
회귀(Regression)
우리는 지난날에 회귀에 대해 기본적인 틀을 알아보았다.
정리를 하자면 회귀는 조건부 평균을 구하는 방법이며 평균을 구하는 식(Regression Model(회귀 모델))을 우리가 찾아내는 것이다.
- 평균을 구하는 기법이기때문에 평균이 의미를 가지는 Data에 대해 회귀 모델이 더 잘 만들어집니다.
- 단변량을 가정합니다
- 기반 모델은 고전적 선형 회귀 모델(Classical Linear Regression Model)을 사용합니다

- 회귀는 Target(Label)의 형태에 따라 종류가 나뉩니다.
- 연속적인 숫자값 :Linear Regression(선형 회귀)
- 이산적인 분류값 : Classification(분류) ex) Logistic Regression
그림으로 보게되면
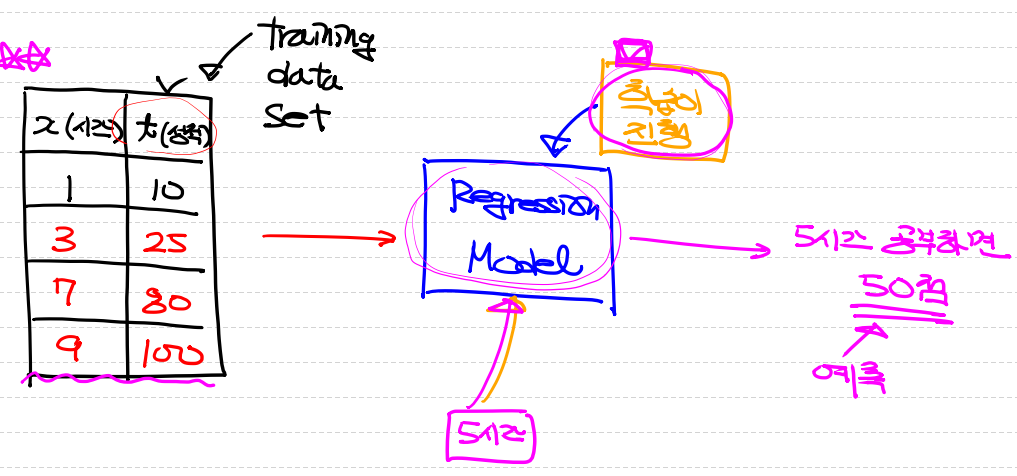
위와 같이 입력에 데이터 셋을 모델에 넣고 예측을 하게 됩니다.
이때의 식은 아래와 같습니다.
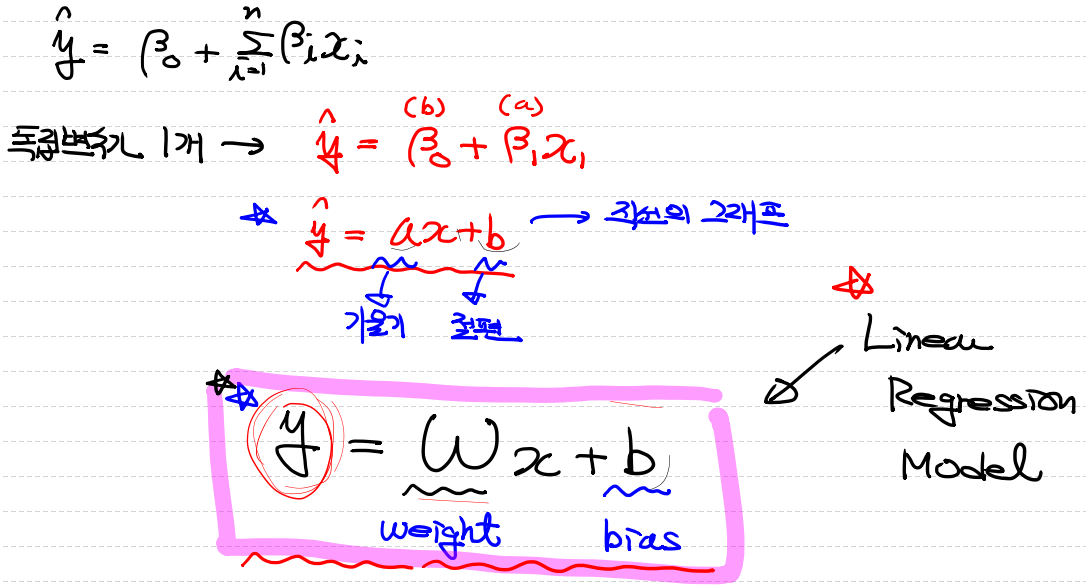
오차(Error)
- 회귀 모델은 결과적으로 우리가 어떤 값을 넣게 되면 그 값이 어떤 값이 나오는지 예측하는 것입니다.
- 모델이 좋으면 평균과 오차가 적으면 좋을 것 입니다.
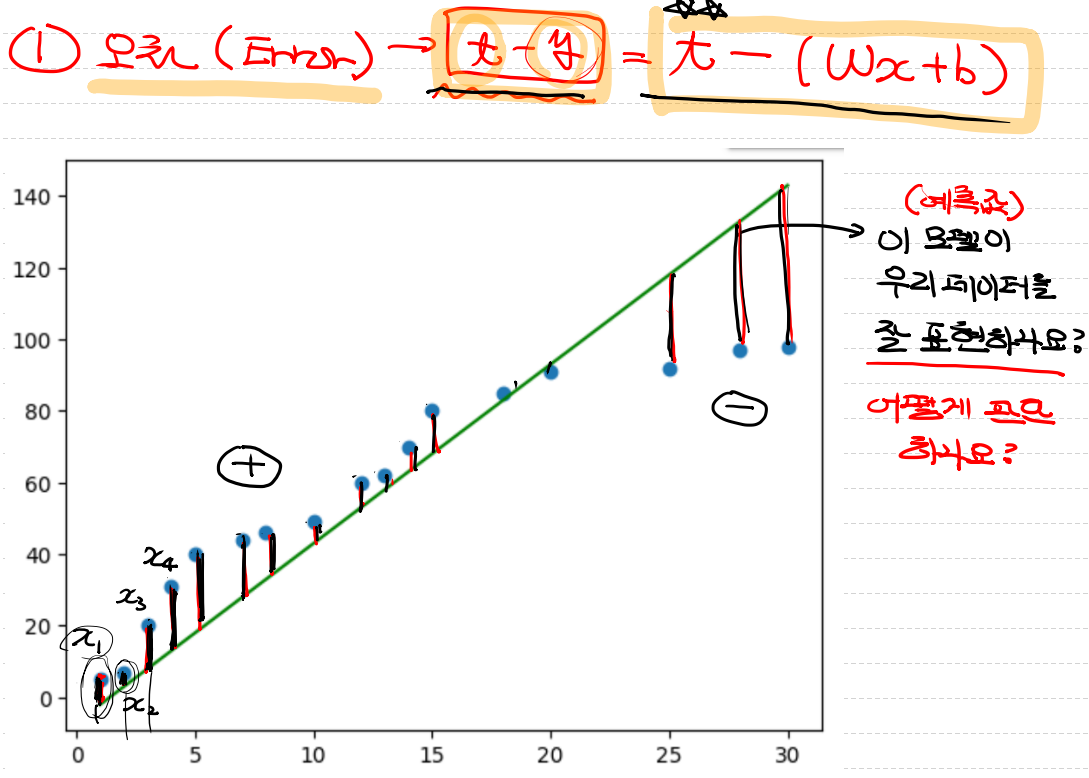
위의 그림처럼 평균선에 대해서 크면+작으면-로 나타낼 수 있습니다.
우리는 여기서 이 오차를 하나의 값으로 계산을 하려고 합니다.
오차 함수(Loss function)
- 여기서 예측값과 실제값의 차이를 나타내는 매커니즘을 오차 함수라고 표현합니다.
Loss 함수를 만드는 방법입니다.
- error를 더한다 -> 부호때문에 이상적인 loss값으로 사용하기 힘듭니다. X
- error의 절대값의 합을 구한다. -> 좋습니다! loss값을 이 방식으로 계산할 수 있습니다. O
- error의 제곱의 평균을 구한다 -> 평균 제곱 오차(Mean Squared Error) O
오차 함수와 학습률
여기서 모델과 오차의 식을 보겠습니다
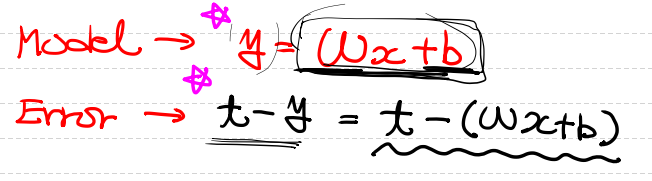
여기서 수학식으로 대입을 하여 바꿔주면

위와 같은 그림에서 식이 완성되게 됩니다.
loss는 모든 데이터에 대한 평균 오차값이라고도 할 수 있습니다.
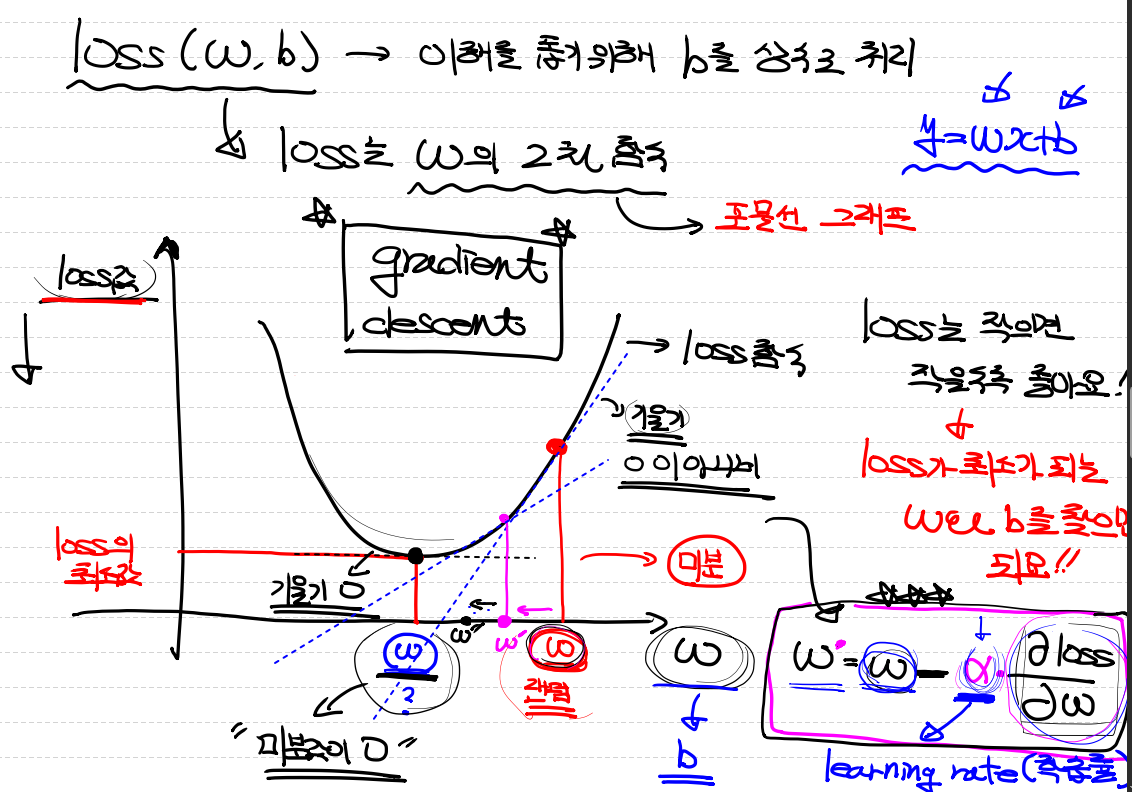
loss는 W의 2차함수이고, 이 그래프는 포물선 그래프입니다.
loss는 작으면 작을수록 좋기때문에 loss가 최소가 되는 w ~ b를 찾으면 됩니다.
- W에서의 값에서의 미분을 하게 되면 해당 지점의 기울기를 나타냅니다.
- 그 값이 포물선의 중앙에 오게 되면은 평평해지며 기울기가 0이 됩니다.
- 기울기 식은 학습률(learning rate)와 관련이 있습니다.
- 미분을 하면서 가장 최적의 값을 찾으려고 내려가기때문입니다.
이걸 경사 하강(gradient descent)라고 한다.
구현 flow
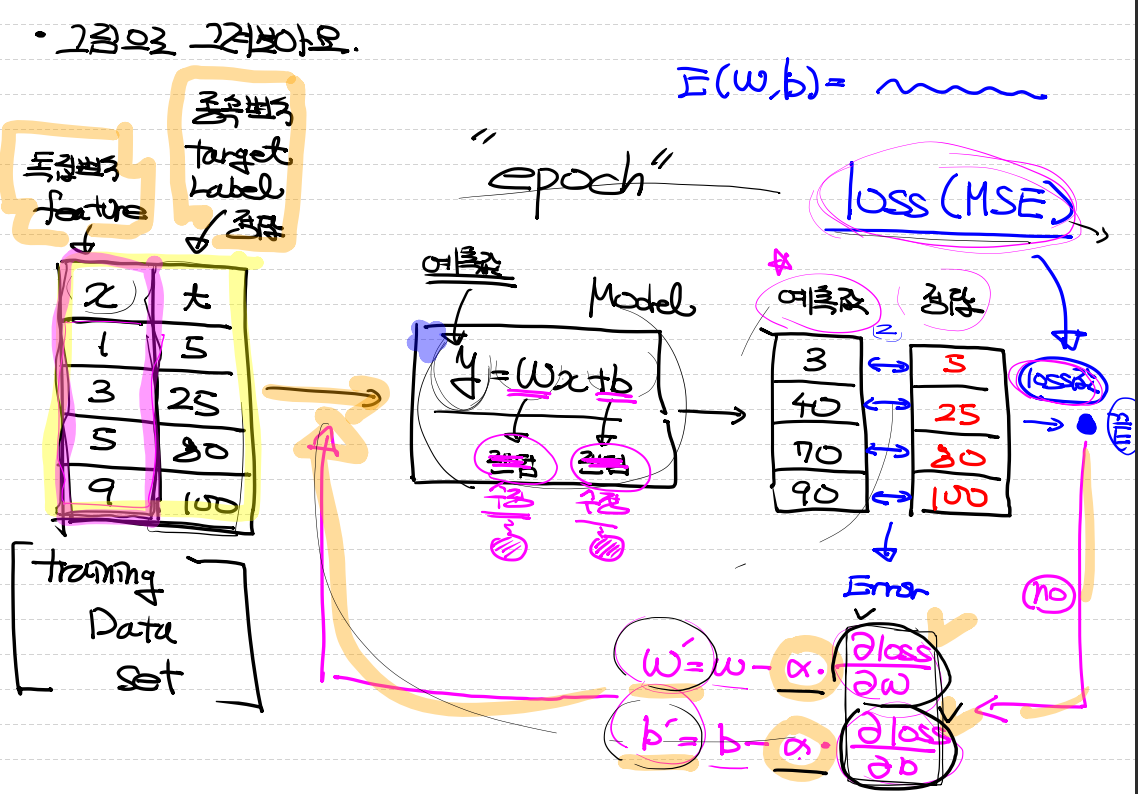
1. feature와 label이 같이 있는 데이터를 입력하고 Model을 거쳐 예측값과 정답을 비교한다.
2. loss 함수를 learning rate만큼 거쳐서 오차범위를 줄이고, 다시 모델로 들어간다 이 한바퀴 반복 과정을 Epoch이라고 한다.
3. 설정한 Epoch을 거쳐 모델의 학습이 완료된다.
구현 flow 수식
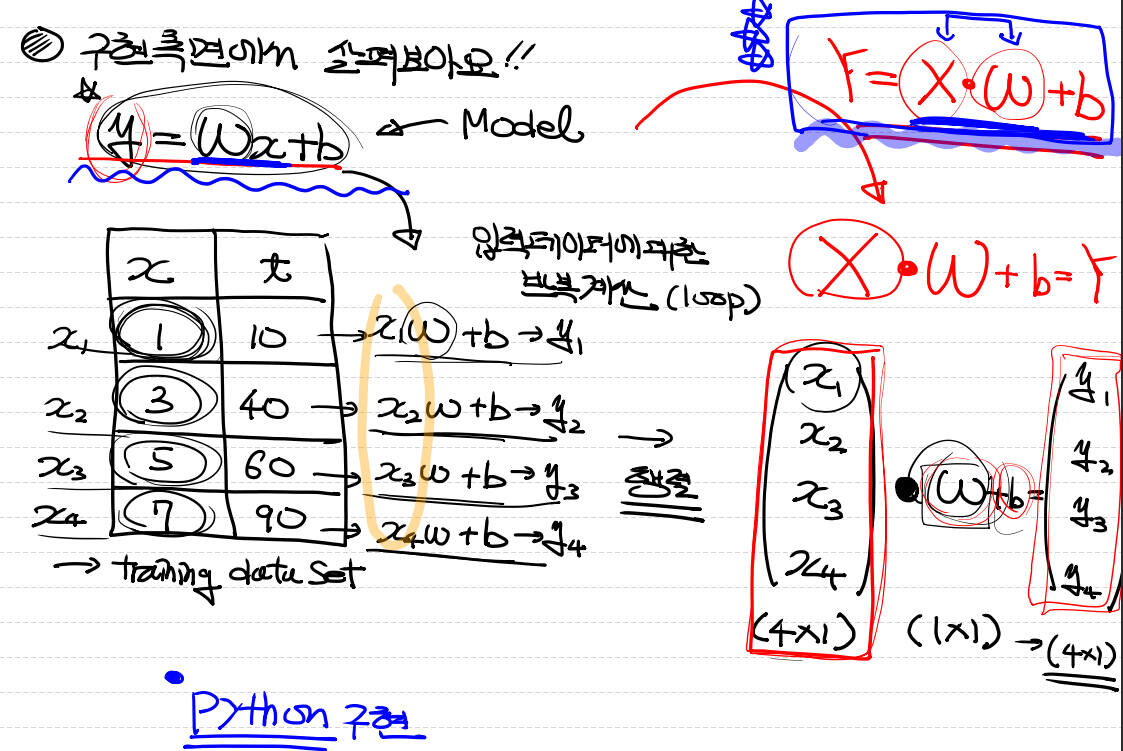
모델의 식에 입력 데이터 값인 x1,x2,x3,x4에 값이 들어가고, 그 값에 가중치와 bias가 더해지면서 값이 나오게된다.
이렇게 반복하게 되면서 모델이 생성된다.
Tensorflow
Tensorflow란
- open source library
- 수치계산용 library
- data flow graph를 이용해서 Tensor처리(다차원 data)
Keras
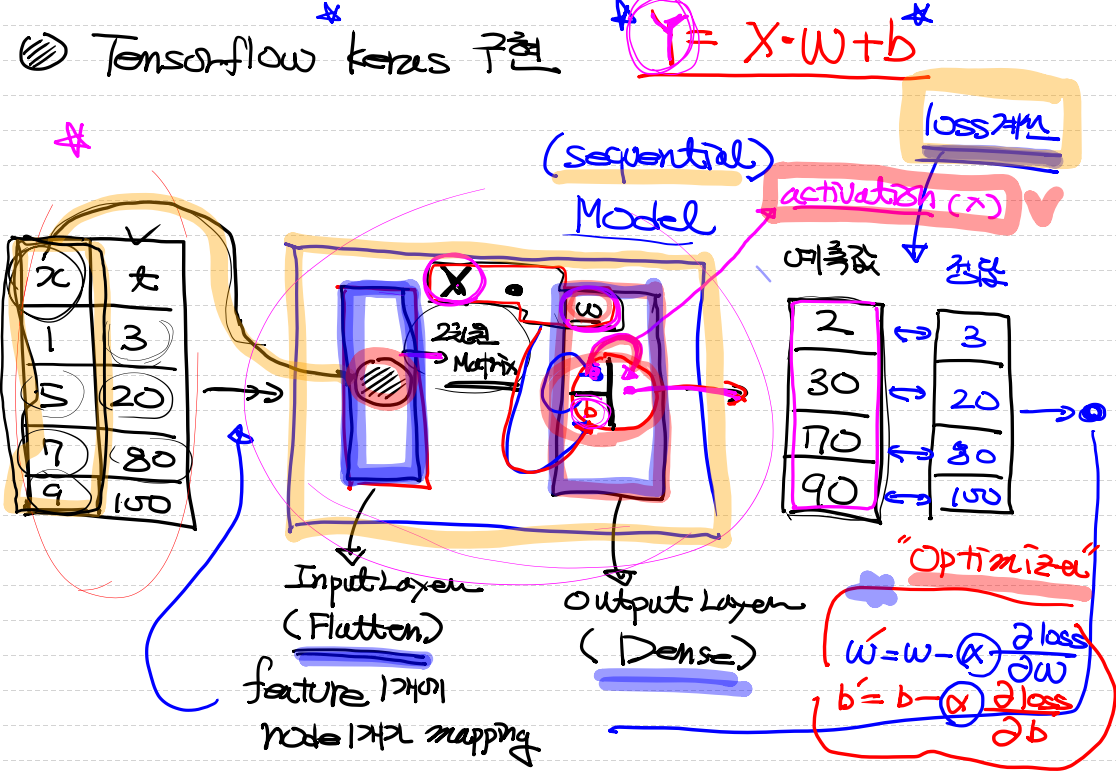
1. Tensorflow keras 구현은 상자(Sequential)모델 2차원 matrix에서 input_layer(Flatten)를 통해 feature 1개에 모델이 하나가 mapping이되서 들어가고
2. output_layer(Dense)에서 W가중치가 계산이 되고, bias가 더해진 후 actvation이 추가로 계산되어 밖으로 나가게된다.
3. 그 후 예측값과 정답을 비교하고 설정해둔 optimizer를 통해 다시 epoch을 돌게된다.
파이썬 구현
간단 선형 회귀
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({'공부시간(x)': [1,2,3,4,5,7,8,10,12,13,14,15,18,20,25,28,30], '시험점수(t)':[5,7,20,31,40,44,46,49,60,62,70,80,85,91,92,97,98]})
display(df.head())
plt.scatter(df['공부시간(x)'],df['시험점수(t)'])
plt.plot(df['공부시간(x)'], df['공부시간(x)']*2 + 3, color='r')
plt.plot(df['공부시간(x)'], df['공부시간(x)']*5 - 7, color='g')
plt.plot(df['공부시간(x)'], df['공부시간(x)']*1 + 8, color='b')
plt.plot(df['공부시간(x)'], df['공부시간(x)']*4 - 10, color='magenta')
plt.show()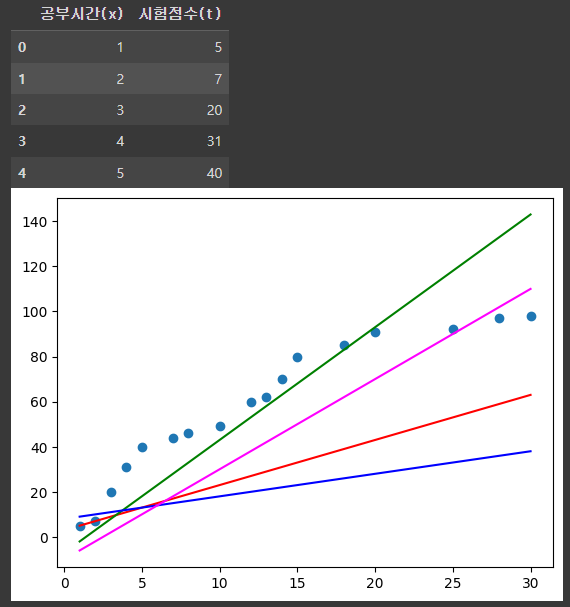
import numpy as np
# Training Data Set
x_data = np.array([1,2,3,4,5]).reshape(5,1)
t_data = np.array([3,5,7,9,11]).reshape(5,1)
# model => y = Wx + b
# rand() => 0과 1사이의 난수를 균등분포에서 발생시켜요!
W = np.random.rand(1,1)
b = np.random.rand(1)
# loss function
def loss_func(input_data):
input_W = input_data[0]
input_b = input_data[1]
# Y = XW + b
y = np.dot(x_data, input_W) + input_b
return np.mean(np.power((t_data - y), 2))
# 미분해주는 함수가 있어야 해요!
def numerical_derivative(f,x):
# f : 미분하려고하는 다변수 함수
# x : 모든 변수를 포함하는 ndarray [1.0 2.0]
# 리턴되는 결과는 [8.0 15.0]
delta_x = 1e-4
derivative_x = np.zeros_like(x) # [0.0 0.0]
it = np.nditer(x, flags=['multi_index'])
while not it.finished:
idx = it.multi_index # 현재의 index를 추출 => tuple형태로 리턴.
tmp = x[idx] # 현재 index의 값을 일단 잠시 보존해야해요!
# 밑에서 이 값을 변경해서 중앙차분 값을 계산해야 해요!
# 그런데 우리 편미분해야해요. 다음 변수 편미분할때
# 원래값으로 복원해야 편미분이 정상적으로 진행되기 때문에
# 이값을 잠시 보관했다가 원상태로 복구해야 해요!
x[idx] = tmp + delta_x
fx_plus_delta_x = f(x) # f(x + delta_x)
x[idx] = tmp - delta_x
fx_minus_delta_x = f(x) # f(x - delta_x)
derivative_x[idx] = (fx_plus_delta_x - fx_minus_delta_x) / (2 * delta_x)
x[idx] = tmp
it.iternext()
return derivative_x
# 학습이 다 종료되면(모델이 다 만들어지면)
# 예측작업을 해야 해요! 그래서 예측을 해주는 함수를 하나 정의
def predict(x):
return np.dot(x,W) + b
# learning rate 정의
learning_rate = 1e-4
# 학습을 진행
for step in range(300000):
# 현재 W는 2차원, b는 1차원이예요!
# 그런데 이게 loss함수안으로 들어갈때는 1차원 안에 두 값이
# 순서대로 들어가 있어야 해요!
input_param = np.concatenate((W.ravel(), b.ravel()), axis=0)
derivative_result = learning_rate * numerical_derivative(loss_func, input_param)
W = W - derivative_result[0].reshape(-1,1)
b = b - derivative_result[1]
# 확인작업
if step % 30000 == 0:
print(f'W : {W}, b: {b}, loss: {loss_func(input_param)}')
# W: [[0.8533673]], b: [0.10691388], loss: 21.505695738228287
# W: [[2.05368836]], b: [0.806168], loss: 0.006839013386449011
# W: [[2.0194703]], b: [0.92970603], loss: 0.0008994533618923671
# W: [[2.00706099]], b: [0.9745076], loss: 0.00011829430716160621
# W: [[2.0025607]], b: [0.99075508], loss: 1.5557830677745438e-05
# W: [[2.00092865]], b: [0.99664729], loss: 2.0461347735503135e-06
# W: [[2.00033678]], b: [0.99878413], loss: 2.691035529462717e-07
# W: [[2.00012213]], b: [0.99955906], loss: 3.5391961050585345e-08
# W: [[2.00004429]], b: [0.99984009], loss: 4.6546799299037875e-09
# W: [[2.00001606]], b: [0.99994201], loss: 6.121741945875743e-10
# 결과 예측하기 7을 넣었을때의 값
predict_result = predict(np.array([7]).reshape(1,1))
print(predict_result) # [[15.00001975]]Tensorflow 구현
# Tensorflow Keras 구현
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.optimizers import SGD
# Training Data Set
x_data = np.array([1,2,3,4,5]).reshape(5,1)
t_data = np.array([3,5,7,9,11]).reshape(5,1)
# Model 생성
model = Sequential()
# Model 안에 layer를 생성
# Flatten == input_layer
# input_shape안에는 반드시 tuple이 들어가야함
# 1이라는건 feature를 의미
# activation 함수 설정
model.add(Flatten(input_shape=(1,)))
model.add(Dense(units=1, activation="linear"))
# 모델이 완성되었으면 기타 옵션들을 설정해야 한다.
# 어떤 최적화 알고리즘 방식을 사용할지 설정하는 optimizer
# learning_rate도 같이 설정
# loss는 평균제곱오차 mse를 사용
model.compile(optimizer=SGD(learning_rate=1e-2), loss='mse')
# 모델 학습
model.fit(x_data,
t_data,
epochs=5000,
verbose=0)
# 예측을 해 보아요!
print(model.predict(np.array([[10]]))) # [[21.000032]]sklearn 구현
# sklearn을 이용해 해보자
# sklearn은 일반사람들도 쉽고 편하게 머신러닝을 할 수 있도록
# 모델을 제공해줘요!
import numpy as np
from sklearn import linear_model
# Training Data Set
x_data = np.array([1,2,3,4,5]).reshape(5,1)
t_data = np.array([3,5,7,9,11]).reshape(5,1)
sklearn_model = linear_model.LinearRegression()
sklearn_model.fit(x_data,
t_data)
print(sklearn_model.predict(np.array([[10]]))) # [[21.]]Ozone 데이터 실습 예제
# ozone.csv 파일을 이용해서 머신러닝 모델을 만들어 보아요
# python 구현
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 수치미분함수가 있어야함
# 수치미분함수.
def numerical_derivative(f, x):
delta_x =1e-4
derivative_x = np.zeros_like(x) # [0.0, 0.0]
it = np.nditer(x, flags=['multi_index'])
while not it.finished:
idx = it.multi_index # 현재의 index를 추출 => tuple형태로 리턴
tmp = x[idx] # 현재 index의 값을 일단 잠시 보존해요.
# 밑에서 이 값을 변경해서 중앙차분 값을 계산해야함
# 그런데 우리 편미분을 해야하는데 다음 변수 편미분을 할때에
# 원래값으로 복원해야 정상적으로 진행되기 때문에
# 이 값을 잠시 보관했다가 원상태로 복구해야함
x[idx] = tmp + delta_x
fx_plus_delta_x = f(x) # f(x + delta_x)
x[idx] = tmp - delta_x
fx_minus_delta_x = f(x)
derivative_x[idx] = (fx_plus_delta_x - fx_minus_delta_x) / (2 * delta_x)
x[idx] = tmp
it.iternext()
return derivative_x
# Raw Data Loading
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/ML/data/ozone/ozone.csv')
# display(df)
# 아직은 simple linear regression 얘기를 하는 중이기 때문에
# 독립변수를 1개만 사용할것. ==> Temp
# 종속변수는 Ozone을 사용
# 그러면 먼저 사용할 데이터를 추출해보자
training_data = df[['Temp', 'Ozone']]
# display(training_data) # 153 rows × 2 columns
# 데이터 처리를 좀 해야함
# 결측치 처리를 해야함
# 이런 결측치 처리하는 방식이 두가지 있음
# 1. 결측치 삭제
# 데이터량이 충분히 많을때 삭제
# 일반적으로 총 데이터가 10만개를 기준으로 데이터가 많고 적음을 삼음
#
# 2. 결측치 대체 => imputation 진행
# 데이터량이 충분하지 않은경우
# 그럼 어떤값으로 대체하는가 => 평균 중위 최빈
#
# 머신러닝을 이용해서 값을 대체
# 삭제해서 사용해보자
training_data = training_data.dropna(how='any')
display(training_data) # 116 rows × 2 columns