https://www.youtube.com/watch?v=xki7zQDf74I
https://www.youtube.com/watch?v=2Rd4AqmLjfU&t=2s
https://ratsgo.github.io/machine%20learning/2017/03/26/tree/
https://huidea.tistory.com/246
https://www.nature.com/articles/nmeth.4370
https://curriculum.cosadama.com/machine-learning/3-3/
https://heytech.tistory.com/145
https://rpubs.com/shngli/91166
https://code13.tistory.com/253
https://bigdatajessie.tistory.com/31
위 자료를 참고했다.
Decision Tree란?
- 설명변수(X) 간의 관계나 척도에 따라 목표변수(Y)를 예측하거나 분류하는 문제(회귀, 분류)에 활용되는 나무 구조의 모델
- 설명변수의 관측값을 모델에 입력해 목표변수를 분류, 혹은 예측하는 지도학습 기반의 방법론
Decision Tree 예시

- 요런 느낌
- 보면 모든 terminal node의 데이터 수 총 합이 원본 데이터의 수가 되는 것을 알 수 있다.
Decision Tree를 사용하는 주된 이유
- 목표변수(Y)에 대한 회귀, 분류 문제에 있어 어떤 설명변수(X)가 가장 중요한 영향인자인가를 확인하기 위함
- 각 설명변수(X)별로 어떤 척도에 따라 예측/분류를 진행했는지 상세한 기준을 알 수 있음
Decision Tree Model의 장단점
-
장점
- 결과의 해석이 용이하다
- 직관적으로 해석할 수 있으며, 주요 변수 및 분리 기준을 제시해줌
- 비모수적 모델
- 통계모델에 요구되는 가정(정규성, 독립성, 등분산성)에 자유롭다
- 정규성 : 확률 오차는 정규분포를 따른다.
- 독립성: 독립변수 간의 상관관계가 없이 독립성을 만족하는 것
- 다중회귀분석의 중요한 가정
- 독립변수와의 상관성과 자기 상관성을 확인해 독립성을 판단
- 등분산성: 예측값과 상관없이 오차의 모든 분산이 동일
- 통계모델에 요구되는 가정(정규성, 독립성, 등분산성)에 자유롭다
- 변수 간 상호작용
- 변수 간의 상호작용을 고려하며 선형/비선형 관계 탐색 가능
- 결과의 해석이 용이하다
-
단점
- 비안정성
- 데이터 수가 적을 경우 특히 불안정하며, 과대적합 발생 가능성이 높으므로 가지치기가 필요
- 전체적인 선형관계 파악하기 어려움
- 분리 시 연속형 변수를 비연속화하므로(구간화처리), 분리 경계점 근처에서 오류 발생 가능
- 비안정성
Decision Tree Modeling Process (Regression)
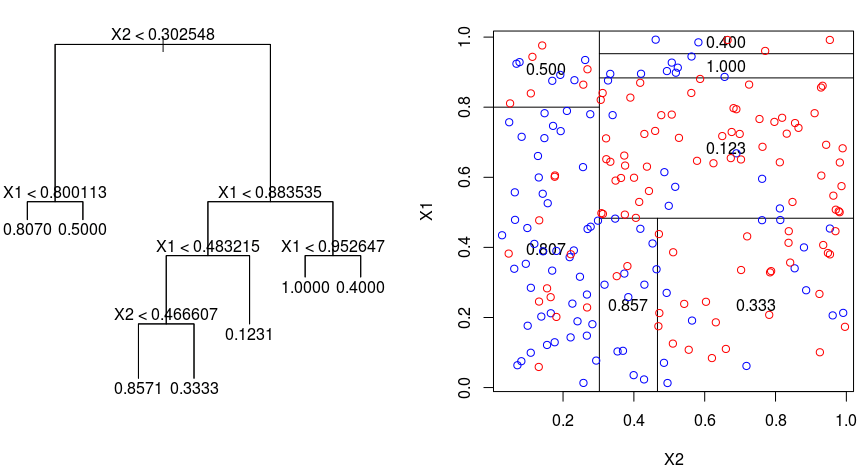
- 데이터를 M개의 region으로 분할
- cost function(MSE, MAE 등 오차함수)값을 최소로 할 때 최상의 분할이 이뤄짐
- 즉, 각 분할에 속해있는 y값들의 평균으로 예측하도록 하는 것
분할변수와 분할점은 어떻게 결정하는가?
- 분할변수와 분할점을 다 바꿔가면서 오차를 확인해봄 (Greedy Search)
- 예를 들어, 분할 변수 3개에 대해 분할 점이 각각 2개씩 있다면 6번을 다 해보는 것
- 최소 오차를 갖는 분할변수와 분할점을 선택
Decision Tree Modeling Process (Classification)
- 각 region에 속한 특정 class에 속하는 관측지의 비율이 가장 높은 것의 class로 분류됨
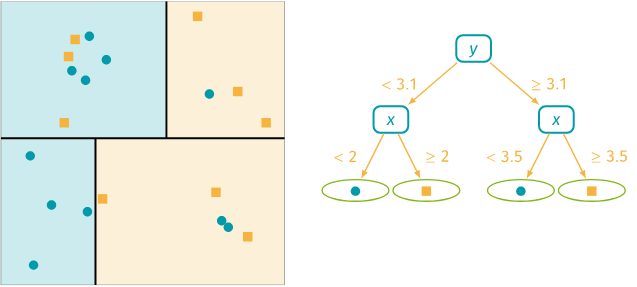
요런 느낌
Classification task에서의 cost function
-
classification task에서는 y값이 "범주"에 해당함
따라서 다음의 세 가지 cost function이 존재 -
Misclassification rate
- 실제 범주와 모델이 예측한 범주가 얼마나 잘 매칭되었는가
- 즉, 매칭되지 않은 경우의 수를 최소화하겠다는 것
-
Gini Index
- 불순도를 측정하는 지표
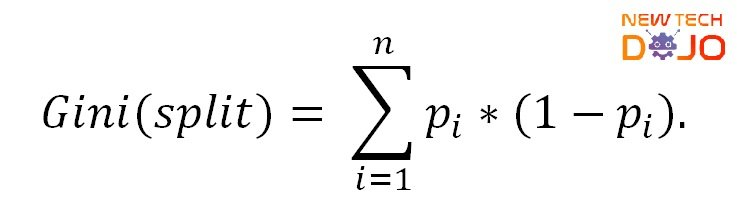
- Cross-Entropy
- 불확실성. 무질서도를 나타내는 지표. 높을 수록 정보가 많다는 것

- 불확실성. 무질서도를 나타내는 지표. 높을 수록 정보가 많다는 것
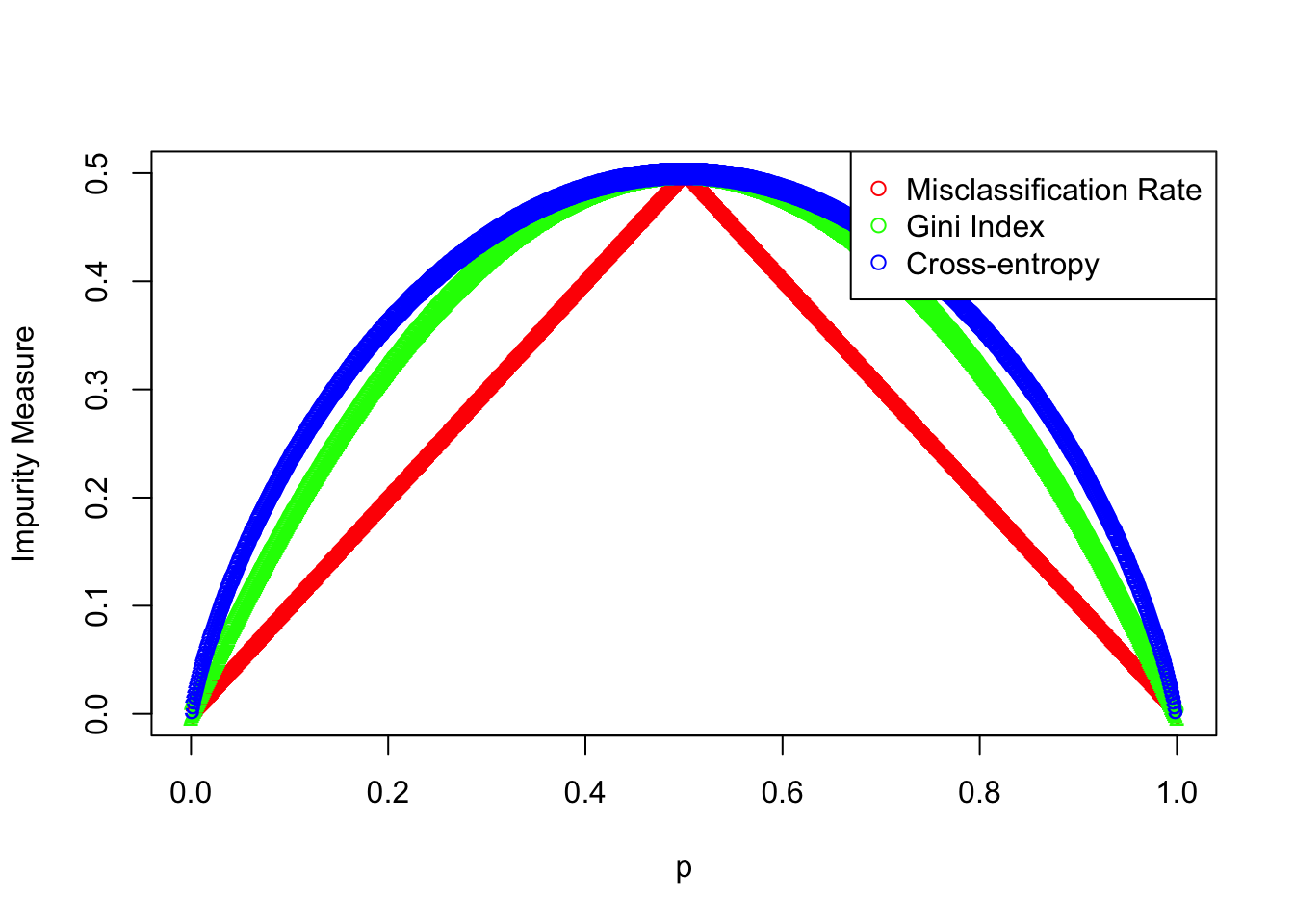
이 그림에서 Cross-entropy값은 p=0.5일때 1이 되어야 맞는데, scale되어 시각화한 것으로 이해하면 됨
각 cost function의 계산 예시는 영상자료를 참고하자.
분할변수와 분할점은 어떻게 결정하는가?
-
비용함수를 최소화하는 분할변수 및 분할점 사용
- 분할변수와 분할기준은 목표변수(y)의 분포를 가장 잘 구별해주는 쪽으로 정한다.
- "목표변수의 분포를 잘 구별해주는 측도"는 순수도(purity) 혹은 불순도(impurity)로 정의
- 예를 들어, 클래스 0과 클래스 1의 비율이 비슷하게 있는 노드는 불순도가 높게 되는 것
- 각 노드에서 분할변수와 분할점의 설정은 "불순도의 감소가 최대"가 되도록 선택한다.
- "목표변수의 분포를 잘 구별해주는 측도"는 순수도(purity) 혹은 불순도(impurity)로 정의
- 분할변수와 분할기준은 목표변수(y)의 분포를 가장 잘 구별해주는 쪽으로 정한다.
-
Information gain(IG): 특정 변수를 사용했을 때의 entropy 감소량
- IG가 클 수록 더 중요한 변수라 볼 수 있음
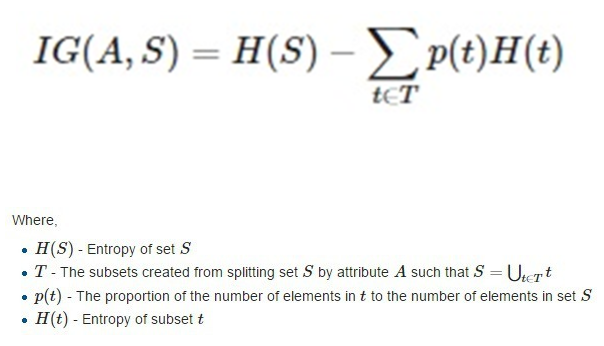
- IG가 클 수록 더 중요한 변수라 볼 수 있음
Decision Tree Model의 단점
- "단일 트리"를 사용해 계층적 구조를 가짐
- 계층적 구조로 인해 중간에 에러가 발생하면 다음 단계로 계속 에러가 전파됨
- 학습 데이터의 미세한 변동에서 최종 결과가 크게 영향받음
- 적은 개수의 노이즈에도 크게 영향받음
- 나무의 최종 노드 개수를 늘리면 과적합될 위험성 존재 (Low Bias, Large Variance)
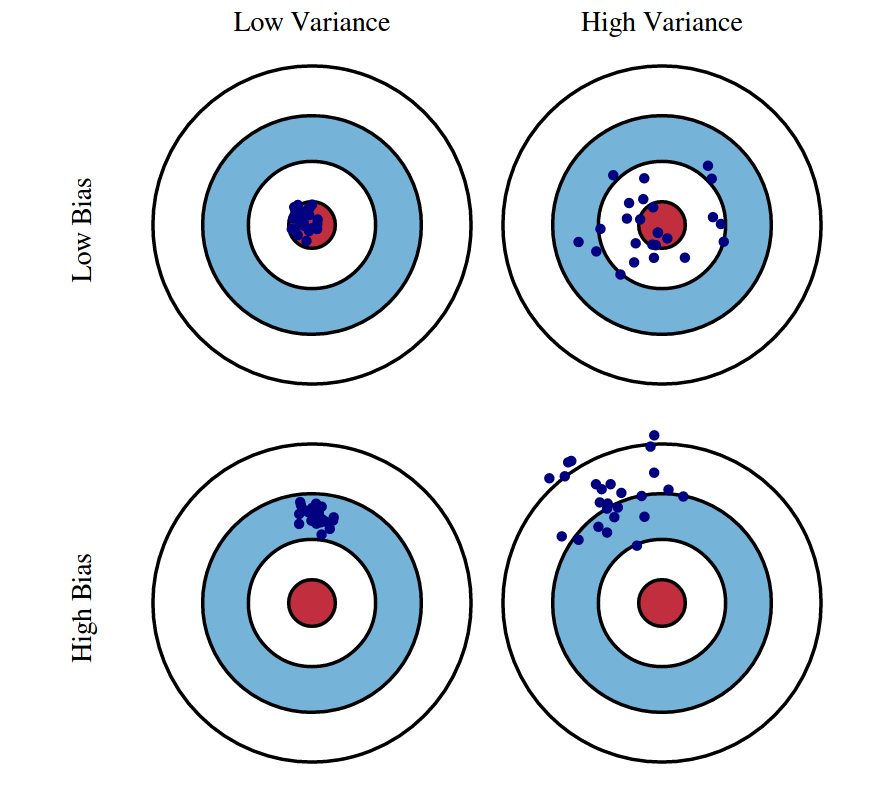
Decision Tree Model의 단점 보완 방안
- Random Forest
- 나무를 여러 개 만들고, 그 결과를 요약에서 최종 결과를 내는 모델
여담
유트브에 정말 좋은 자료들이 많은 것 같다. 여유 날 때마다 보도록 하자!
