
로지스틱 회귀 실습
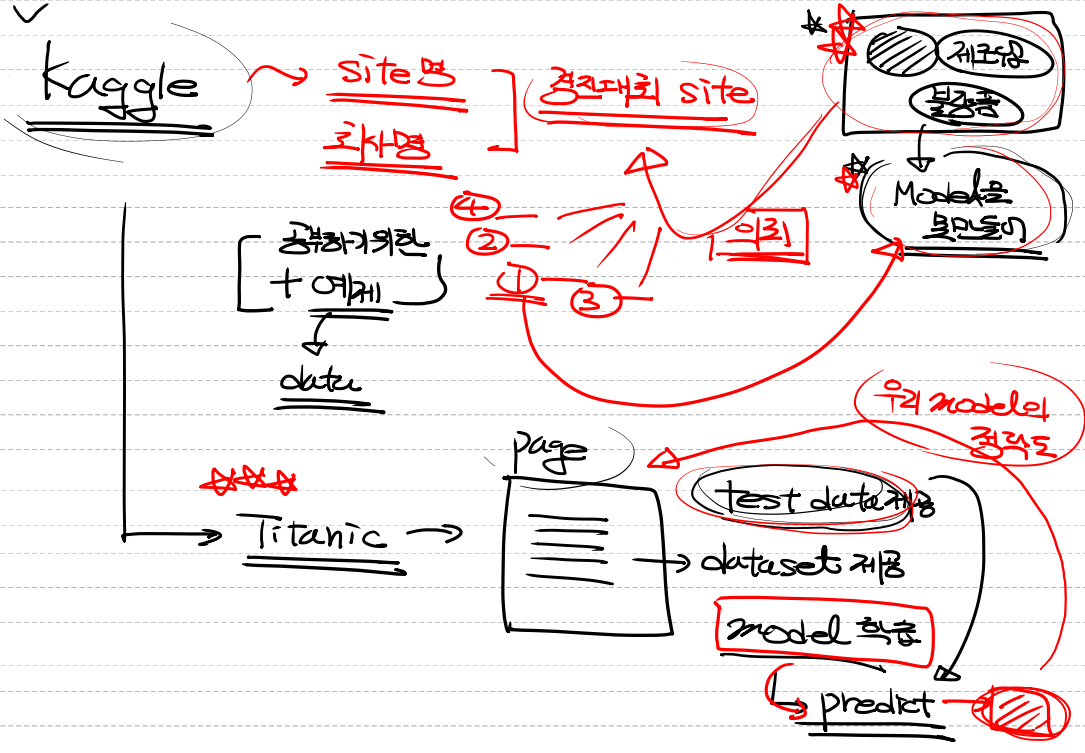
- kaggle을 이용한다.
유방암 데이터로 실습하기
1. 필요한 module import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn import linear_model
from sklearn.model_selection import cross_val_score
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.optimizers import Adam2. 데이터 로드 및 전처리
# Imbalanced Data Problem을 해결해 보아요!
# SMOTE 알고리즘을 이용해 보아요!
# 불균형한 데이터가 있어야 해요!
# 유방암 예측 데이터셋으로 해 보아요!
# Raw Data Loading
cancer = load_breast_cancer()
# x_data(feature), t_data(0, 1), 데이터의 설명, .....
# x_data => cancer.data
# t_data => cancer.target
print(cancer.data.shape, cancer.target.shape)
# (569, 30) => x_data는 총 569개의 행으로 구성, 컬럼(feature)은 30개
# (569,) => t_data 역시 총 569개 있어요. 0과 1로 구성되어 있어요!
print(np.unique(cancer.target, return_counts=True))
# (array([0, 1]), array([212, 357]))
# 0.37, 0.63
# 0은 악성종양(나쁜거), 1은 양성종양(괜찮은거)
# 약간의 데이터 불균형이 존재.(imbalanced data)
# 데이터셋 저장
x_data = cancer.data
t_data = cancer.target
# boxplot을 이용해서 이상치와 데이터 분포를 간단하게 확인!
# plt.boxplot(x_data)
# plt.show()
# 데이터 정규화가 필요해요!
# 원래 정규화는 당연히 이상치를 제거하고 진행하는게 맞아요!
# 실제적인 이상치는 존재하지 않는다고 가정하고 진행!
scaler = MinMaxScaler()
scaler.fit(x_data)
x_data_norm = scaler.transform(x_data)
# 데이터를 분리해야 해요! 학습용과 평가용으로 분리
# train data와 test data로 분리(데이터를 섞어서 분리)
x_data_train_norm, x_data_test_norm, t_data_train, t_data_test = \
train_test_split(x_data_norm,
t_data,
stratify=t_data,
test_size=0.2, # default값은 0.25
random_state=3)
# 섞어서 분리했기 때문에 데이터의 편향이 없을거라 생각되는데
# 확인은 해야 겠죠.
np.unique(t_data_test, return_counts=True )
# (array([0, 1]), array([42, 75])) # 35% , 65%3. sklearn, Tensorflow 구현
sklearn
# sklearn model 구현
sklearn_model = linear_model.LogisticRegression()
# 학습하기 전에 cross validation을 한번 수행해 볼꺼예요!
# train data를 가지고 수행해요!
score = cross_val_score(sklearn_model,
x_data_train_norm,
t_data_train,
cv=5)
print(score)
# [0.97802198 0.94505495 0.95604396 0.98901099 0.94505495]
print(f'sklearn의 평균 validation accuracy : {np.mean(score)}')
# 0.9626373626373625
# 학습진행
sklearn_model.fit(x_data_train_norm,
t_data_train)
# 모델최종평가
test_score = sklearn_model.score(x_data_test_norm,
t_data_test)
print(f'모델의 최종 score : {test_score}') # 0.9649Tensorflow
# Tensorflow 구현
keras_model = Sequential()
keras_model.add(Flatten(input_shape=(30,)))
keras_model.add(Dense(units=1,
activation='sigmoid'))
# 학습할 때 매 epoch마다 validation을 수행하고
# validation의 평가 기준은 accuracy를 사용하겠어요!
keras_model.compile(optimizer=Adam(learning_rate=1e-1),
loss='binary_crossentropy',
metrics=['acc'])
keras_model.fit(x_data_train_norm,
t_data_train,
epochs=300,
verbose=1,
validation_split=0.2)
# Epoch 300/300
# 12/12 [==============================] - 0s 6ms/step
# - loss: 0.0437 - acc: 0.9890 - val_loss: 0.1034 - val_acc: 0.9560
# training data로 학습한 후
# training data로 평가 vs. validation data로 평가
# loss : training data로 학습한 후 training data를 이용해서 계산한 loss
# val_loss : validation data로 계산한 loss
# 학습이 다 끝났어요!
# Evaluation(평가)
result = keras_model.evaluate(x_data_test_norm,
t_data_test)
print(result)
# loss값 accuracy값
# [0.1397516131401062, 0.9649122953414917]
타이타닉 데이터
1. 필요한 module import
# Titanic data를 이용한 Logistic Regression 구현
# Kaggle에 있는 데이터를 이용.
# Kaggle에 있는 데이터를 전처리 한 후
# 모델을 만들어서 학습을 진행
# 자체 평가를 진행(validation)
# 모델을 이용해서 예측값을 추출(test.csv)
# 예측된 결과를 kaggle에 upload해서 우리 모델의 성능을 검증.
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.optimizers import Adam2. 데이터 로드 및 전처리
# Raw Data Loading
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/ML/data/titanic/train.csv')
# display(df) # 891 rows × 12 columns
# 데이터 전처리!(feature engineering)
train = df
# 사용하는 coulmn만 추출. 사용되지 않는(불필요한) column을 삭제
# print(train.columns)
# 필요없는 컬럼은(종속변수에 영향을 주지 않거나 의미상 중복 컬럼)
train.drop(['PassengerId', 'Ticket', 'Name', 'Fare', 'Cabin'],
axis=1,
inplace=True)
# display(df)
# 성별처리 (male:0, female:1)
gender_mapping = {'male': 0,
'female': 1}
train['Sex'] = train['Sex'].map(gender_mapping)
train['Family'] = train['SibSp'] + train['Parch']
train.drop(['SibSp', 'Parch'],
axis=1,
inplace=True)
# df.info()
# Embarked의 결측치를 처리해 보아요!
train['Embarked'] = train['Embarked'].fillna('Q')
# Embarked 처리
Embarked_mapping = {'S': 0,
'C': 1,
'Q': 2}
train['Embarked'] = train['Embarked'].map(Embarked_mapping)
# 나이를 처리해야 해요! 나이에는 결측치가 많아요!
train['Age'] = train['Age'].fillna(train['Age'].mean())
# 나이에 대해서는....Binning 처리를 해요!
train.loc[train['Age'] < 8, 'Age'] = 0
train.loc[(train['Age'] >= 8) & (train['Age'] < 20), 'Age'] = 1
train.loc[(train['Age'] >= 20) & (train['Age'] < 65), 'Age'] = 2
train.loc[train['Age'] >= 65, 'Age'] = 3
x_data = train.drop('Survived', axis=1, inplace=False).values
t_data = train['Survived'].values.reshape(-1,1)
# 정규화!
scaler = MinMaxScaler()
scaler.fit(x_data)
x_data_norm = scaler.transform(x_data)
# train데이터와 test데이터를 분리하나요?
# 원래 내가 만든 모델의 최종 평가를 하기 위해서는 test데이터가 당연히 있어야 해요!
# 하지만 우리예제는 kaggle에서 제공한 test데이터를 이용한 예측결과값을
# 파일로 만들어서 kaggle에 제출하는 것이기 때문에 test 데이터가 필요 없어요!3. 모델 학습
# Keras Model을 만들어 보아요!
keras_model = Sequential()
keras_model.add(Flatten(input_shape=(5,)))
keras_model.add(Dense(units=1,
activation='sigmoid'))
keras_model.compile(optimizer=Adam(learning_rate=1e-2),
loss='binary_crossentropy',
metrics=['acc'])
keras_model.fit(x_data_norm,
t_data,
epochs=300,
verbose=1,
validation_split=0.2)
# loss: 0.4550 - acc: 0.7992 - val_loss: 0.3913 - val_acc: 0.82124. kaggle에 제출할 파일 생성하기
# 학습이 끝났으니... 제출파일을 생성해야 해요!
# 모델이 만들어 졌으니 test 데이터로 예측된 결과를 csv파일로
# 만들어서 kaggle에 제출하고 그 결과를 확인해보아요!
# 어떻게 해야 할까요
test = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/ML/data/titanic/test.csv')
submission = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/ML/data/titanic/gender_submission.csv')
# test 데이터 전처리
# 사용하는 coulmn만 추출. 사용되지 않는(불필요한) column을 삭제
# print(train.columns)
# 필요없는 컬럼은(종속변수에 영향을 주지 않거나 의미상 중복 컬럼)
#
test.drop(['PassengerId', 'Ticket', 'Name', 'Fare', 'Cabin'],
axis=1,
inplace=True)
# 성별처리 (male:0, female:1)
gender_mapping = {'male': 0,
'female': 1}
test['Sex'] = test['Sex'].map(gender_mapping)
test['Family'] = test['SibSp'] + test['Parch']
test.drop(['SibSp', 'Parch'],
axis=1,
inplace=True)
# df.info()
# Embarked의 결측치를 처리해 보아요!
test['Embarked'] = test['Embarked'].fillna('Q')
# Embarked 처리
Embarked_mapping = {'S': 0,
'C': 1,
'Q': 2}
test['Embarked'] = test['Embarked'].map(Embarked_mapping)
# 나이를 처리해야 해요! 나이에는 결측치가 많아요!
test['Age'] = test['Age'].fillna(test['Age'].mean())
# 나이에 대해서는....Binning 처리를 해요!
test.loc[test['Age'] < 8, 'Age'] = 0
test.loc[(test['Age'] >= 8) & (test['Age'] < 20), 'Age'] = 1
test.loc[(test['Age'] >= 20) & (test['Age'] < 65), 'Age'] = 2
test.loc[test['Age'] >= 65, 'Age'] = 3
# display(test)
x_data_test_norm = scaler.transform(test.values)
predict = keras_model.predict(x_data_test_norm)
# print(predict)
submission['Survived'] = predict
submission['Survived'] = np.where((submission['Survived'] >= 0.5), 1, 0)
submission.to_csv('./sub.csv', index=False)
예제로는 77.75%가 나온 모습이다.

XD