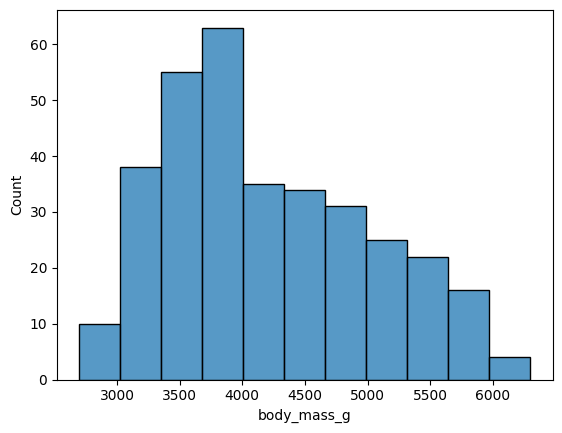
Histplot
히스토그램을 출력하는 plot!
전체 데이터를 특정 구간별 정보를 확인할 때 사용
ex) sns.histplot(data = data, x = 'body_mass_g)
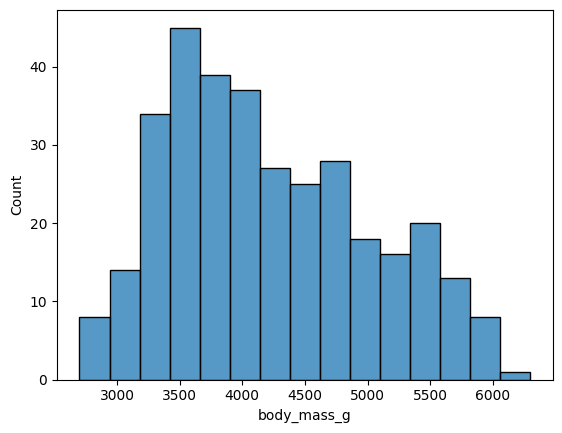
히스토그램은 bins 옵션으로 구간의 개수에 따라 분포를 다르게 표현할 수 있음
ex) sns.histplot(data = data, x = 'body_mass_g', bins = 15)
또한 범례를 추가하여 볼 수도 있다
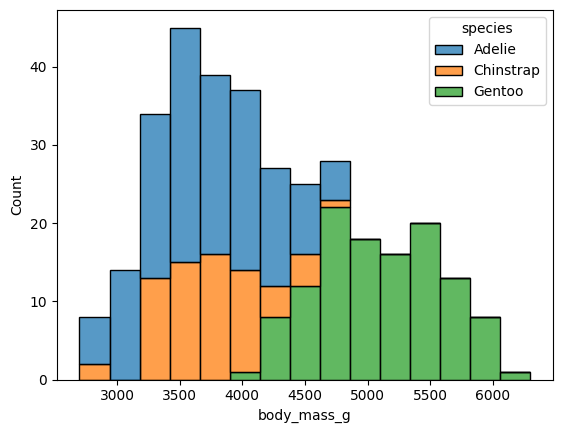
ex) sns.histplot(data = data, x = 'body_mass_g', bins = 15, hue = 'species')
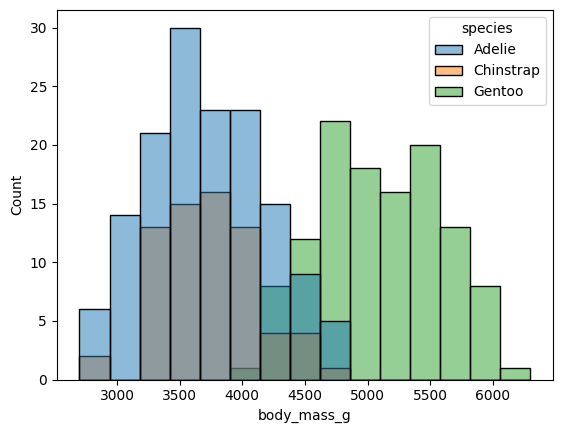
multiple = 'stack'을 써서 한 구간에 종별 카운트를 해줄 수도 있다
ex) sns.histplot(data = data, x = 'body_mass_g', bins = 15, hue = 'species', multiple='stack')
Displot
distribution을 여러 subplot으로 나누어서 출력해주는 plot이다. kind를 변경해서 hist, kde, ecd 모두 출력 가능
ex)
sns.displot(data= data, kind = 'kde', x = 'body_mass_g', hue = 'species')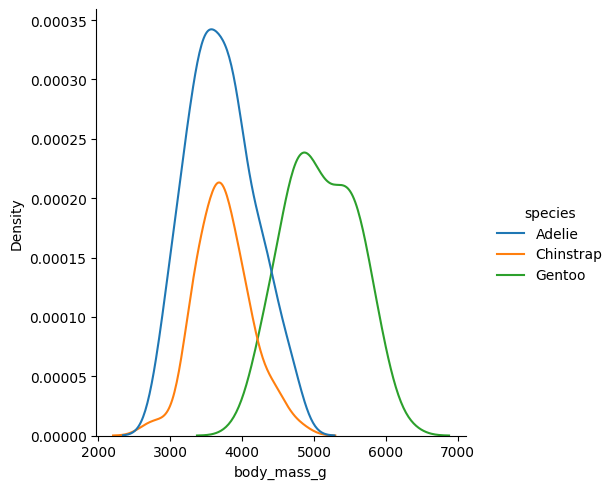
이 경우에도 옵션을 통해서 다른 식으로 표현이 가능하다 !!
ex)
sns.displot(data= data, kind = 'kde', x = 'body_mass_g',hue = 'species', col = 'island')
#sns.displot(data= data, kind = 'kde', x = 'body_mass_g',hue = 'species', row = 'island')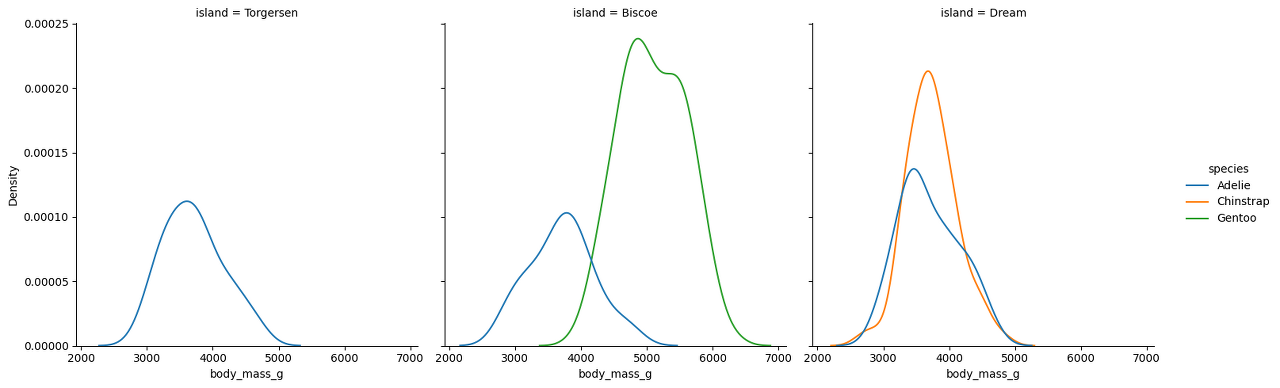
Barplot
어떤 데이터에 대한 값의 크기를 막대로 보여주는 plot
가로/세로 둘다 출력 가능하고 x축엔 범주형 변수, y축엔 수치형 변수로 설정함.
ex) sns.barplot(data = data, x = 'species', y = 'body_mass_g')
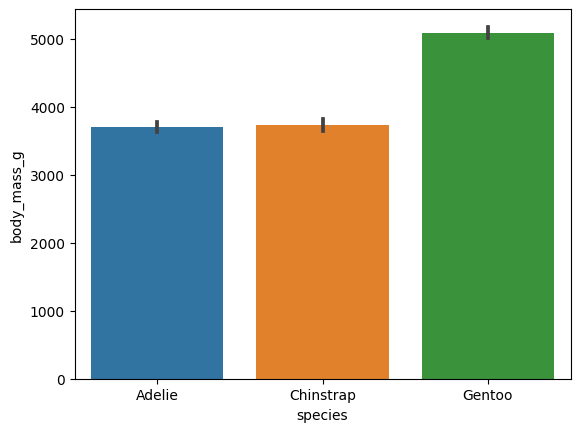
ㄴ 막대그래프는 종류에 따른 값을 비교하는데 많이 사용됨
그래프 위 검은색 직선은 허용 오차를 의미
가로방향으로도 x축, y축에 입력한 변수를 서로 바꾸면 생성 가능 !
sns.barplot(data = data, x = 'body_mass_g', y = 'species')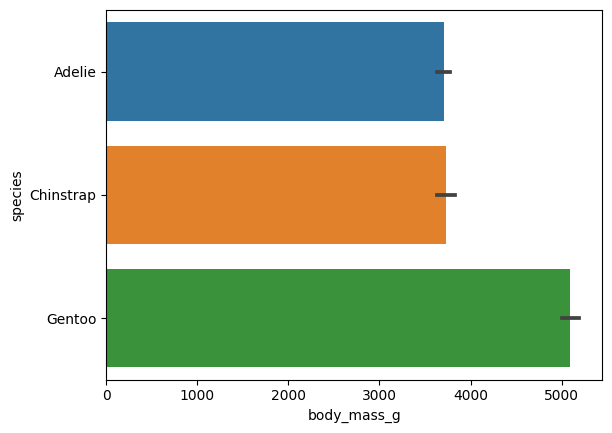
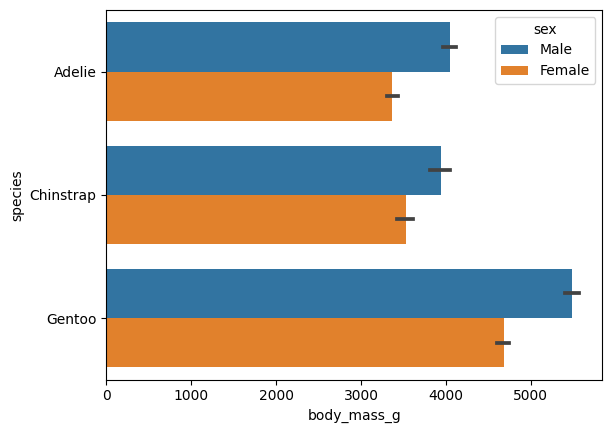
옵션 추가하기는 hue = ''를 이용하면 된다
sns.barplot(data = data, x = 'body_mass_g', y = 'species', hue = 'sex')
Countplot
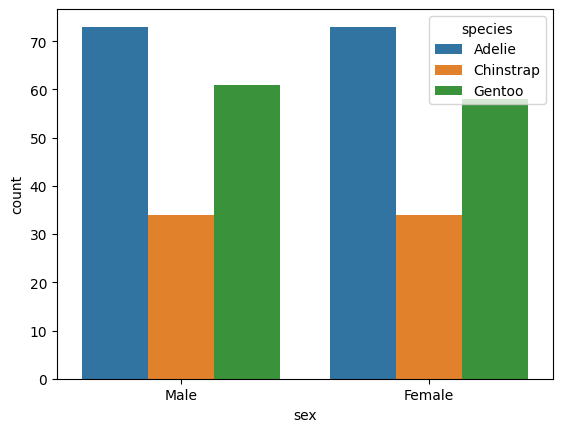
범주형 속성을 가지는 데이터들의 히스토그램을 보여주는 plot. 종류별 count를 시각화하고 싶을 때 사용
ex) sns.countplot(data = data, x = 'sex', hue = 'species')
Boxplot
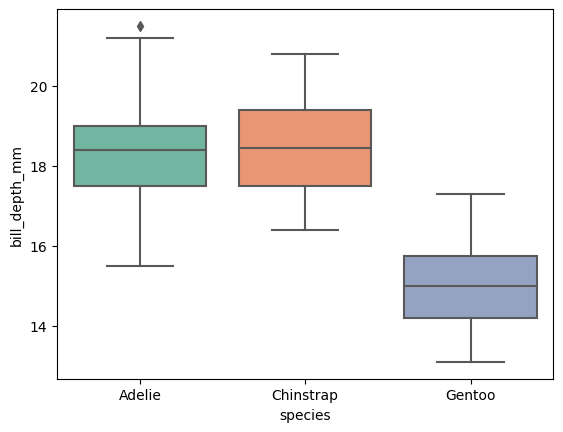
데이터의 변수별로 사분위수를 표시하는 plot. 데이터의 전체적인 분포를 확인하기 좋고 이상치 존재 유무를 파악하기 쉬움
ex) sns.boxplot(data = data, x = 'species', y = 'bill_depth_mm' )
조건을 추가하는건 역시 hue = ''!
sns.boxplot(data = data, x = 'species', y = 'bill_depth_mm', hue= 'sex')
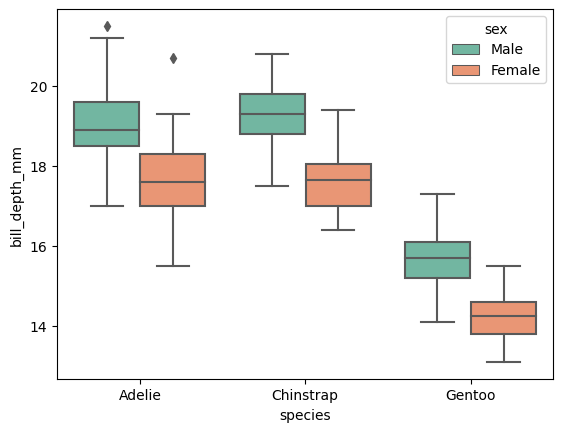
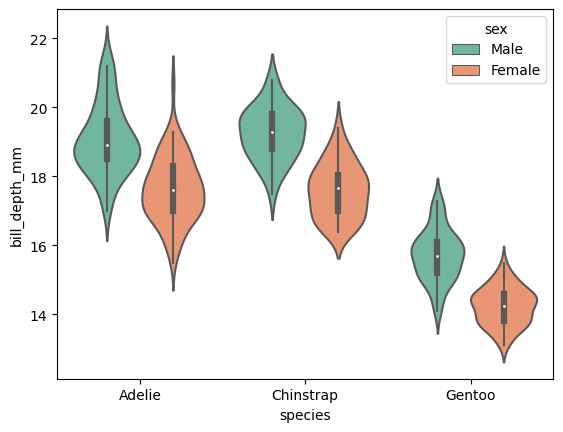
ViolinePlot
변수에 대한 분포 자체를 보여주는 plot!
전체 분포를 보여주고 데이터가 얼마나 있는지 전체적으로 어떻게 퍼져있는지 확인이 가능하다..
ex) sns.violinplot(data = data, x = 'species', y = 'bill_depth_mm', hue= 'sex')
Lineplot
두 변수 간의 관계를 확인할 수 있는 plot
sns.lineplot(data = data, x = 'body_mass_g', y = 'flipper_length_mm')
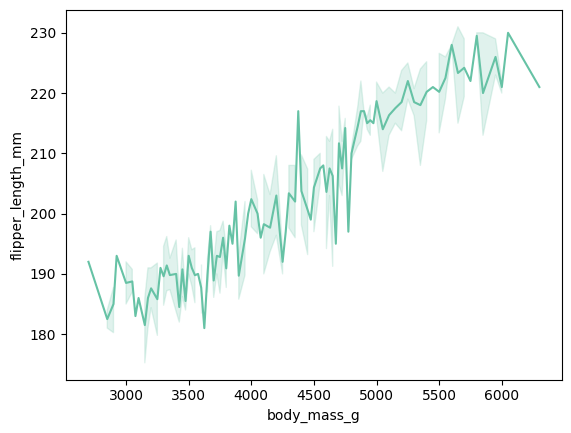
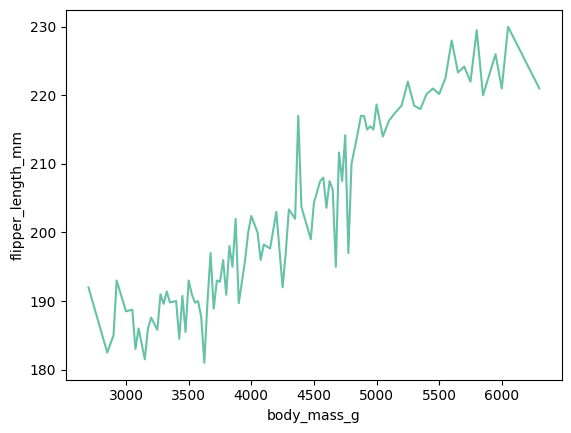
lineplot 상에 옅게 칠해진 백그라운드는 해당 범위에 있는 수치값의 에러에 대한 허용 범위를 얘기함... 이를 조정하고 싶으면 ci를 설정해주면 된다 ~~
sns.lineplot(data = data, x = 'body_mass_g', y = 'flipper_length_mm', ci = None)
Pineplot
특정 수치 데이터를 error bar와 함께 출력해주는 plot. 수치 데이터를 다양한 각도에서 한 번에 바라보고 싶을 때 사용하며 살펴보고싶은 특정 지표들만 사용하는 것이 좋다
sns.pointplot(data = data, x = 'sex', y = 'bill_length_mm')
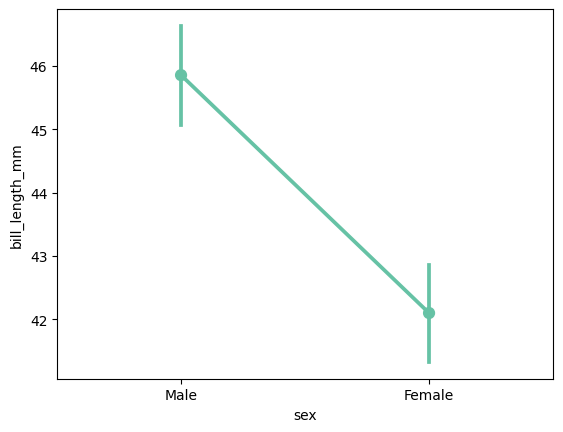
ㄴ 직선은 각 분포를, 직선 중간에 점은 각 변수의 평균에 해당함. 여기서는 수컷의 부리가 암컷의 부리보다 길어보인다
Scatter plot
x,y에 대한 전체적인 분포를 확인하는 plot. 산점도를 써서 데이터 그 자체가 퍼져있는 모양에 중점을 두고 있다
sns.scatterplot(data = data, x ='flipper_length_mm', y = 'body_mass_g', hue = 'sex')
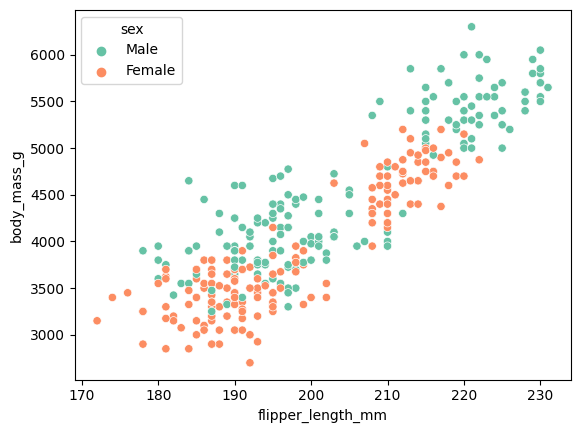
ㄴ 여기서는 팔길이가 증가하면 몸무게가 증가하고, 암컷의 분포가 수컷의 분포보다 상대적으로 밑에 형성된 것을 볼 수 있다
Pairplot
주어진 데이터의 각 변수들 사이의 관계를 표현하는 plot. scatterplot, facetGrid, kdeplot을 이용해서 각 변수들 간의 관계를 보여줌.
모든 결과를 보여주기 때문에, 변수가 많은 경우 사용하긴 적합하지 않다
sns.pairplot(data= data)
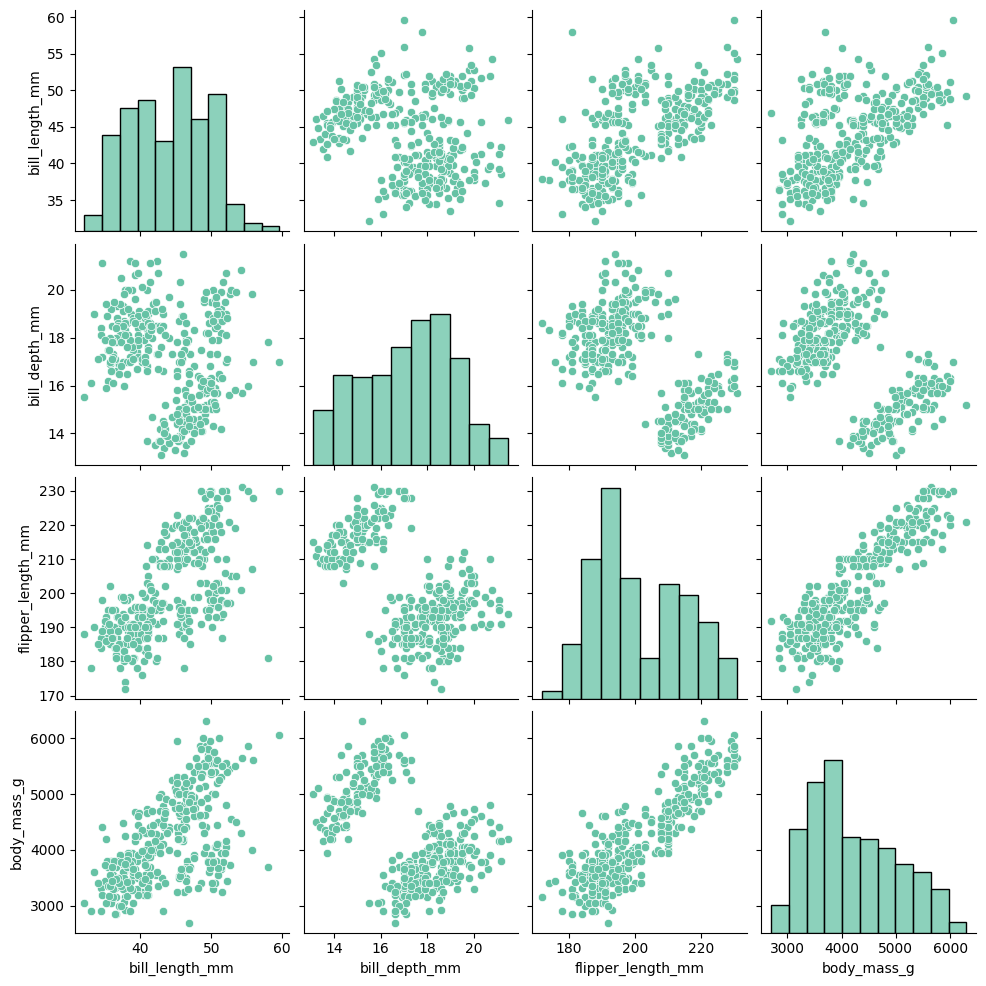
이 plot에 경우 수치형 변수들 간의 관계에 대해 그리기 때문에, data에 따로 지정하지 않아도 됨
hue에 species변수 추가해서 종에 따른 분포를 살펴볼 수도 있다
sns.pairplot(data= data, hue = 'species')
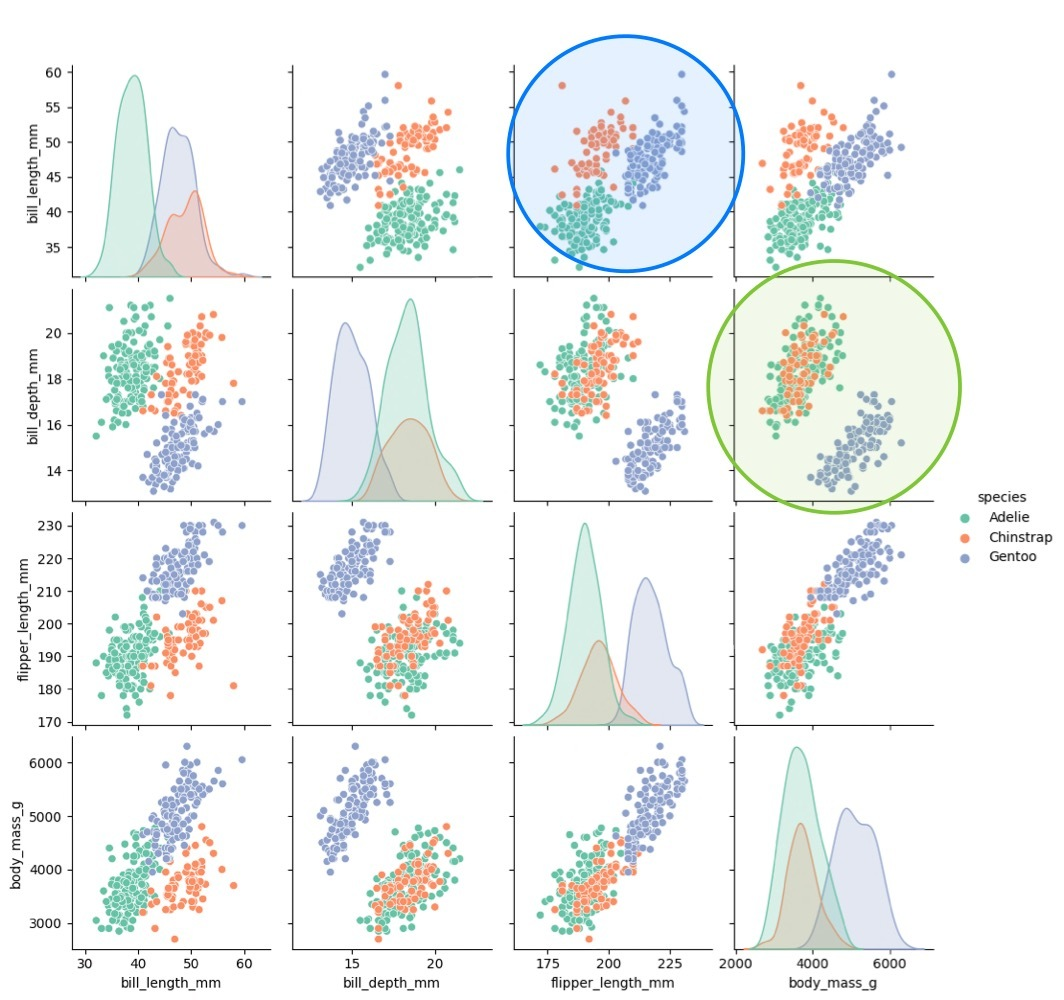
ㄴ adelie와 chinstrap은 유사하지만 gentoo종의 경우 확실히 구분되어있는 것을 볼 수 있음
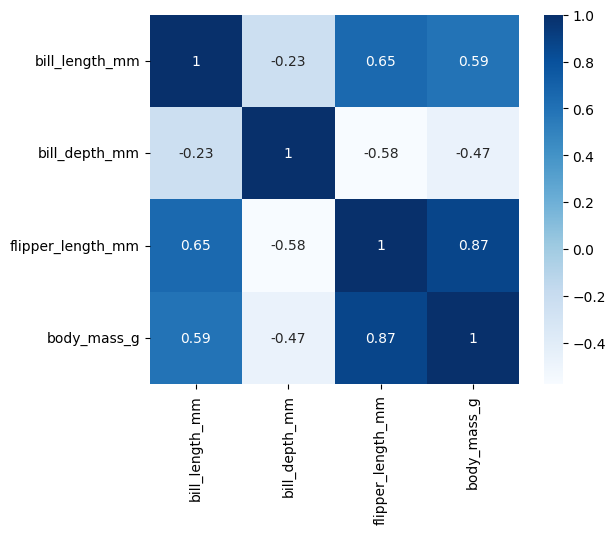
Heatmap
정사각형 그림에 대한 정도 차이를 보여주는 plot
변수들 간의 관계를 시각화할 때 많이 사용되며 특히 변수 간의 상관계수를 표현할 때 자주 사용됨
heatmap을 그리려면 상관계수를 구해야 함.
corr = data.corr()
corr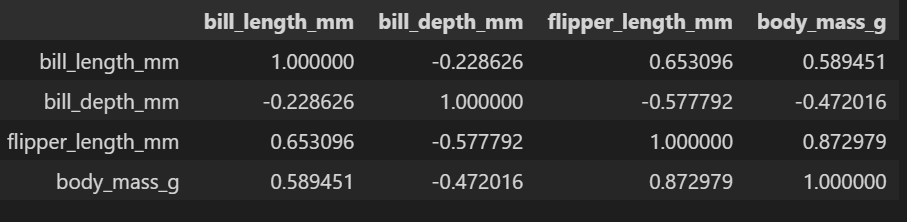
sns.heatmap(data = corr, square= True, cmap = 'Blues')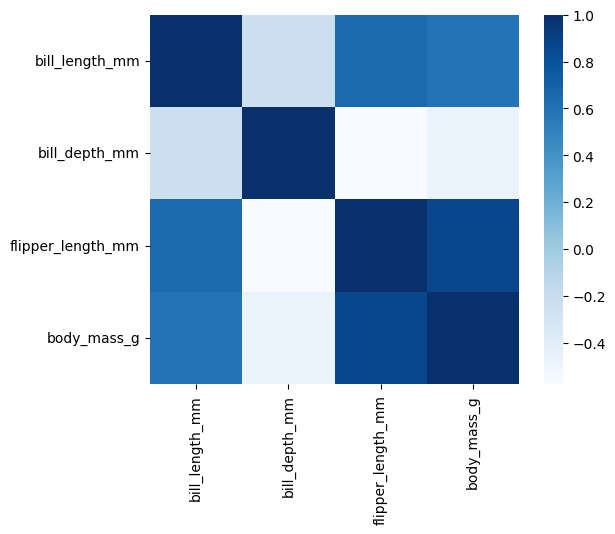
ㄴ 색에 정도에 따라 시각화를 해준다
상관계수 값을 표시하고 싶으면 annot 옵션을 지정하면 된다
sns.heatmap(data = corr, square= True, cmap = 'Blues', annot=True)