영상을 올리고 해당 영상의 민심(?), 반응이 어떤지 확인할 수 있는 comment 분석기 기능을 추가해봤습니다.
데이터
학습에 필요한 데이터를 모아봤습니다.
- 한국어 단발성 대화
- 한국어 악성댓글 데이터
욕설이 들어갔거나, 강한 혐오표현, 비난- 욕설 감지 데이터셋
단순 욕설, 인종 차별적인 말, 정치적 갈등을 조장하는 말, 성적·성차별적인 말, 타인을 비하하는 말, 그 외에 불쾌감을 주거나 욕설로 판단되는 말- youtube comment 수집하여 일부 라벨링
전처리, tokenizer 모델
일부 인터넷 용어들 사전을 따로 만들어주기위해 커스텀하기 쉬운 ckonlpy로 선정
- ckonlpy
학습모델
- LSTM, LSTM+Attention, Bilstm, Bilstm + Attention
먼저, 리뷰나 글이 아닌 유투브나 트위터 같이 비교적 짧은 단발성 댓글에 어떤 모델을 적용해야할지 굉장히 고민이 많이되었습니다.
평균 문장의 길이가 '11~12'정도 되었고, 인터넷 용어 특성상 은어와 욕설 맞춤법 등 따져야할 것이 굉장히 많았는데 이 또한 어떻게 전처리하고 토큰화 할 것인지 고민해야합니다. 예를들어 특정 커뮤니티, 유투버들의 유행어나 그 안에서 주로 쓰이는 단어들이 있기 때문에 어느정도 정리해야 했고, 이러한 특정 단어를 쓰는 데이터를 모델을 학습시키는데 사용해도 될런지 고민했습니다.
일단, RNN기반 LSTM, Bilstm 모델을 이용해보았는데요 확실히 긍정적, 부정적이 아닌 애매하게 비꼬는 문장들의 경우가 있는데, 이를 어느정도 해결하기 위해서는 결국 '문맥'적으로 기계가 학습할수 있는 모델을 이용해야 한다는 것이었습니다.
전처리
딥러닝을 이용한 자연어 처리 입문의 내용을 바탕으로 진행하였습니다.
데이터 결합
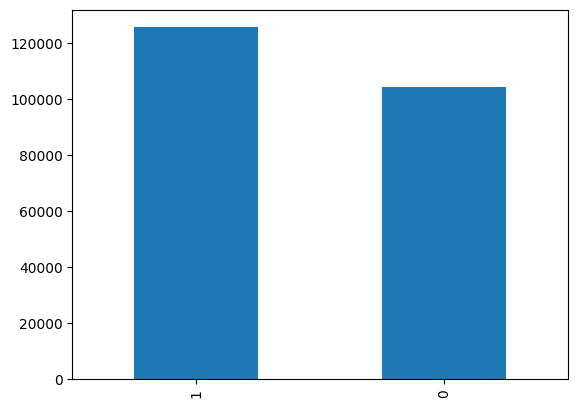
어차피 해당 댓글이 clean(긍정적)인지, 부정적인지 이진분류 하는데에 초점을 맞췄기 때문에, '부정'중에 좀 더 세부적으로 라벨링('인종차별','성별혐오','단순악플' 등)이 되어있는 데이터들을 모두 '부정'으로 합쳐주었습니다. 긍정으로 라벨링된 데이터가 약 2만개 더 많습니다.
sentiment 긍정(1) : 125585
sentiment 부정(0) : 104299
토큰화
여러 형태소 분석기가 있지만, 그중에서 ckonlpy를 사용한 이유는 바로 댓글 특성상 인터넷에서 쓰이는 은어들이 많기 때문입니다. 흔히 트위터 분석기라고도 불리는 ckonlpy 의 경우, 다른 분석기보다 사전단어를 추가하는데 굉장히 편리하고, 속도도 뒤쳐지지 않았고, 댓글에 자주 볼 수있는 패턴(ex 앜ㅋㅋㅋ, 귀여웤ㅋㅋ)을 정규화하는 기능이 있어서 선택했습니다.
# ckonlpy 패키지 다운
! git clone https://github.com/lovit/customized_konlpy.git
! pip install customized_konlpy
from ckonlpy.tag import Twitter
twi = Twitter()
예를들어, 아래의 댓글 처럼, '춘식' 이라는 이름 과, '가성비' 라는 합성어는 하나의 단어임에도 불구하고 춘 + 식이 가 + 성비 로 분리해버리는 경우가 생깁니다.
워낙 고유명사, 은어, 합성어, 줄임말들이 많아서. 이를 모두 다 찾을수는 없지만 그래도 어느정도는 사전화할 필요가 있었습니다.
또한 ckonlpy의 경우 아래의 댓글에서 볼 수있듯이 norm=True 노멀라이즈 옵션을 이용하면 '귀여웤ㅋㅋ' 같은 단어를 귀여워+ㅋㅋ 로 정규화 시켜주기 때문에 자주 보이는 이런 패턴의 댓글에 쓰기 좋았습니다.
text = '춘식이 귀여웤ㅋㅋ 공연 가성비 ㅆㅅㅌㅊ'
print(twi.pos(text, norm=True))
# 결과
[('춘', 'Verb'), ('식이', 'Noun'), ('귀여워', 'Adjective'), ('ㅋㅋ', 'KoreanParticle'), ('공연', 'Noun'), ('가성', 'Noun'), ('비', 'Noun'), ('ㅆㅅㅌㅊ', 'KoreanParticle')]
사전 단어 추가후
words = [
('춘식','Noun'),('가성비','Noun')
]
for word in words:
name, poomsa = word
twi.add_dictionary(name, poomsa)
text = '춘식이 귀여웤ㅋㅋ 공연 가성비 ㅆㅅㅌㅊ'
print(twi.pos(text, norm=True))
# 결과
[('춘식', 'Noun'), ('이', 'Josa'), ('귀엽다', 'Adjective'), ('ㅋㅋ', 'KoreanParticle'), ('공연', 'Noun'), ('가성비', 'Noun'), ('ㅆㅅㅌㅊ', 'KoreanParticle')]불용어 제거 및 토큰화
from keras.preprocessing.text import Tokenizer
# 불용어 제거 및 토큰화
stopwords = ['의', '가', '이', '은', '는', '과', '도', '를', '으로', '자', '에', '세요', '니다', '입니다',
'하다', '을', '이다', '다', '것', '로', '에서', '그', '인', '서', '네요', '음', '임','랑',
'게', '요', '에게', '엔', '이고', '네', '거', '예요', '이에요', '어요', '여요', '하여', '하고']
text_token = []
for sentence in tqdm(total_df['reviews']):
tmp = []
tmp = twi.morphs(sentence, stem=True, norm=True) #토큰화
tmp = [word for word in tmp if not word in stopwords] #불용어 제거
text_token.append(tmp)
tokenizer = Tokenizer()
tokenizer.fit_on_texts(text_token)
정수인코딩, 패딩
정수로 인코딩하기 전, 전체 등장 빈도에서 2번 이하로 등장한 희귀 단어의 빈도 비율이 1.51 % 정도 밖에 안되기 때문에 제거해주었습니다. 총 단어 집합의 크기는 25935개가 나왔습니다.
# 정수인코딩
tokenizer = Tokenizer(num_words = vocab_size)
tokenizer.fit_on_texts(text_token)
X = tokenizer.texts_to_sequences(text_token)패딩하기전, 어느정도로 패딩값을 정해야 할지 기준을 정합니다.
def below_threshold_len(max_len, nested_list):
cnt = 0
for s in nested_list:
if(len(s) <= max_len):
cnt = cnt + 1
print('전체 샘플 중 길이가 %s 이하인 샘플의 비율: %s'%(max_len, (cnt / len(nested_list))*100))
max_len = 44
below_threshold_len(max_len, X)
plt.hist([len(review) for review in X], bins=50)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()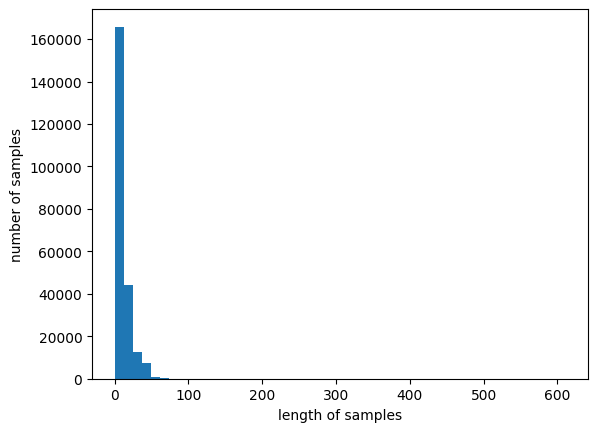
댓글의 평균 길이가 약 11.14 이었고, 최대값이 611.
max_len = 44 으로 했을 때, 전체 댓글 샘플중 99% 보존됩니다.
# 패딩
from tensorflow.keras.preprocessing.sequence import pad_sequences
X = pad_sequences(X, maxlen = max_len)
y = total_df['sentiment']모델링
데이터셋 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 42)
X_train = np.array(X_train)
X_test = np.array(X_test)
LSTM
초기에 과적합이 심하게 발생되는거 같아서 Dropout 과 EarlyStopping 조건을 추가해줬습니다. (training loss는 감소하는 반면에 validation loss값이 4회 증가하면 정해진 에포크가 도달하지 못하였더라도 학습을 조기 종료)
from tensorflow.keras.layers import LSTM, Dropout
with tf.device('/device:GPU:0'):
embedding_dim = 100
hidden_units = 128
model = Sequential()
model.add(Embedding(vocab_size, embedding_dim))
model.add(LSTM(hidden_units))
model.add(Dropout(0.6)) # 드롭아웃 추가
model.add(Dense(1, activation='sigmoid')) # 클래스 개수에 맞게 수정
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)
mc = ModelCheckpoint('best_model.h5', monitor='val_acc', mode='max', verbose=1, save_best_only=True)
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=10, callbacks=[es, mc], batch_size=64, validation_split=0.1)
model.save('/content/lstm_08.h5')
결과 8번째 에서 조기 종료되었습니다.
- 정확도 0.84 loss 0.36
Epoch 1/10
2434/2434 [==============================] - ETA: 0s - loss: 0.4078 - accuracy: 0.8139WARNING:tensorflow:Can save best model only with val_acc available, skipping.
2434/2434 [==============================] - 70s 25ms/step - loss: 0.4078 - accuracy: 0.8139 - val_loss: 0.3651 - val_accuracy: 0.8390
Epoch 2/10
2434/2434 [==============================] - ETA: 0s - loss: 0.3446 - accuracy: 0.8508WARNING:tensorflow:Can save best model only with val_acc available, skipping.
2434/2434 [==============================] - 25s 10ms/step - loss: 0.3446 - accuracy: 0.8508 - val_loss: 0.3443 - val_accuracy: 0.8490
................
Epoch 8/10
2434/2434 [==============================] - ETA: 0s - loss: 0.2294 - accuracy: 0.9123WARNING:tensorflow:Can save best model only with val_acc available, skipping.
2434/2434 [==============================] - 18s 7ms/step - loss: 0.2294 - accuracy: 0.9123 - val_loss: 0.3464 - val_accuracy: 0.8545
Epoch 8: early stopping
loaded_model = load_model('/content/lstm_08.h5')
print("\n 테스트 정확도: %.4f" % (loaded_model.evaluate(X_test, y_test)[1]))
# 1803/1803 [==============================] - 8s 4ms/step - loss: 0.3636 - accuracy: 0.8471
# 테스트 정확도: 0.8471Bilstm
with tf.device('/device:GPU:0'):
embedding_dim = 100
hidden_units = 128
model = Sequential()
model.add(Embedding(vocab_size, embedding_dim))
model.add(Bidirectional(LSTM(hidden_units))) # Bidirectional LSTM을 사용
model.add(Dropout(0.6)) # 드롭아웃 추가
model.add(Dense(1, activation='sigmoid'))
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)
mc = ModelCheckpoint('best_model.h5', monitor='val_acc', mode='max', verbose=1, save_best_only=True)
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(X_train, y_train, epochs=15, callbacks=[es, mc], batch_size=128, validation_split=0.2)
model.save('/content/best_model_0726_2.h5')
loaded_model = load_model('best_model_0726_2.h5')
print("\n 테스트 정확도: %.4f" % (loaded_model.evaluate(X_test, y_test)[1]))
# 1789/1789 [==============================] - 10s 5ms/step - loss: 0.3650 - acc: 0.8497
# 테스트 정확도: 0.8497정확도 0.85 loss 0.37
lstm과 크게 차이가 없지만 정확도가 미세하게 좀더 높습니다.
모델적용
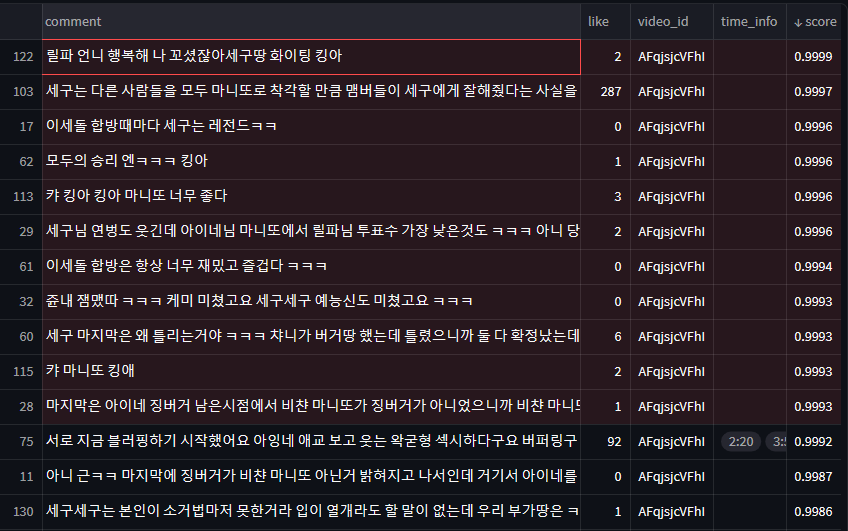
최근 영상의 댓글을 가져와서 bilstm 의 모델을 적용시켜 봤습니다.
부정적이나 중립적이다고 판단한 댓글의 경우는 확연하게 분류하지는 못했지만 확실하게 긍정적인 댓글을 긍정적으로 예측한 경우는 많았습니다. 그래도 일부 '고세구 팬 수준 ㅋㅋ 그러니까 시청자 꼴지지 ....' , '왜이렇게 어수선해요 ㅋㅋㅋ' , '틀딱 둘기인데 마니또가 뭔가요ㅜㅜ' 같이 부정적이거나 딱히 감정이 들어가있지 않은 혼잣말, 질문유형 같은 중립적인 문장에 낮은 score를 잘 주는것 같습니다.
부정/중립
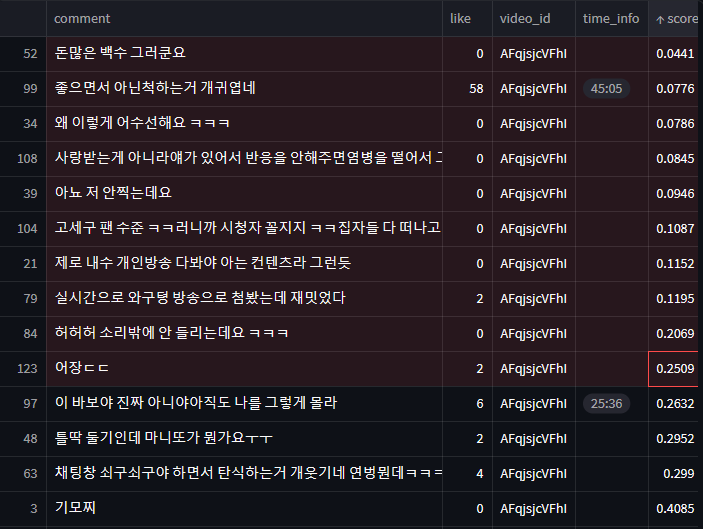
긍정
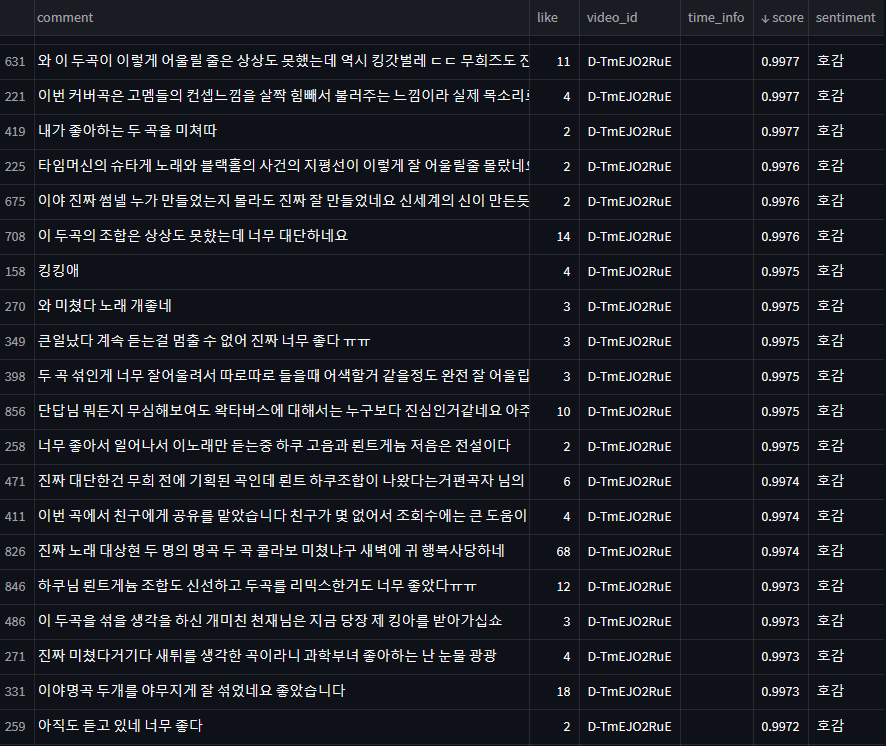
다른 영상의 댓글을 가져와서 좀 더 테스트 해봤습니다.
부정/중립
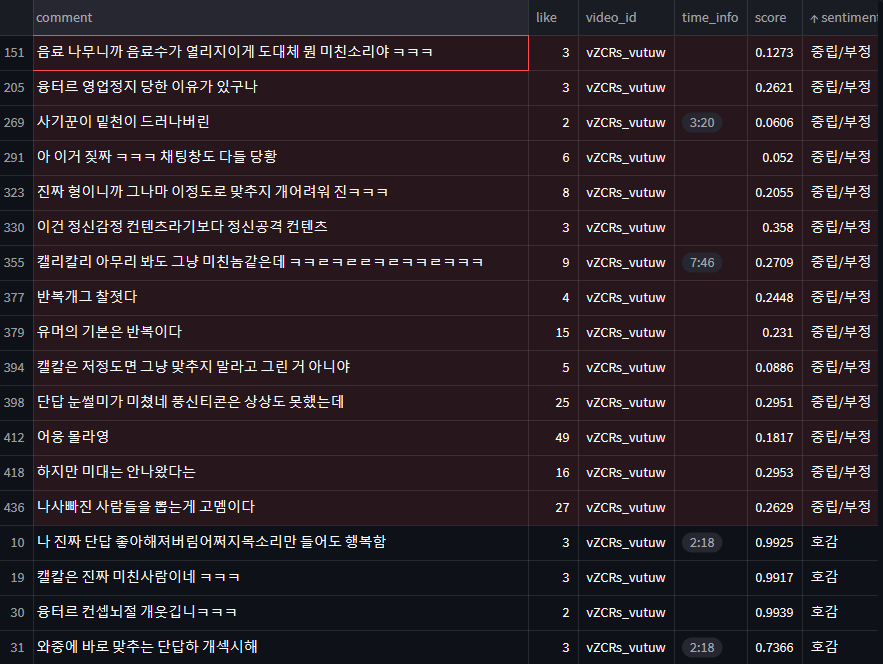
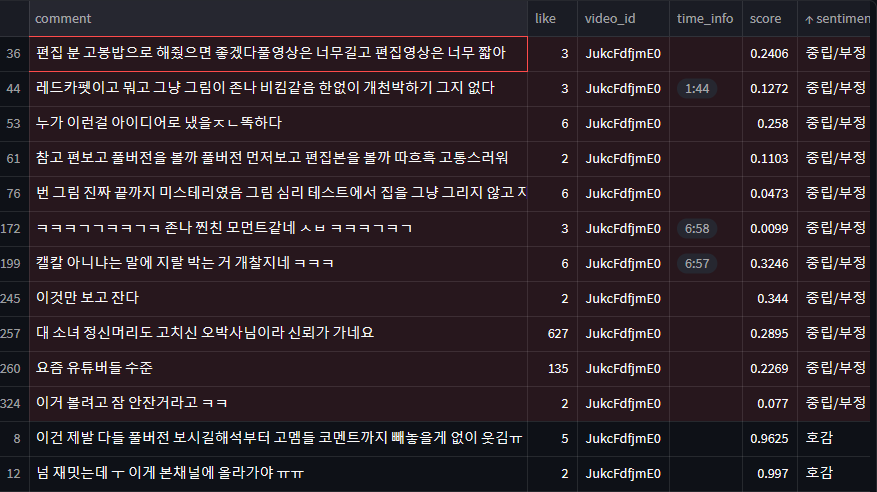
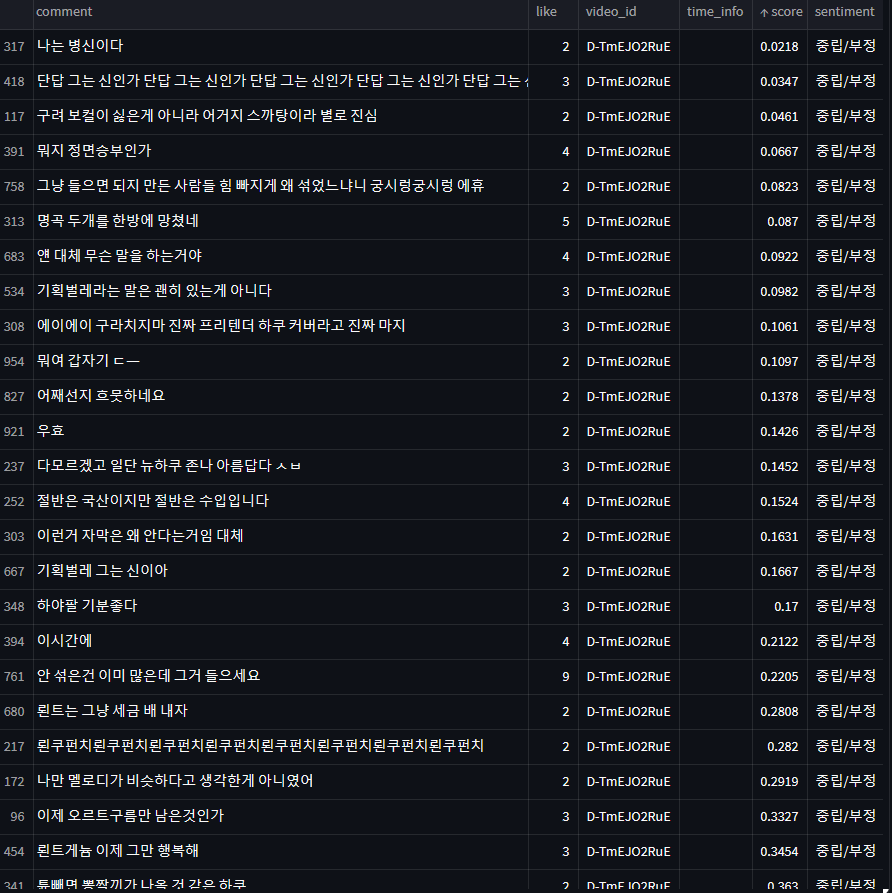
역시 문맥으로 파악했을 때 부정적이지 않은 댓글들을 부정적으로 판단하는 경우가 있었습니다만 🤔
"융터르 영업정지 당한 이유가 있구나" , "사기꾼이 밑천이 드러나버린" ,
"유머의 기본은 반복이다", "아웅 몰라영", "하지만 미대는 안나왔다는", "이것만 보고잔다",
"요즘 유튜버들 수준", "편집분 고봉밥으로 해줬으면 좋겠다 풀영상은 너무 길고 편집영상은 너무 짧아","구려 보컬이 싫은게 아니라 어거지 쓰까탕이라 별로 진심"
등과 같이 확실히 부정적인 감정을 표현하거나, 긍정적인 감정을 표현한다고는 좀 애매한 문장들을 낮은 score를 받았습니다.
하지만 "ㅋㅋㅋㄱㄱㅋㅋㄱㅋㄱ존나 찐친 모먼트같네 ㅅㅂ ㅋㅋㄱㅋㅋ" 의 경우, 욕설이 섞여 있지만 "부정적"이기 보다 "재미있음+과격한 표현"인 경우에 해당합니다.
또한, "캘칼 아니냐는 말에 지랄 박는 거 개찰지네 ㅋㅋㅋ" 같이 실제로 부정적인 문맥은 아니지만 과격한 표현으로 욕설이 포함된 경우, 부정적으로 인식이 되어버리는 것 같습니다. 아무래도 단어기반의 한계일까요
역시 이런 부분을 보완하기 위해서는, 양질의 데이터와 문맥을 이해하도록 훈련시킬 수 있는 BERT 같은 모델을 이용해보면 좋을 것 같습니다.
+ 시각화 추가 (진행중..🕓)