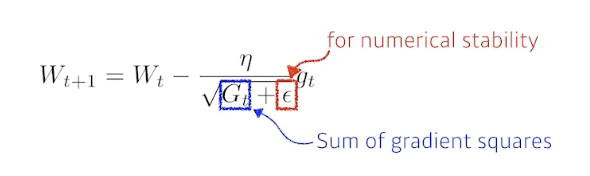
Adagrad
- 많이 변한 파라미터는 적게 변화시키고 적게 변화한 파라미터는 많이 변화시킴
- 뒤로 갈수록 학습이 점점 멈추게되는 문제가 발생할 수 있음
-
Adadelta
- widow만큼의 변화량을 봄
- learning rate가 없음
- 큰 모델들은 많은 파라미터를 가지게 되어 GPU 터질 수 있음

-
RMSprop
- 기울기를 단순 누적하지 않고 지수 가중 이동 평균 Exponentially weighted moving average 를 사용하여 최신 기울기들이 더 크게 반영
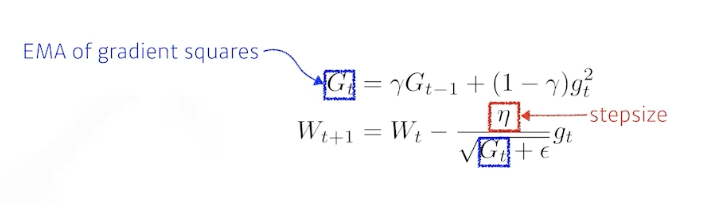
-
Adam
- AdaDelta와 같이 decaying average of squared gradients를 저장할 뿐만 아니라, 과거 gradient 의 decaying average도 저장

Regularization
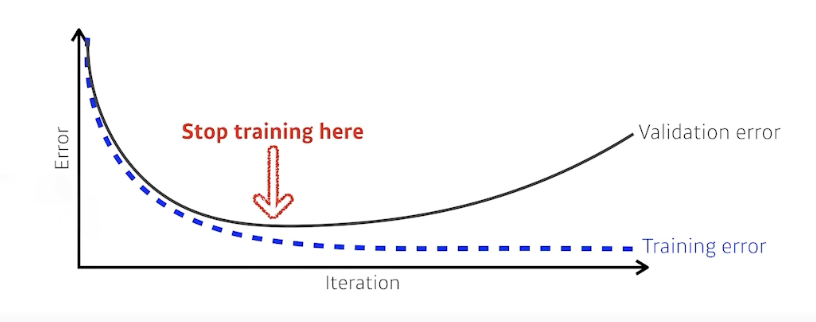
Early Stopping
- Validation Error가 커지는 시점에 학습을 멈춤
Parameter Norm Penalty (Weight Decay)
- 파라미터가 너무 커지지 않도록 함

Data Augmentation
- 데이터 양을 늘림
Noise Robustness
- 입력 데이터 및 Weight에 노이즈를 넣음

Label Smoothing
- 데이터 두 개를 뽑아서 섞어줌
- EX : Cut Mix

Drop Out
- 일부 Weight를 0으로 바꿈
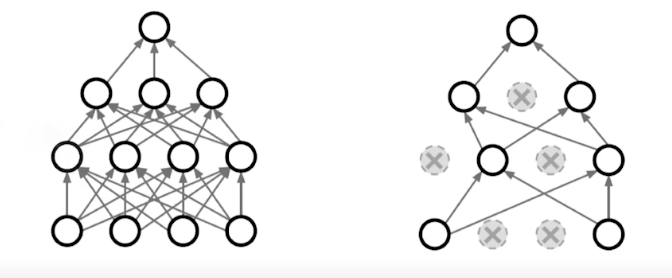
Batch Normalization
- 각 배치 단위 별로 데이터가 다양한 분포를 가지더라도 각 배치별로 평균과 분산을 이용해 정규화하는 것

🌳가 되기 위해 🌱부터 시작