
Case1
- 기초 전처리
- 결측치 포함 행 제거
- Customer ID, HandsetPrice 컬럼 Drop
- 라벨인코딩
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold, cross_val_score
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_scoredata1_rows = pd.read_csv('./data1.csv')
# Create an empty DataFrame
results_df = pd.DataFrame(columns=['Model', 'Accuracy', 'Precision', 'Recall', 'F1 Score'])
# Function to add results to the DataFrame
def df_add(model_name, y_test, pred):
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
f1 = f1_score(y_test, pred)
results_df.loc[len(results_df)] = [model_name, accuracy, precision, recall, f1]
X = data1_rows.drop(columns=['Churn'])
y = data1_rows['Churn']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=70)
models = []
models.append(('RandomForestClassifier', RandomForestClassifier()))
models.append(('DecisionTreeClassifier', DecisionTreeClassifier()))
models.append(('AdaBoostClassifier', AdaBoostClassifier()))
models.append(('GradientBoostingClassifier', GradientBoostingClassifier()))
models.append(('LogisticRegression', LogisticRegression()))
for name, model in models:
kfold = KFold(n_splits=5, random_state=70, shuffle=True)
cv_results = cross_val_score(model, X_train, y_train, cv=kfold, scoring='accuracy')
model.fit(X_train, y_train)
pred = model.predict(X_test)
df_add(name, y_test, pred)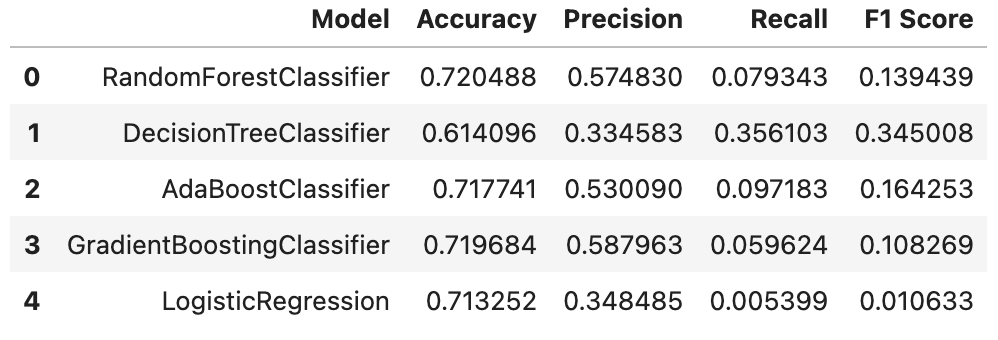

21세기 주인공