How can we tell whether weight of a linear classifier W is good or bad?
To quantify a "good" W, loss function is needed.
Starting with random W and find a W that minimizes the loss to optimize weights of a linear classifier.
Type of loss function
(1) Hinge Loss
✔ Binary hinge loss (=binary SVM loss)
There are only two classes: positive or negative.
(1) If ist image is in positive class, then class label yi is +1,
(2) If ist image is in negative class, then class label yi is −1.
Lis=max(0,1−yi×s)=WT×xi+b
To minimize the loss (→ Li=0), yi×s≥1 should be satisfied.
There are two cases where yi×s≥1:
(1) ist sample is in positive class: yi=1,thens≥1
(2) ist sample is in negative class: yi=−1,thens≤−1
∴ There are margin (1 ~ -1) between positive class and negative class.
✔ Hinge loss (=multiclass SVM loss)
For the number of class c(>2),
Lis=j=1,j!=yi∑cmax(0,1−(sj−syi))=W×xi+bW=⎝⎜⎜⎜⎛w1Tw2T...wcT⎠⎟⎟⎟⎞,s=⎝⎜⎜⎜⎛s1s2...sc⎠⎟⎟⎟⎞
To minimize the loss (=Li=0), syi−sj≥1 should be satisfied.
In other word, ist image is in yist class should be satisfied the following condition:
syi−s1syi−s2...syi−syi−1syi−syi+1...syi−sc≥1≥1≥1≥1≥1
∴ There are margin 1 between yi class and other classes.
∴ yist class must have the largest s value, and must be at least 1 greater than the s value of the other classes.
(2) Log Likelihood Loss
Where j satisfies zij=1,
LiP=−logPj=⎝⎜⎜⎜⎛p1p2...pc⎠⎟⎟⎟⎞
P is not a score, but probability.
pj is a probability that the ith image belongs to the jth class.
⁕ class label for ith image zij is 0 or 1
As p is closer to 1, loss is minimized. ( ∵−log(1)=0)
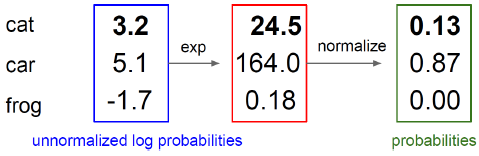
Let's suppose that ith image belongs to class 2(j=2) and c=10 .
Then zi,Li are as below :
zi=⎝⎜⎜⎜⎜⎜⎛010...0⎠⎟⎟⎟⎟⎟⎞,p=⎝⎜⎜⎜⎜⎜⎛0.10.70...0.2⎠⎟⎟⎟⎟⎟⎞∴Li=−log0.7
(3) Cross-entropy Loss
Li=−j=1∑c(zijlogpj+(1−zij)log(1−pj))
(1) If zij=0, then sum −log(1−pj) to Li.
(2) If zij=1, then sum −log(pj) to Li.
⁕ Softmax Activation Function
Probability is proportional to escore, so we can compute probability using scores. The function below is the softmax activation function.
P(Y=k∣X=xi)=pk=∑j=1cesjesk
✔ Softmax + Log likelihood loss:
We can apply Log likelihood loss using probabilites of softmax function.
This is often called 'softmax classifier'.
✔ Softmax + Cross-entropy loss:
We can apply Cross-entropy loss using probabilites of softmax function.
✔ Compare with SVM (Hinge loss)
Softmax Classifier constantly tries to make the loss small because the loss never becomes zero.
However, if the margin is 1 or higher, the SVM does not try to reduce the loss because the loss is already zero.
(4) Regression Loss
Regression Loss function is widely used in pixel-level prediction. (Ex) image denoising
Using L1 or L2 norms :
LiorLi=∣yi−si∣=(yi−si)2
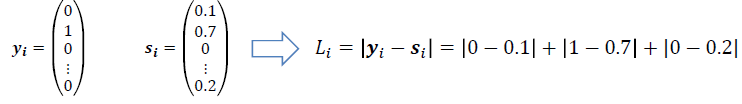
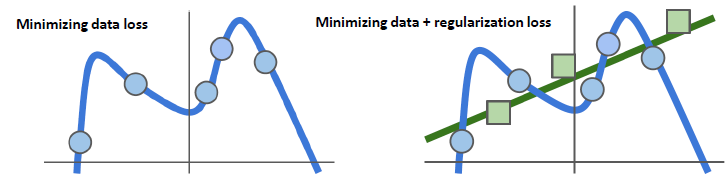
Regularization
Suppose that we found a W such that L=0.
Is this W unique?
No. 2×W is also has L=0.
For this reason, regularization loss is needed.
In the function below, λR(W) is the part of regularization.
L=N1i=1∑NLi(f(xi,W),yi)+λR(W)
✔ 4 types of Regularization:
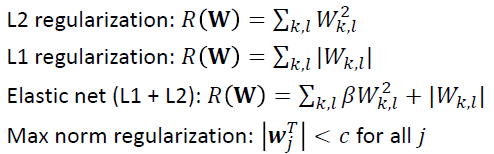
Optimization
(1) Gradient Descent
Gradient Descent is the most simple approach to minimizing a loss function.
WT+1=WT−α∂WT∂L
(2) Stochastic Gradient Descent(SGD)
Full sum is too expensive when N is large.
Instead, approximate sum using a minibatch of examples 32/64/128 common.
L=N1i=1∑NLi(f(xi,W),yi)+λR(W)∂W∂L=N1i=1∑N∂WLi(f(xi,W),yi)+λ∂W∂R(W) 