행렬 A에 대한 함수 의 gradient는 위와 같이 구할 수 있는데요,
gradient는 어떤 값을 의미할까요?
gradient는 함수의 가장 가파른 증가 방향을 가리키는 벡터입니다.
즉, the direction of "steepest increase"를 가리키는 벡터입니다.
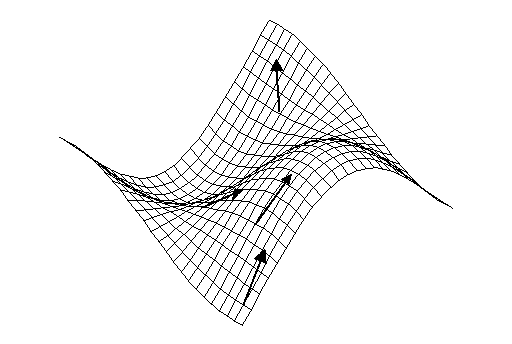
차원의 함수가 위와 같을 때, 하나의 point에는 여러 방향의 기울기가 존재합니다.
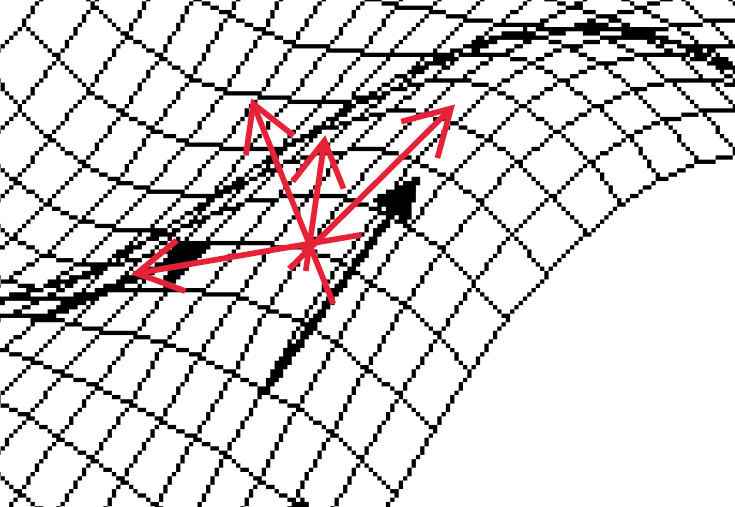
간단하게 특정 지점과 접하는 접평면을 떠올려보면 이해가 쉽습니다.
하나의 지점과 접하는 접평면은 굉장히 많을 텐데요,
이 접평면들의 기울기가 모두 한 지점에서의 기울기가 됩니다.
그리고 gradient는 이중에서 가장 steepest한 방향으로 증가하는 기울기를 말합니다.
쉽게 정리하면 가장 큰 값을 가지는 기울기가 되겠습니다.
이 gradient를 이용하여 최적해를 찾아가는 방법이 바로 Gradient Descent입니다.
Gradient Descent
최적해란 쉽게 말하면 함숫값을 최대 또는 최소로 만드는 값을 말합니다.
예시를 들자면, 에서 에 해당하는 지점이 바로 최적해입니다.
에서 값이 최소가 되기 때문입니다.
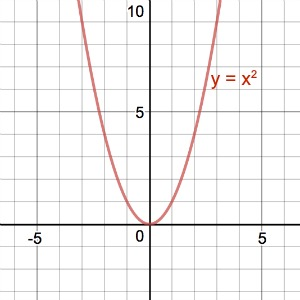
AI 모델을 학습하기 위해서는 최적해를 찾는 알고리즘이 필요합니다.
모델을 학습하는 이유는 모델이 특정 역할을 잘 수행하도록 하기 위해서입니다.
(예를 들면 사진 속 객체가 강아지인지 고양이인지 구별할 수 있는 모델이 필요해서
모델을 학습시키는 것입니다.)
모델이 특정 역할을 잘 수행하기 위해서는 input값에 대해 원하는 output을 출력하도록 모델을 학습시켜야 하는데요,
output값이 Ground Truth값(= ideal expected result)과 최대한 유사해지도록
output값과 Ground Truth값을 비교한 error값을 계산하고,
error를 줄이는 방향으로 모델을 업데이트하게 됩니다.
따라서 학습과정은 error가 최소인 지점,
즉 error function의 최적해를 찾는 과정에 해당합니다.
최적해를 찾는 알고리즘이 필요한 이유입니다.
Gradient Descent는 최적해를 찾는 대표적인 알고리즘입니다.
negative한 steepest descent 방향으로 이동하며 최적해를 찾습니다.
를 생각해보겠습니다.
최적해인 를 찾는 것이 알고리즘의 목표입니다.
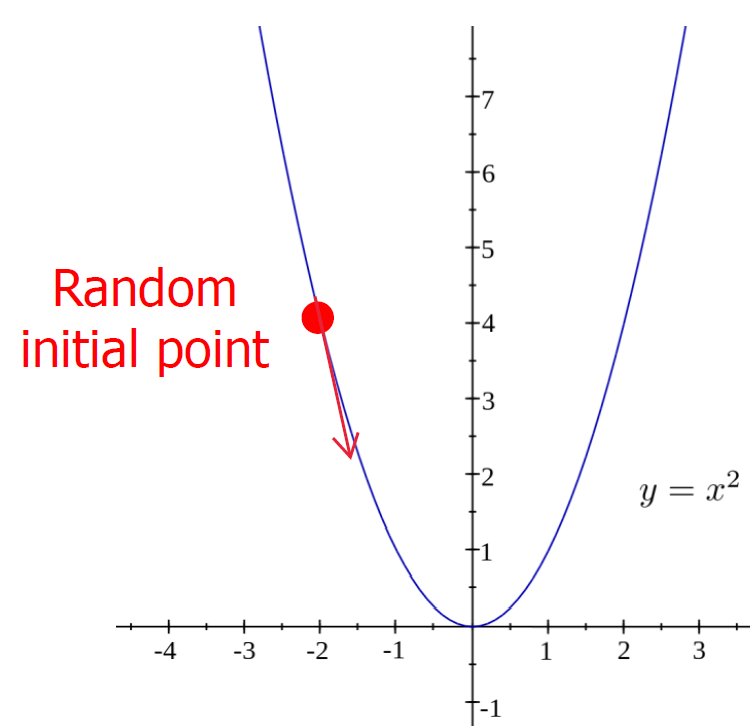
표시된 initial point에서 으로 이동하려면 표시된 화살표 방향으로 이동해야합니다.
이 방향은 initial point에서 가장 가파른 기울기() 방향이네요.
steepest한 descent 방향으로 계속해서 이동한다면 부근에 도달할 것입니다.
2차원이 아닌 차원에서도 negative한 gradient 방향으로 계속해서 이동한다면
최적해에 도달하게 됩니다.
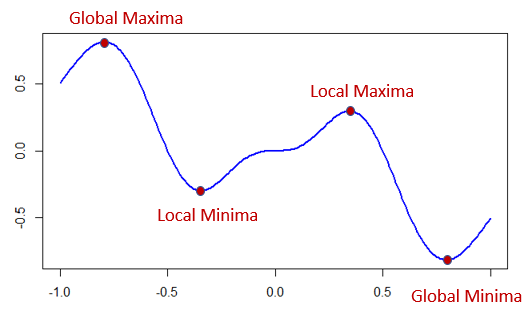
initial point를 잘못 잡는다면 최적해가 아닌 local minima에 도달할 수 있습니다.
식은 다음과 같습니다.
𝑥′ = 𝑥 − 𝜂∇𝐶
𝜂는 learning rate입니다. 모델 학습에 자주 등장하는 용어입니다.
앞서 gradient 방향으로 이동하며 최적해를 찾아준다고 설명했는데요,
gradient 방향으로 "얼마나" 이동할지 정해주는 값이 learning rate입니다.
learning rate를 너무 작게 잡아주면 최적해에 늦게 도달할 것이고,
너무 크게 잡아주면 최적해에 도달하지 못하고 진동하게 되므로 적정한 값을 잡아주는 것이 중요합니다.
∇𝐶는 함수의 gradient 벡터입니다.
error fuction을 cost function이라고도 부르기 때문에 ∇𝐶 로 표기되어있습니다.
한가지 더 중요한 것이 바로 initial point입니다.
initial point는 small random number로 잡는 것이 정론입니다.
주의할 점은 0으로 설정해서는 안됩니다.
이 부분은 뒤의 딥러닝 챕터에서 자세히 설명하도록 하겠습니다.
지금까지 AI 모델 학습에 주로 사용되는 Gradient Descent 알고리즘에 대해 살펴봤습니다.
다음은 딥러닝에 대한 개론과 과정 정리로 돌아오겠습니다.
감사합니다.
