🏓 들어가며...
머신러닝에서 Object Detection을 하기 위해서는 이미지 데이터가 중요합니다.
물론, 원하는 데이터가 있다면 좋겠지만 없다면 그 데이터를 직접 만들 수 있어야 겠죠?
해당 과정이 귀찮기는 필요성은 확실합니다. 그런데, 무지한 과거의 저처럼 혹시나 원하는 이미지 데이터를 만들지 못하시는 분들을 위해서 이번 포스트에서는 간단하게 데이터를 만들 수 있는 방법에 대해 소개해드리려고 합니다!
🧄 라벨링 프로그램
https://github.com/heartexlabs/labelImg/releases
이미지 데이터를 만들려면 라벨링 과정이 반드시 필요합니다.
예를 들어 제가 좋아하는 고양이를 판별하는 모델을 학습시키기 위해 데이터를 만드는 상황을 가정해봅시다.
사람은 물론 사진에 고양이가 있는지 없는지를 한 번에 보면 알 수 있지만(마치 YOLO 처럼), 모델 학습을 위해서는 해당 사진에 고양이가 있다면 어디에 있는지를 알려주는 작업이 필요할 것입니다.
이를 도와주는 프로그램이 위에 깃허브 링크에 존재합니다.
(위의 프로그램은 윈도우 버전입니다. 참고해주세요~)
다운을 받고 압축을 풀면 아래와 같은 폴더가 보일 것입니다.
해당 폴더에 들어가면 아래와 같이 실행할 수 있는 라벨링 프로그램이 위치하고 있음을 알 수 있습니다.

🦠 라벨링 (with 이미지 데이터)

프로그램을 실행시키면 위와 같은 사진이 나올 것입니다.
먼저 Open Dir을 선택해서 라벨링할 이미지를 선택합니다.
그 다음으로는 Change Save Dir을 선택해서 라벨링 결과를 저장할 폴더를 지정합니다.(참고로, 보통은 이미지와 같은 위치에 넣어야 나중에 학습할 때 편할 것입니다.)

이렇게 귀여운 고양이 사진이 나왔다면, w 버튼을 눌러서 바운딩 박스를 생성합니다.
바운딩 박스를 생성 완료하면 해당 부분을 무엇으로 학습할지 지정할 수 있습니다.(저는 오른쪽에 보이는 것처럼 cat이라고 지정했습니다.)

바운딩 박스 지정 이후에는 save 버튼을 클릭해서 라벨링 결과를 저장할 수 있습니다.
만약 다음 이미지가 존재하거나 이전 이미지를 다시 라벨링하고 싶은 경우는 당연히 Next Image 와 Prev Image 를 통해 조작할 수 있습니다.
🍕 결과 확인
결과를 저장한 위치에 가면 각 이미지와 동일한 이름으로 라벨링 결과가 저장된 모습을 확인할 수 있습니다. 한 번만 열어서 확인해 보겠습니다.

간단하게 설명드리면, width와 height, 그리고 두 개의 (x,y)로 구성된 좌표 값이 저장됨을 알 수 있습니다.
🪰 결과 활용
위에서 나온 것처럼 결과는 XML 파일로 나오게 되는데, 이걸 바로 사용하라고 하면 아무리 똑똑한 컴퓨터라도 당황스럽겠죠?
그래서 이를 원하는 형식으로 변환할 수 있도록 아래의 코드를 사용해 줍니다.
# 함수 가져오기
# 라벨링 툴을 써서 위치를 구했고, 그 결과가 XML 형식으로 도출
# 도출된 XML에서 좌표 값 등 필요한 부분만 뽑아쓰기 위한 함수
def xml_to_csv(path):
print(path)
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
bbx = member.find('bndbox')
xmin = int(bbx.find('xmin').text)
ymin = int(bbx.find('ymin').text)
xmax = int(bbx.find('xmax').text)
ymax = int(bbx.find('ymax').text)
label = member.find('name').text
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
label,
xmin,
ymin,
xmax,
ymax
)
xml_list.append(value)
column_name = ['filename', 'width', 'height',
'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df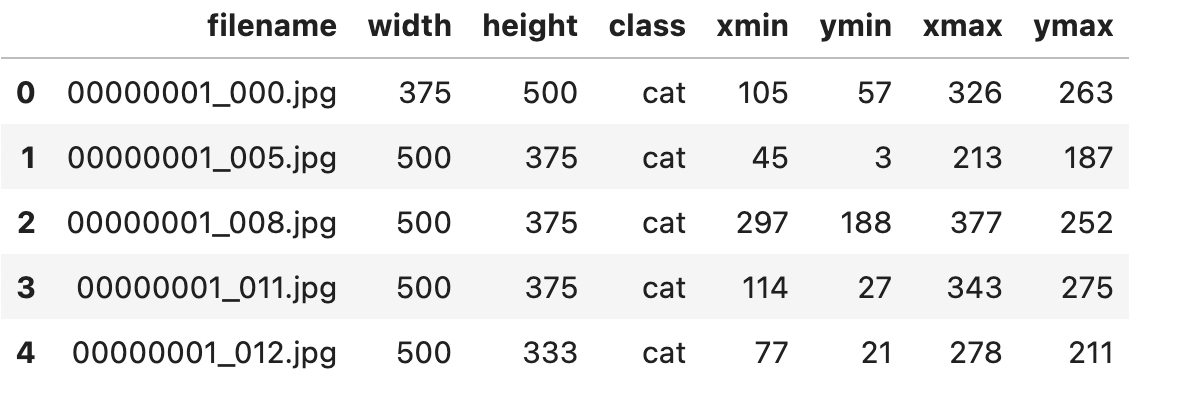
변환이 성공하면 위와 같이 원하는 데이터만 쏘옥 뽑아 오는 것이 가능할 것입니다.