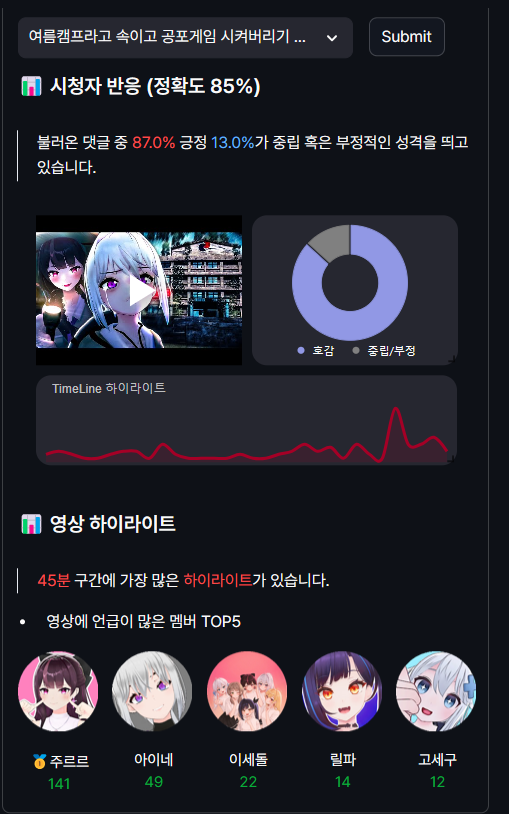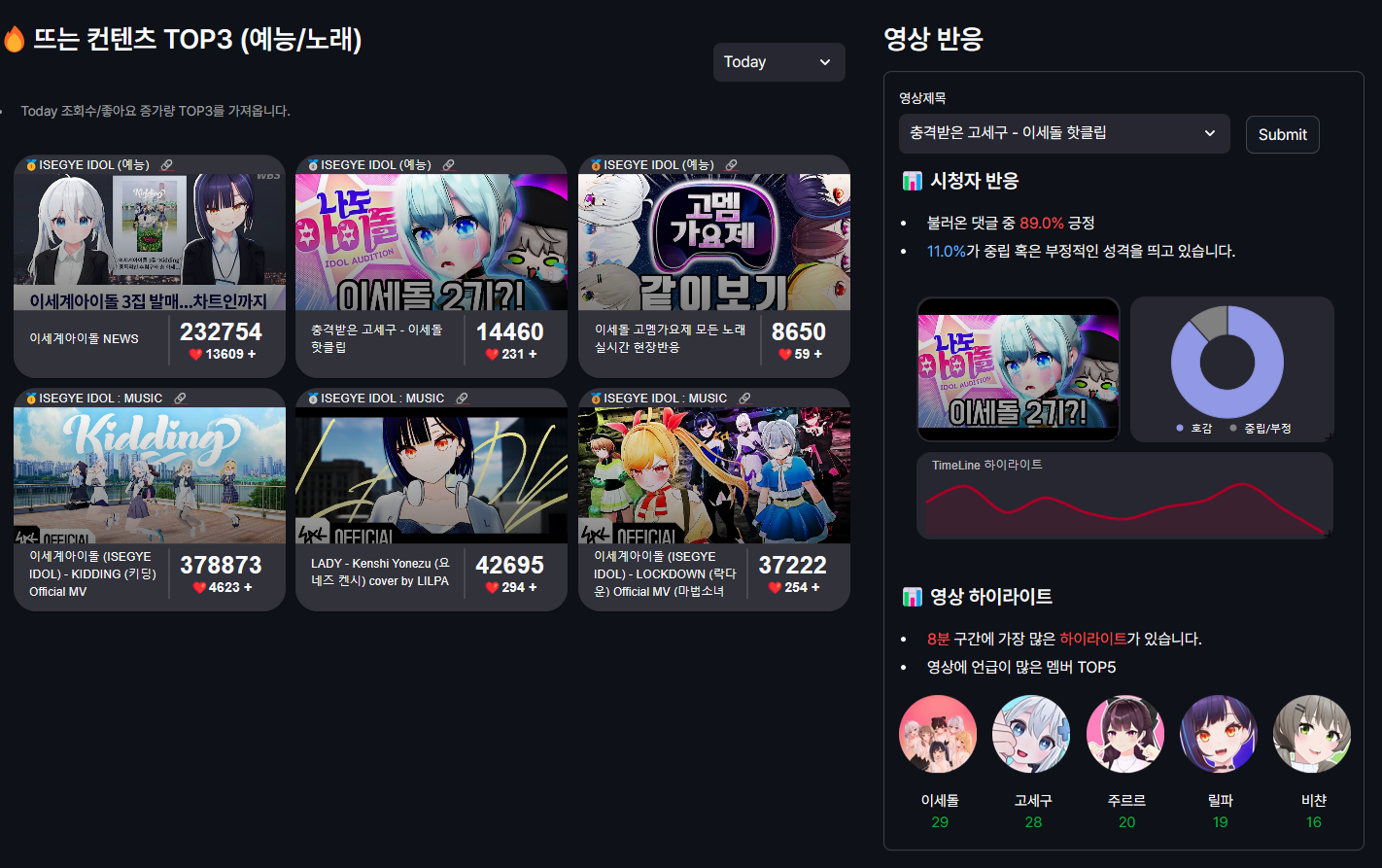
저번에 학습시킨 tokenizer 와 model을 streamlit에 연동시켜. 해당 영상의 댓글 반응 및 하이라이트, 그리고 언급이 많이된 멤버(keyword)들을 보여주는 일종의 영상반응 기능을 만들어 봤습니다! 👀
영상 제목을 선택하고 submit을 누르면 아래의 함수들이 실행됩니다.
💻def
get_comment
해당 제목의 videoId 에 해당하는 youtube 댓글들을 가져옵니다.
sentiment_predict
가져온 댓글들을 저번에 학습한 tokenizer 와 model를 이용하여 감성분석을 진행합니다. score 와 토큰화 및 불용어가 제거된tmp를 반환합니다. (댓글량이 많을수록 오래걸리기 때문에 일단, 댓글이 1000개 이상 넘어가는 경우 좋아요를 1개이상 받은 댓글들로 제한했습니다!) nivo_pie 차트를 이용하여 시각화했습니다.
extract_time_info
가져온 댓글들중 시청자들이 언급한 timeline을 가져와 영상의 하이라이트 구간이 어딘지 나타냅니다. nivo_line 차트를 이용하여 시각화했습니다.
# 댓글 가져오고 / sentiment 적용 / timeline 요약
def get_comment(videoId):
# videoId = 'Lm1AiWIMbO0'
comments = list()
response = youtube.commentThreads().list(part='snippet,replies', videoId = videoId, maxResults=100).execute()
while response:
for item in response['items']:
comment = item['snippet']['topLevelComment']['snippet']
comments.append([comment['textDisplay'], comment['likeCount']]) # comment['publishedAt'],
if item['snippet']['totalReplyCount'] > 0:
for reply_item in item['replies']['comments']:
reply = reply_item['snippet']
comments.append([reply['textDisplay'], reply['likeCount']]) #reply['publishedAt'],
if 'nextPageToken' in response:
response = youtube.commentThreads().list(part='snippet,replies', videoId = videoId, pageToken=response['nextPageToken'], maxResults=100).execute()
else:
break
comment_df = pd.DataFrame(comments)
comment_df.columns = ['comment', 'like']
comment_df['video_id'] = videoId
def extract_time_info(comment):
time_pattern = r"(\d+:\d+)</a>" # youtube timeline 의 경우, </a> 태그로 감싸져있음.
time_info = re.findall(time_pattern, comment)
return time_info
comment_df['time_info'] = comment_df['comment'].apply(extract_time_info)
comment_df['comment'] = comment_df['comment'].apply(lambda x: re.sub('[^ㄱ-ㅎㅏ-ㅣ가-힣 ]+', '',x))
comment_df['comment'] = comment_df['comment'].apply(lambda x: emoticon_normalize(x, num_repeats=3))
if len(comment_df['comment']) > 1000: # 댓글이 1000 개 이상인경우 좋아요 조건
comment_df = comment_df[comment_df['like'] > 1]
comment_df[['score', 'tmp']] = comment_df['comment'].apply(lambda x: pd.Series(sentiment_predict(x)))
else:
comment_df[['score', 'tmp']] = comment_df['comment'].apply(lambda x: pd.Series(sentiment_predict(x)))
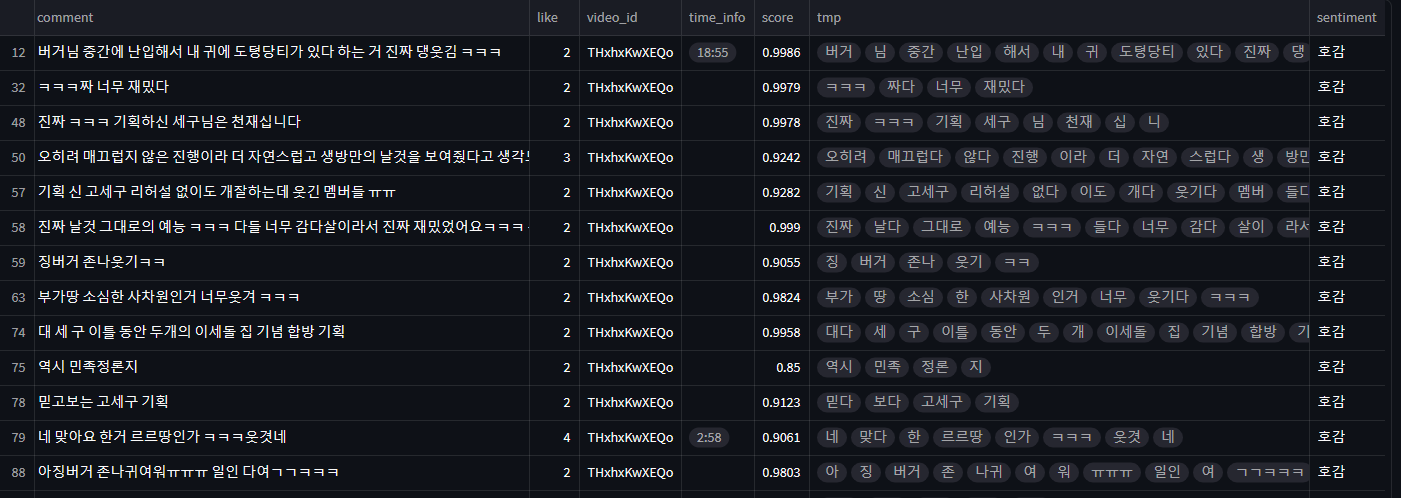
return comment_dfcomment_df 의 결과는 아래와 같습니다.
wordCount
def wordCount(comment_df):
all_tmp = [word for sublist in comment_df['tmp'] for word in sublist] # word = 리스트 속 ['단어들']
# 통일된 단어들만 추출
unified_words = []
for word in all_tmp:
for unified_word, variations in word_rules.items():
if word in variations:
unified_words.append(unified_word)
break
unified_tmp = Counter(unified_words)
most_common_words = unified_tmp.most_common(10)
return most_common_words
해당 영상의 가장많이나온 keyword가 무엇인지 나타내보았습니다. 토큰화와 불용어가 제거된 tmp들을 한 리스트에 담고 정해놓은 word_rule을 기반으로 해당영상에서 가장 많이 언급된 멤버들을 요약합니다.
word_rule 의 예시입니다.
'챠니' , '챤이', '비챤' 등 모두 '비챤'이라는 단어를 뜻하기 때문에 한단어로 통일하는 작업이 필요했습니다. (물론 사전에 댓글들을 토큰화 할때 ckonlpy를 통해 사전작업을 해놔야합니다.)
"비챤" : ['챠니','챤이','비챤','차니','지구즈','개나리즈'],
처음에 가장 많이 나온 단어들을 뽑아 봤지만 'ㅋㅋㅋ' 같은 인터넷 용어들이 거의 상위권에 있는경우가 많았습니다. 그래서 범위를 줄여서 '가장 언급이 많은 멤버'를 기준으로 하면 더 재밌을것 같았습니다. 그래서 해당 멤버들을 기준으로 키워드를 집계 해보았는데요! 명사뿐만 아니라 다른 품사들도 천천히 보충해보려고 합니다.😅
(영상에 인기멤버 뿐만 아니라 해당영상의 어떤점이 재밌는지 어떤 키워드가 있는지 같은? 그냥 오히려 wordcloud를 이용해도 좋을 것 같습니다.)
get_member_images
영상에 언급이 많은 멤버를 이미지로 나타내봤습니다.
🚨주의. 모델 불러오기
학습시킨 토크나이져와 모델을 st.cahe_resouce, st.cache_data 를 이용해 이벤트가 실행 될때마다 계속 불러오지 않도록 합시다.
# 토크나이져
tokenizer_pickle_path = "C:/scraping/model/tokenizer.pickle"
with open(tokenizer_pickle_path, "rb") as f:
tokenizer = pickle.load(f)
# 모델
@st.cache_resource
def loaded_model():
model = load_model('C:/scraping/model/Bilstm.h5')
return model
nlp_model = loaded_model()
# 토크나이져
@st.cache_data
def load_tokenizer():
with open(tokenizer_pickle_path, "rb") as f:
tokenizer = pickle.load(f)
return tokenizer
tokenizer = load_tokenizer()
나중에 배포할때 고려할게 많아졌습니다..!! 일단 쓰이는 API KEY가 2개 이상입니다. ( Youtube api, GCP api ) git에 배포시 잘숨겨야할것 같습니다.
또 해당 Model을 실제로 외부 사람들도 이용하려면 어떻게 해야되는지, 배포시에는 어떻게 불러와야하는지 공부를 해야될 것 같습니다. 효율적으로 하고 있는지 잘모르겠군요. 헤헤 아직멀었지만 이왕 한거 배포까지는 해봐야죠!
(물론, 아직 안끝났습니다!🤤)
결과!
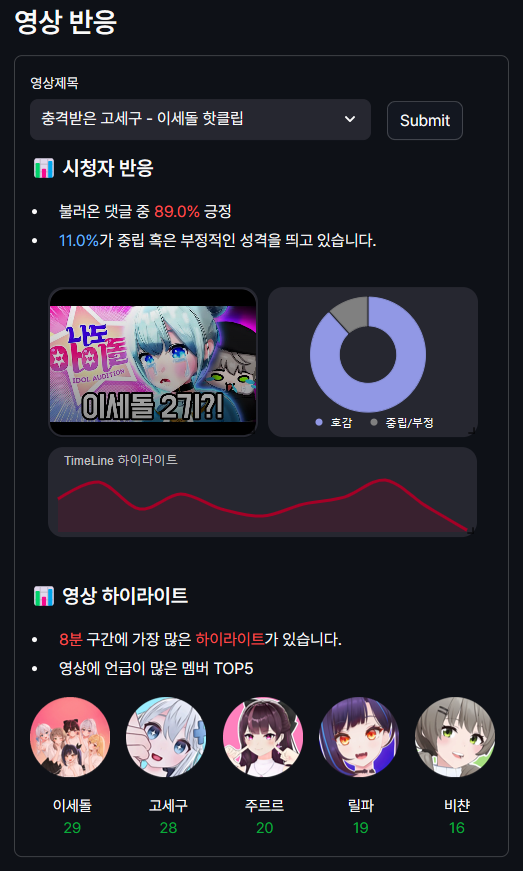
- 충격받은 고세구! 의 영상의경우, 89%가 긍정, 11%가 중립 혹은 부정적인 성격을 띄고 있습니다. (정확도는 85%입니다.)
- 그리고 시청자가 언급한 기준으로 8분대에 가장 많은 하이라이트 장면이 있군요 ㅎㅎ
- 이세돌 핫클립 영상이기 때문에, 이세돌 멤버들의 언급이 많았는데요. 그중에서도 해당 영상의 썸네일의 주인공인 '고세구'님이 가장 많이 언급되었습니다.😁
추가 기능
해당영상에서 어떤 구간이 시청자의 픽 인지 바로 파악할 수 있도록 썸네일 클릭시 하이라이트 구간이 재생되도록 설정해보았습니다 😀