우왁굳님의 많은 영상들 중에서 핫한 컨텐츠중 하나가 바로 고정멤버분들과 함께하는 영상인데요. (줄여서 고멤!)
고멤분들을 보면 마치 게임 캐릭터 같다는 생각이 들었습니다. 지금은 워낙 멤버들이 다양해져서 고멤, 아카데미, 인턴 으로 나뉘어져 있는데요! 활동을 오래 하다보니 어느순간 각자 포지션이 만들어져 있는게 마치 캐릭터의 능력치 같달까요..😀?
예능으로 치면 무한도전에서 노홍철님과 박명수님이 '공격'하는 포지션 이면, 정준하님은 잘받아주는, 흔히말하는 '탱커' 포지션 이라고 알려져 있듯이ㅋㅋ 방송에서 재밌는 상황을 만들고 티키타카 할 수 있는 다양한 매력을 갖고 계십니다.
그래서 이번에는 고정멤버와 관련되서 무엇을 할 수 있을까 고민해봤습니다. youtube analytics에는 없는 왁타버스 채널만을 위한 분석을 해보고 싶었는데 말이죠. 🤔
일단 "왁타버스 고멤합방(예능)" 과 관련된 영상을 모아서..!!
- 댓글을 전부 긁어모아 어떤 고멤들이 활약을 했는지, 한마디로 어떤 고멤분들이 폼이 미쳤는지 ㅋㅋ(?)
월별 언급량을 나타내보면 재밌겠다고 생각했습니다. - 고멤, 고멤아카데미, 인턴 중에서 고멤분들을 우선 해보려고합니다
결국, 올라온 영상에서 시청자들이 언급을 많이했다는 것은 그 만큼 관심을 받고, 재밌어한다는 이유라고 생각이 들었습니다. 또한 시청자들이 현재 어떤 고멤들을 관심있게 보고 있는지 어느정도 파악도 가능할 것 입니다!
물론 왁타버스 채널이외에 본채널, 클립채널(돋거) 에도 고멤분들의 영상이 올라오기 때문에 관심도를 확인하려면 전부 합쳐야 할텐데요! 일단 왁타버스 고정멤버 영상의 경우 '왁타버스' 채널에 가장 많이 올라오기 때문에 해당 채널에 올라오는 영상들을 기준으로 측정 해보았습니다!
(2023-09-06) 왁타버스 채널과 본채널의 Vrchat 재생목록도 추가해서 측정했습니다!
댓글 수집
모든 영상을 가져오지 않고 고멤이 주로 나오는 재생목록 "WAKTAVERSE : GOMEM" 과 "Vrchat" playlistID 를 가져와 해당 플레이리스트의 video_id를 전부 수집했습니다.
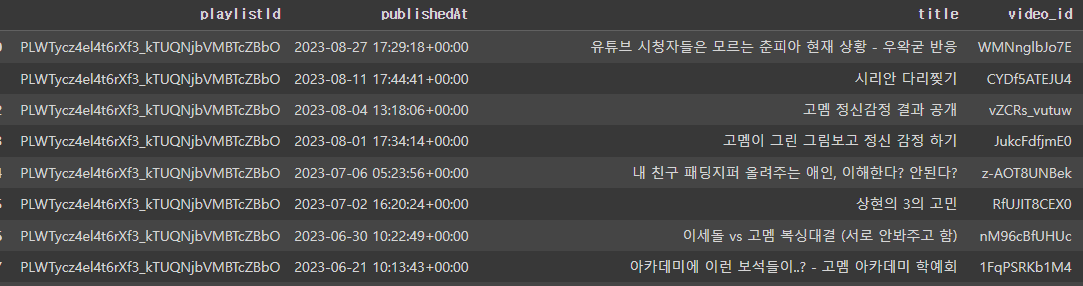
그리고 video_Id를 list로 뽑아서, 해당 video_id에 해당하는 comment 들을 수집했습니다.
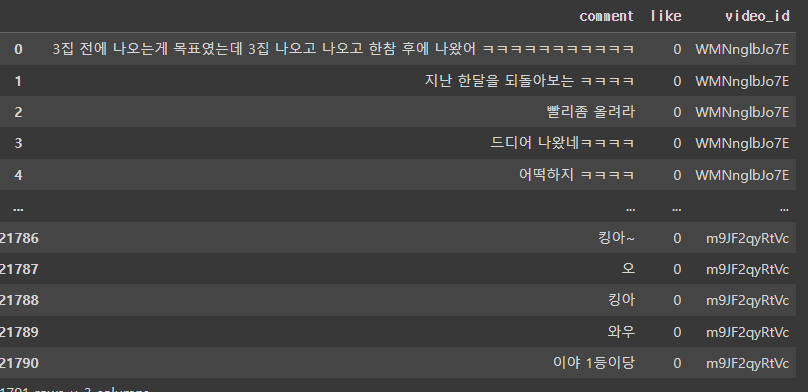
이제 어떤 영상, 언제 올라온 영상의 댓글인지 정보를 추가하기 위해서 video_id 를 기준으로 merge 해주었습니다. 월별 집계를 위해 PublishedAt 에서 year 와 month 컬럼을 따로 추가해주면 최종적으로 아래와 같은 dataframe이 완성됩니다.
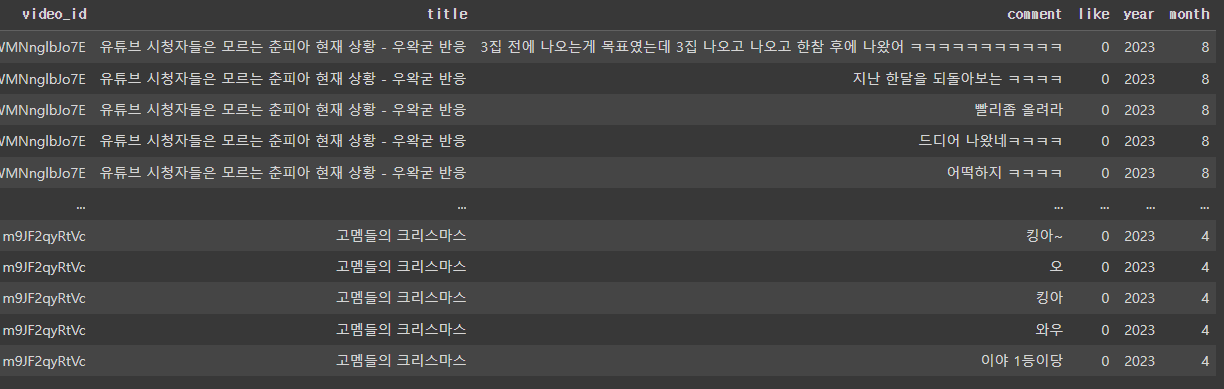
저번 감성분석때 사용한 코드를 바탕으로 일부 필요 없는 댓글들을 전처리하고 해당 comment 들의 (text_token) tmp 들을 구해준 다음 video_id, month 별로 합쳐주었습니다.
한행에 해당 영상의 모든 comment 들의 text_token 들이 저장되어있습니다.
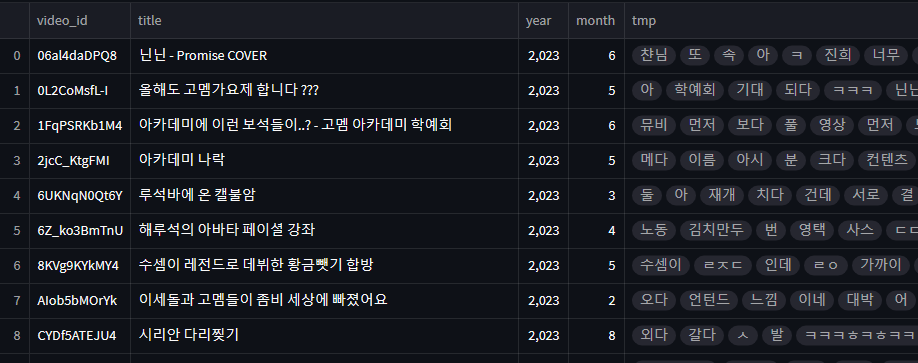
그리고 고멤분들 역시 지칭하는 형식이 사람마다 다르고 별칭이 꽤 있기 때문에 최대한 잘 집계하기 위해서 어느정도 맞춰 줘야합니다ㅎㅎ.. 해당 토큰을 아래의 기준에 따라 모두 대표단어로 바꿔주는 작업을 했습니다.
# 단어를 통일시키는 함수
def unify_word(word, gomem_word):
for key, values in gomem_word.items():
if word in values:
return key
return word
def unify_tmp(tmp, gomem_word):
return [unify_word(word, gomem_word) for word in tmp]
```python
def gomem_comment(df, col, year, month):
if month == 'all':
df = df[df['year'] == year]
else:
df = df[(df['year'] == year) & (df['month'] == month)]
all_tmp = [word for sublist in df[col] for word in sublist] # word = 리스트 속 ['단어들']
gomem_word = {
"뢴트게늄" : ['뢴트게늄','뢴트','초코푸딩'],
"해루석" : ['루숙','해루석','해루숙','루석'],
"캘리칼리": ['캘칼', '캘리칼리', '캘리칼리데이빈슨'],
"도파민" :['도파민','파민','박사'],
"소피아" : ['소피아','춘피아'],
.....
}
# 통일된 단어들만 추출 (gomem_word에 있는 단어들만 포함)
unified_tmp = unify_tmp(all_tmp, gomem_word)
unified_tmp = [word for word in unified_tmp if word in gomem_word]
#리스트의 원소들이 각각 몇개씩 있는지 알고싶을 때 Counter()
unified_tmp = Counter(unified_tmp)
most_gomem = unified_tmp.most_common(5) # top5
return most_gomem
most_gomem = gomem_comment(df,'tmp',2023,8) # 2023년 8월의 most gomem
print(most_gomem)
> [('히키킹',116),('소피아',114),('캘리칼리',97),('독고혜지',41),('왁파고',38)] #딕셔너리 타입으로 결과가 나온다.
gomem_commentunify_wordunify_tmp
- 함수의 목적:
'tmp'에 있는 각 단어를 통일시키고 집계tmp: 이는 리스트 형태로 단어들을 포함하고 있는 변수.gomem_word: 단어 통일 규칙을 정의한 딕셔너리.
tmp에 있는 각 단어(word)에 들을 가져와서, 각 단어(word)를unify_word함수에 전달하여gomem_word에 정의된 단어 규칙에 따라 통일시켜 리스트 형태로 반환 ( → Count() 함수를 이용하여 집계 하기위해)
예를들어 gomem_word가 아래와 같을 때
gomem_word = {
"뢴트게늄" : ['뢴트게늄','뢴트','초코푸딩'],
"해루석" : ['루숙','해루석','해루숙','루석'],
"캘리칼리": ['캘칼', '캘리칼리', '캘리칼리데이빈슨'],
"도파민" :['도파민','파민','박사'],
"소피아" : ['소피아','춘피아'],
.....
}-
tmp = ['뢴트','개꿀잼','초코푸딩','뭐냐','ㅋㅋㅋ','루숙','대상현'] 이 다음과 같다면
tmp리스트속 word를 하나 씩unify_word에 적용시켜 if word in values 인 경우에만 해당 word를 가져온다! 그 word 들을 리스트 형태로! 합치면 ['뢴트게늄','뢴트게늄','해루석'] 이 남는다.(=unified_tmp) -
unified_tmp를 Counter() 함수로 집계를 해주면 [('뢴트게늄',2) ,('해루석',1)] list 속 dict 형태의 데이터가 나온다.
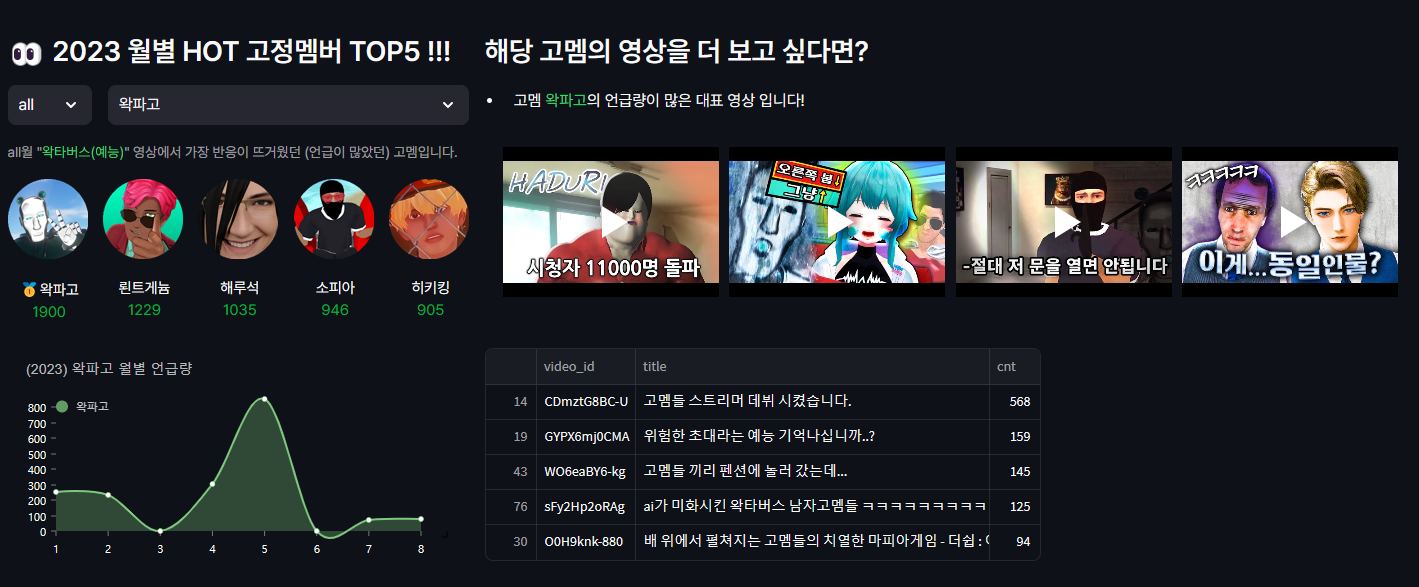
고정멤버 TOP5 !!
그리고 해당 의 key(고멤이름) 값과 count(언급횟수)이 저장된
most_gomem결과를 통해 img를 불러와주고 , nivo 그래프에서 요구하는 형식으로 전처리해서 아래와 같이 표현해봤습니다 ㅎㅎ
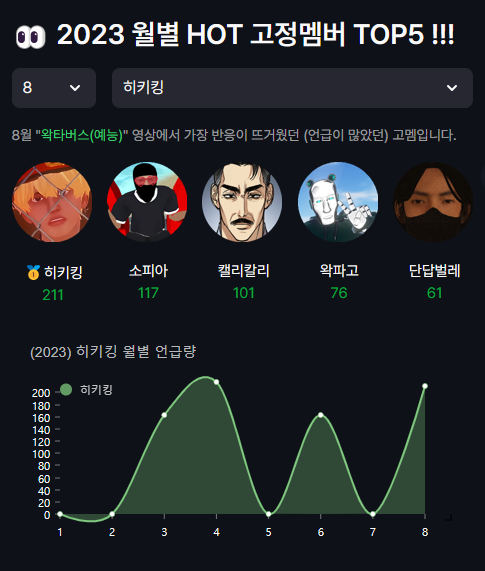
월별로 어떤 고멤이 관심을 받았는지 확인할 수 있고, 해당 고멤을 선택해서 2023년 월별 언급량을 확인할 수 있습니다.
2023년 8월의 HOT 멤버 1등은 히키킹님 이군요!! 상반기 하반기 대체적으로 큰관심을 받고 있습니다😀!!
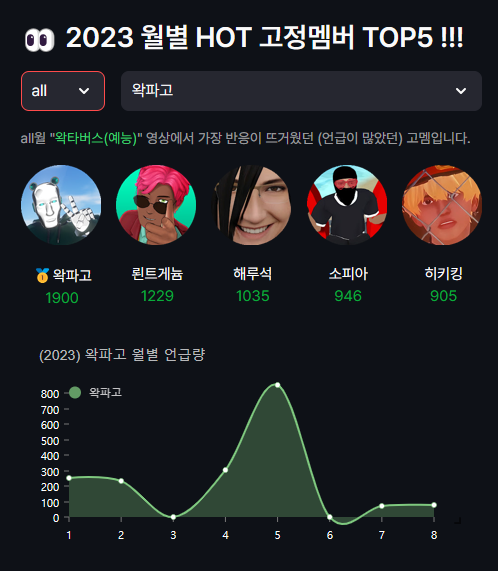
(전체) 2023년도 1월부터 8월 까지의 요약을 봐볼까요?
왁파고님이 1900번으로 가장 많은 언급량을 받았네요. 2위는 뢴트게늄님, 3위 해루석님,4위 소피아님, 5위 히키킹님이 그 뒤를 차지했습니다! 제가 생방송을 자주 챙겨보는데 느끼는바와 거의 비슷했습니다ㅎㅎ
특히 왁파고님의 경우 5월달에 800번이 넘는 압도적인 언급량이 나왔는데요! 과연 어떤 영상에 시청자들이 관심있게 봤는지 궁금하지 않으신가요 ㅋㅋ?
고정멤버 추천 영상
여기서 더 나아가서 관심을 많이 받은 고멤인 만큼, 어떤 영상에 언급량이 많았는지 궁금하고, 다른 영상들도 추천해주면 좋겠다는 생각이 들었습니다.
선택한 고멤의 영상중 관심을 많이 받은 영상 gomem_hot_video 를 가져와 봅시다!!!
예를 들어 gomem_video(df, '왁파고') 이라면 댓글 정보가 담겨있는
tmp컬럼에서 '왁파고'가 얼마나 언급되었는지 계산한 값을cnt컬럼에 저장하고, 가장 높은 상위 5개의 영상을 가져옵니다.
def count_word(word_list, target_word):
return word_list.count(target_word)
# 원하는 '고멤' 언급이 많은 video_id 찾기
def gomem_video(df, gomem):
# '고멤' 단어가 언급된 빈도를 계산하여 데이터프레임에 추가
df['cnt'] = df['tmp'].apply(lambda x: count_word(x, gomem))
gomem_hot_video = df[df['cnt'] == df['cnt']].nlargest(5,'cnt')[['video_id','title','cnt']]
# 결과 출력
return gomem_hot_video테이블과 같이 보면 아래와 같습니다! 5개 영상중 4개만 가져 와봤습니다!!
'고멤 스트리머 데뷔시켰습니다.', '위험한 초대라는 예능 기억나십니까..?','고멤들 끼리 펜션에 놀러갔는데..' 순으로 언급량이 많군요. ( 위 영상들을 다 봤었는데 왁파고님 진짜 웃깁니다 ㅋㅋㅋㅋㅋ🤣)
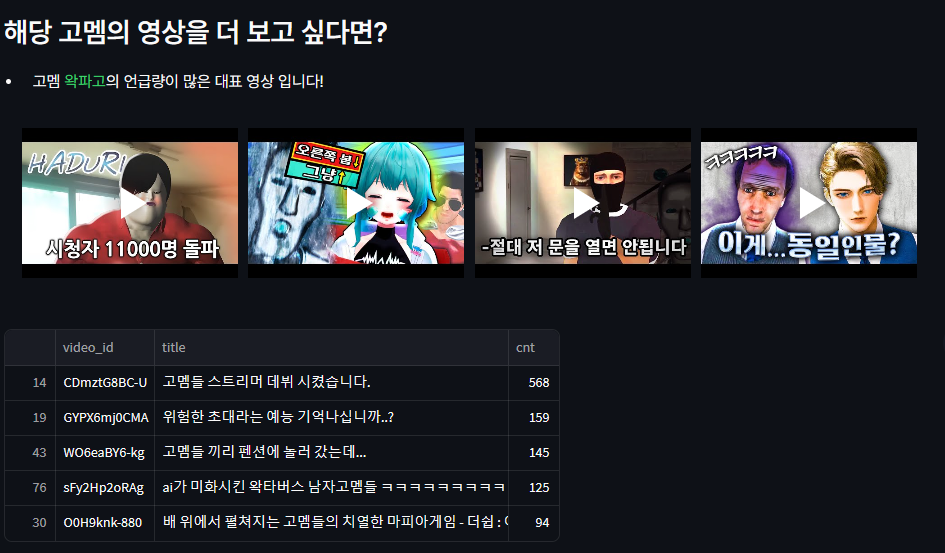
만약 고정멤버에 영상이 너무 많아서 보기 힘들때, 본인이 좋아하는 최애의 고정멤버의 영상이 많이 언급된 영상을 보고싶을때 유용할 것 같다는 생각이 듭니다 😀
