
넘파이 ndarray : 다차원 배열 객체
넘파이의 주요 특징은 n차원 배열 ndarray객체가 있다. 이 자료형을 이용해서 연산을 빠르게 처리할 수 있다 !
import numpy as np
data = np.random.randn(2, 3)
dataoutput
array([[-1.25858421, 0.21625778, 1.48456228],
[-1.5184562 , 0.54263558, -0.62803821]])여기서 수학 연산을 어케하냐?!
ㄴ
10 * data다른 언어에선 이렇게 하면 int * list 는 안된다고 typeError가 뜰 텐데 (아마도?) numpy에서는 각 요소들에 10씩 아주 잘 곱해진다 ~~
배열의 크기를 구하고 싶다면 data.shape을 쓰면 되고 출력은 (행,열) 이렇게 나온다 ! 그리고 원소들의 자료형을 알고 싶다면 data.dtype을 쓰자 ~~
ndarray 만들기
넘파이 배열을 만드는 방법
: numpy.array 메소드를 이용!
data1 = [1, 2, 3.5, 4, 5]
arr = np.array(data1)
arroutput
array([1. , 2. , 3.5, 4. , 5. ])다차원 배열을 만드는 방법은 그냥 괄호안에 배열을 몇개 넣어주면 된당
data2 = [[1, 2, 3, 4], [5, 6, 7, 8]]
arr2 = np.array(data2)
arr2output
array([[1, 2, 3, 4],
[5, 6, 7, 8]])만약 배열의 요소들이 전부 0이나 1이었으면 한다면 엄청 쉽게 배열을 만들 수 있는 방법이 있다 !!
0으로만 n개 채우는 방법
np.zeros(10)output
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])1로만 nxm 차원 배열 만드는 방법
np.ones((2, 3))output
array([[1., 1., 1.],
[1., 1., 1.]])arange함수 ~~는 range함수와 대응되는 거지만 반환값은
넘파이배열이다
np.arange(10)output
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])넘파이 자료형
형 변환 하는 법 ! -> astype메소드 이용하기
arr = np.array([1, 2, 3, 4, 5])
arr.dtype
arr_float = arr.astype(np.float64)
arr_float.dtypeoutput
dtype('int32')
dtype('float64') # 바뀌었다 !넘파이 배열 연산
넘파이는 연산에 아주 뛰어난 라이브러리?여서 반복문을 쓰지 않고 연산을 할 수 있다 !!
arr = np.array([[1., 2., 3.], [4., 5., 6.]])
arroutput
array([[1., 2., 3.],
[4., 5., 6.]])ㄴ 배열 준비 !!
arr * arroutput
array([[ 1., 4., 9.],
[16., 25., 36.]])두 배열 간 연산도 쉽다
arr2 = np.array([[0., 4., 1.], [7., 2., 12.]])
arr < arr2output
array([[False, True, False],
[ True, False, True]])인덱싱, 슬라이싱 기본
arr = np.arange(10)
arr
arr[5:8]output
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
array([5, 6, 7])이렇게 배열 안에서 원하는 인덱스~인덱스의 요소만 뽑아올 수 있다 !
근데 넘파이 슬라이싱이 파이썬 리스트와 다른점 중 하나는 선택 부분의 값을 변경하면 원래 배열의 같은 위치의 값도 변경된다는 것이다 !
배열 일부분 복사하는 방법 = copy메소드 쓰기
arr_copy = arr[5:8].copy()
arr_copyoutput
array([500, 500, 500])만약에 copy해서 값을 바꿔도
arr_copy[:] = -100
arr_copyoutput
array([-100, -100, -100])arr_copy값은 변경되지만 arr값은 변경이 안된다
arroutput
array([ 0, 1, 2, 3, 4, 500, 500, 500, 8, 9])슬라이싱을 이용한 인덱싱
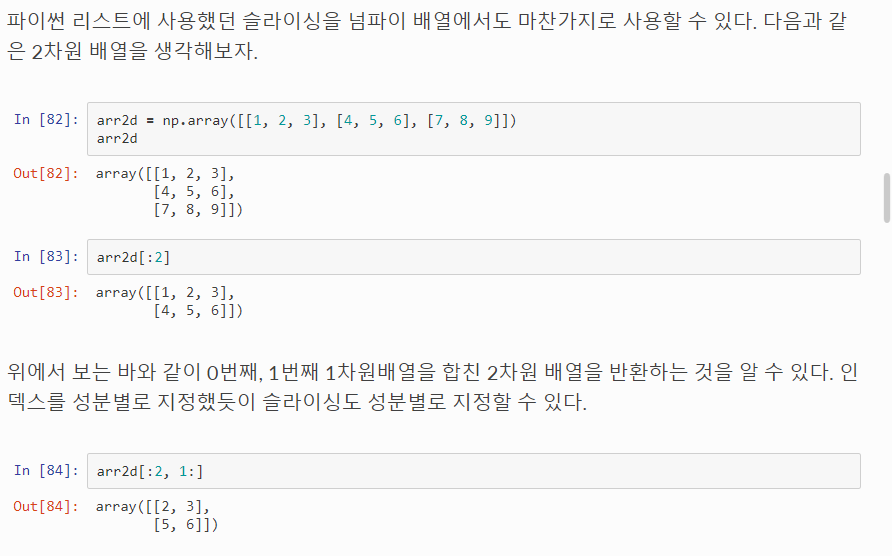
이 부분이 어렵다 !!
스터디 시간에 물어봐야지 개어렵ㄷ네
논리 인덱싱
names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'])
np.random.seed(0)
data = np.random.randn(7, 4)
dataoutput
array([[ 1.76405235, 0.40015721, 0.97873798, 2.2408932 ],
[ 1.86755799, -0.97727788, 0.95008842, -0.15135721],
[-0.10321885, 0.4105985 , 0.14404357, 1.45427351],
[ 0.76103773, 0.12167502, 0.44386323, 0.33367433],
[ 1.49407907, -0.20515826, 0.3130677 , -0.85409574],
[-2.55298982, 0.6536186 , 0.8644362 , -0.74216502],
[ 2.26975462, -1.45436567, 0.04575852, -0.18718385]])ㄴ 이러한 배열 준비
bob에 해당하는 행만 선택하기를 원한다면 비교연산자 ==를 사용하자 !
names == 'Bob'output
array([ True, False, False, True, False, False, False])다중 인덱스를 사용해보자
data[names == 'Bob', 2:]output
array([[0.97873798, 2.2408932 ],
[0.44386323, 0.33367433]])ㄴ 내 생각엔 [names == 'Bob']이게 나타내는게 0과 3번 임. 그래서 0,3 번 행 추출하고 2: 를 써서 2번째 요소부터 끝까지 출력해라 ~ 인 것 같다
부정연산자를 사용해도 된당
data[~(names == 'Bob')]output
array([[ 1.86755799, -0.97727788, 0.95008842, -0.15135721],
[-0.10321885, 0.4105985 , 0.14404357, 1.45427351],
[ 1.49407907, -0.20515826, 0.3130677 , -0.85409574],
[-2.55298982, 0.6536186 , 0.8644362 , -0.74216502],
[ 2.26975462, -1.45436567, 0.04575852, -0.18718385]])정수 배열을 이용한 인덱싱
정수 배열을 이용해서 인덱싱을 자유롭게 할 수 있음 !!
일단 배열 만들기!
arr = np.empty((8, 4)) # 8x4 크기의 비어있는 다차원 배열 생성 코드
for i in range(8):
arr[i] = i
arroutput
array([[0., 0., 0., 0.],
[1., 1., 1., 1.],
[2., 2., 2., 2.],
[3., 3., 3., 3.],
[4., 4., 4., 4.],
[5., 5., 5., 5.],
[6., 6., 6., 6.],
[7., 7., 7., 7.]])원하는 행을 뽑아서 원하는 순서대로 배열하고 싶으면 인덱스를 배열로 만들어서 대입하면 된당
arr[[4, 3, 0, 6]]output
array([[4., 4., 4., 4.],
[3., 3., 3., 3.],
[0., 0., 0., 0.],
[6., 6., 6., 6.]])여러개의 정수 배열 인덱싱
# 0~31 까지의 연속된 정수를 포함하는 1차원 배열 생성하고 이 배열을 8x4의 2차원 배열 모양으로 변경하는 코드
arr = np.arange(32).reshape(8, 4)
arroutput
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31]])정수열 배열 인덱스를 2개의 성분에 대입하면 결과값은 각각의 튜플에 해당하는 일차원 배열이 나옴
arr[[1, 5, 7, 2], [0, 3, 1, 2]]output
array([ 4, 23, 29, 10])ㄴ 1 5 7 2가 행 인덱스, 0 3 1 2가 열 인덱스이다 !
배열 전치 및 축 교환
전치(transpose)는 크기 변경의 특별한 형태이다
배열은 .transpose로 써도 되고 .T로 써도 된당
배열 준비
arr = np.arange(15).reshape((3,5))
arroutput
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])전치 !!
arr.Toutput
array([[ 0, 5, 10],
[ 1, 6, 11],
[ 2, 7, 12],
[ 3, 8, 13],
[ 4, 9, 14]])두 행렬의 곱을 계산할 때엔 dot메소드를 사용한다
arr.dot(arr.T)output
array([[ 30, 80, 130],
[ 80, 255, 430],
[130, 430, 730]])고차원 배열 넘 어렵다.. ㅠㅠ
고차원배열에서 전치는 축 인덱스를 인자로 가짐
ex) 2x3x4 3차원 배열
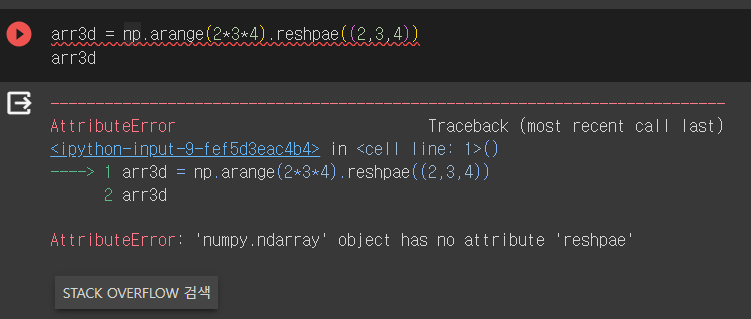
아 에러 왜지 !!!???!!
범용함수
ㄴ 넘파이 배열의 성분끼리 연산을 할 수 있는 함수를 말한다 ex) sqrt, exp
배열 준비
arr = np.arange(10)
arroutput
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])sqrt 함수 적용
np.sqrt(arr)output
array([0. , 1. , 1.41421356, 1.73205081, 2. ,
2.23606798, 2.44948974, 2.64575131, 2.82842712, 3. ])exp 함수 적용!
ㄴ exp 함수는 지수 함수를 계산하는 함수이당
np.exp(arr)output
array([1.00000000e+00, 2.71828183e+00, 7.38905610e+00, 2.00855369e+01,
5.45981500e+01, 1.48413159e+02, 4.03428793e+02, 1.09663316e+03,
2.98095799e+03, 8.10308393e+03])add 함수 (더하기)
np.add(arr, arr)output
array([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18])maximum 함수 (최댓값 구하기)
np.maximum(x, y)output
array([ 1.76405235, 1.45427351, 0.97873798, 2.2408932 , 1.86755799,
0.33367433, 1.49407907, -0.15135721, 0.3130677 , 0.4105985 ])modf함수 (정수와 소수부분을 각각 반환)
(배열 준비)
rng = np.random.RandomState(0)
arr = rng.randn(7) * 5
arroutput
array([ 8.82026173, 2.00078604, 4.89368992, 11.204466 , 9.33778995,
-4.8863894 , 4.75044209])rem_part, int_part = np.modf(arr)
rem_part #소수 부분output
array([-0.93591925, 0.66389607, 0.34679385, 0.77473713, 0.8908126 ,
-0.43892874, -0.90398234])ㄴ 원래 이렇게 나와야하는데 나는
array([ 8.20261730e-01, 7.86041836e-04, 8.93689921e-01, 2.04465996e-01,
3.37789951e-01, -8.86389399e-01, 7.50442088e-01])왜 이렇게 나오는거지....... 스터디시간에 물어보자 !!
int_part # 정수 부분output
array([ 8., 2., 4., 11., 9., -4., 4.])ㄴ 또 정수 부분을 잘 나온다..
배열 지향 프로그래밍
1차원 자료를 이용해서 2차원 계산을 쉽게 할 수 있다 !
meshgrid함수를 사용하면 모든 격자점의 x,y 좌표를 계산할 수 있음
points = np.arange(-5, 5, 0.01)-5~5 까지 1000개의 점을 격자형으로 만듦
xs, ys = np.meshgrid(points, points)
ysoutput
array([[-5. , -5. , -5. , ..., -5. , -5. , -5. ],
[-4.99, -4.99, -4.99, ..., -4.99, -4.99, -4.99],
[-4.98, -4.98, -4.98, ..., -4.98, -4.98, -4.98],
...,
[ 4.97, 4.97, 4.97, ..., 4.97, 4.97, 4.97],
[ 4.98, 4.98, 4.98, ..., 4.98, 4.98, 4.98],
[ 4.99, 4.99, 4.99, ..., 4.99, 4.99, 4.99]])ㄴ 구글 코랩에서는 module 'numpy' has no attribute 'meshigrid' 이렇게 뜨긴하는데.. 왜지 지원안해주나
함수 값 계산은 각 점에서의 스칼라 계산
z = np.sqrt(xs ** 2 + ys ** 2)
zoutput
array([[7.07106781, 7.06400028, 7.05693985, ..., 7.04988652, 7.05693985,
7.06400028],
[7.06400028, 7.05692568, 7.04985815, ..., 7.04279774, 7.04985815,
7.05692568],
[7.05693985, 7.04985815, 7.04278354, ..., 7.03571603, 7.04278354,
7.04985815],
...,
[7.04988652, 7.04279774, 7.03571603, ..., 7.0286414 , 7.03571603,
7.04279774],
[7.05693985, 7.04985815, 7.04278354, ..., 7.03571603, 7.04278354,
7.04985815],
[7.06400028, 7.05692568, 7.04985815, ..., 7.04279774, 7.04985815,
7.05692568]])이걸 이제 matplotlib을 이용해서 시각화할 수 있당
%matplotlib inline
import matplotlib.pyplot as plt
plt.imshow(z, cmap=plt.cm.gray) #inshow = 이미지 표시에 사용, cmap는 이미지를 어떤 색상 맵으로 표현할지 지정, plt.cm.gray = 회색조 색상 맵 사용
plt.colorbar() # 색상 척도를 이미지 옆에 표시
plt.title("Image plot of $\sqrt{x^2 + y^2}$ for a grid of values") # title함수 = 그래프의 제목 설정output
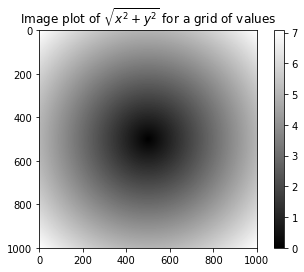
조건 연산을 이용한 배열 계산
np.where = 파이썬 삼항연산 (<참일때 식> if <참 거짓 판단 식> else <거짓일 때 식>) 에 대응되는 넘파이 함수임
ex) cond이 true이면 xarr원소를, 그렇지 않으면 yarr 원소를 얻기를 원한다
배열 준비
xarr = np.array([1.1, 1.2, 1.3, 1.4, 1.5])
yarr = np.array([2.1, 2.2, 2.3, 2.4, 2.5])
cond = np.array([True, False, True, True, False])리스트 축약 이용하기
[(x if c else y) for x, y, c in zip(xarr, yarr, cond)]output
[1.1, 2.2, 1.3, 1.4, 2.5]리스트 축약 방법은 계산이 느려지고 복잡하다 !!
이럴때 np.where을 써서 간단히 계산해보자
result = np.where(cond, xarr, yarr)
resultoutput
array([1.1, 2.2, 1.3, 1.4, 2.5])그리고 np.where의 두번째, 세번째 인자는 배열일 필요가 없다 ! 스칼라여도 됨
ex) 4 x 4 무작위 배열에서 음수이면 -2, 그렇지 않으면 2를 지정
arr = np.random.randn(4, 4)
arroutput
array([[-0.34791215, 0.15634897, 1.23029068, 1.20237985],
[-0.38732682, -0.30230275, -1.04855297, -1.42001794],
[-1.70627019, 1.9507754 , -0.50965218, -0.4380743 ],
[-1.25279536, 0.77749036, -1.61389785, -0.21274028]])np.where 쓰기
np.where(arr < 0, -2, 2)output
array([[-2, 2, 2, 2],
[-2, -2, -2, -2],
[-2, 2, -2, -2],
[-2, 2, -2, -2]])수학 및 통계 메소드
std, sum, mean 과 같은 함수들로 수학 계산을 할 수 있다 ~~
(배열 준비)
arr = np.random.randn(5, 4)
arroutput
array([[-1.63019835, 0.46278226, -0.90729836, 0.0519454 ],
[ 0.72909056, 0.12898291, 1.13940068, -1.23482582],
[ 0.40234164, -0.68481009, -0.87079715, -0.57884966],
[-0.31155253, 0.05616534, -1.16514984, 0.90082649],
[ 0.46566244, -1.53624369, 1.48825219, 1.89588918]])mean 함수 쓰기
arr.mean()output
-0.059919320352960825이렇게도 쓸 수 있따 ~
np.mean(arr)output
-0.059919320352960825sum 함수 쓰기
arr.sum()output
-1.1983864070592165sum 같은 메소드는 선택인자로 축(axis =)를 가질 수 있음. axis = 0은 다른 축은 고정시키고 첫번째 축(x축) 값에 대해서만 계산하라는 뜻
arr.sum(axis=0)output
array([-0.34465624, -1.57312327, -0.31559248, 1.03498557])cumsum, cumprod 는 집계를 반환하지 않고 집계 중간값이 포함된 같은 크기의 배열을 반환
- cumsum : 누적 합계를 계산
- cumprod : 누적 곱을 계산
arr = np.arange(8)
arroutput
array([0, 1, 2, 3, 4, 5, 6, 7])cumsum 메소드 쓰기
arr.cumsum()output
array([ 0, 1, 3, 6, 10, 15, 21, 28], dtype=int32)배열에도 됨
arr = np.arange(9).reshape(3, 3)
arroutput
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])cumsum함수 쓰기
arr.cumsum(axis=0)output
array([[ 0, 1, 2],
[ 3, 5, 7],
[ 9, 12, 15]], dtype=int32)논리 배열 메소드
배열 준비
arr = np.random.randn(10)
arroutput
array([ 0.01050002, 1.78587049, 0.12691209, 0.40198936, 1.8831507 ,
-1.34775906, -1.270485 , 0.96939671, -1.17312341, 1.94362119])arr이 0보다 큰 것의 갯수를 센다면?
(arr > 0).sum()output
7자주 사용되는 메소드로 any와 all이 있당
- any : 배열 중 참인 것이 하나라도 있으면 참 반환
- all : 배열이 모두 참으로만 이루어졌을 때 참 반화

정렬
파이썬 리스트 메소드 sort와 비슷하게 넘파이 배열도 sort 메소드를 이용해서 정렬할 수 있당
arr = np.random.randn(5)
arroutput
array([ 0.40746184, -0.76991607, 0.53924919, -0.67433266, 0.03183056])여기서 sort()를 쓰면
arr.sort()
arroutput
array([-0.76991607, -0.67433266, 0.03183056, 0.40746184, 0.53924919])유연성 및 집합 연산
numpy.unique함수를 사용해서 배열 원소 중 중복되지 않는 배열을 얻을 수 있다 !!
names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'])
np.unique(names)output
array(['Bob', 'Joe', 'Will'], dtype='<U4')한 배열의 원소들이 다른 배열에 속했는지를 판단할 수 있는 함수로 np.in1d가 있다.
values = np.array([6,0,0,3,2,5,6])
np.in1d(values, [1,2,3])output
array([False, False, False, True, True, False, False])넘파이 배열 파일 입출력
넘파이는 텍스트 및 바이너리 파일로 입력과 출력을 할 수 있다 !
np.save(파일 이름, 배열), np.load(파일이름)을 이용해서 불러오기를 한다.
np.save
arr = np.arange(10)
np.save('examples/array_save', arr)np.load
arr1 = np.load('examples/array_save.npy')
arr1output
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])배열에 접근하려면 저장할 때 사용한 열쇠(key)를 이용해서 사진 형식으로 부름
arr2['a']output
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])