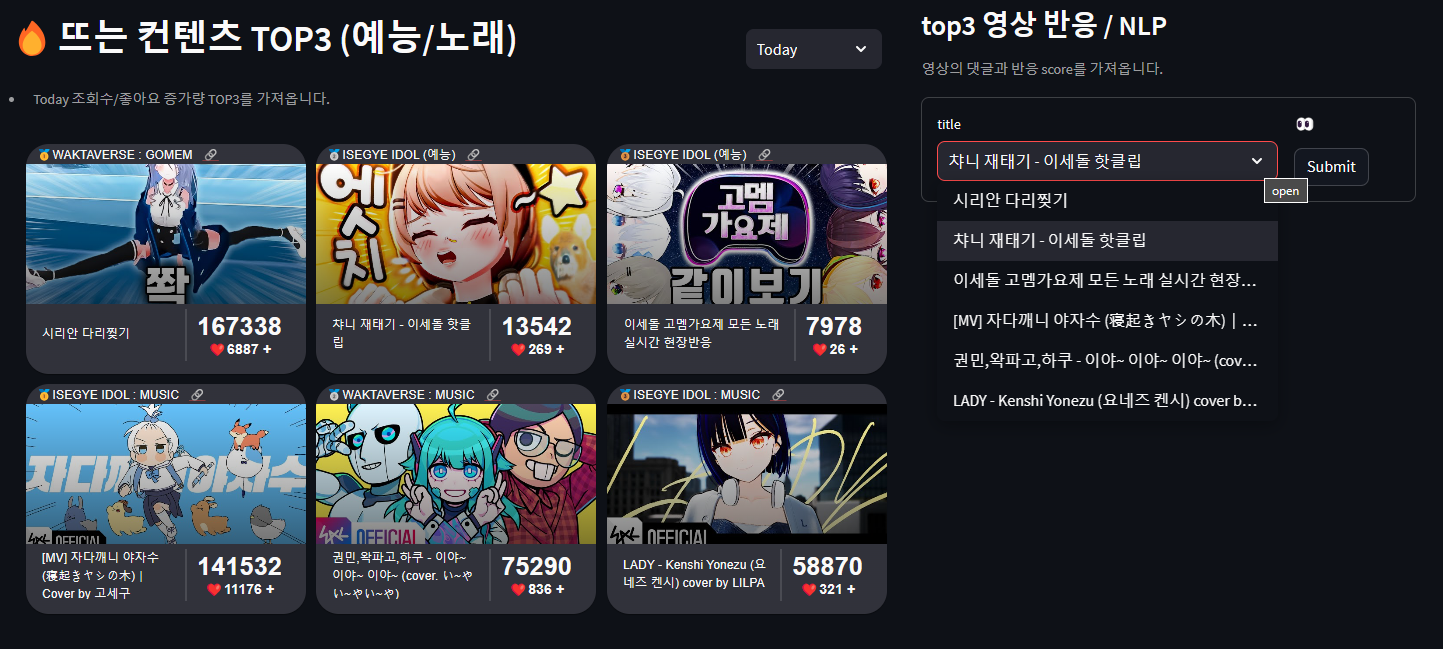
당일 조회수가 높게 상승한 top3 영상들 중에서 시청자들의 반응이 긍정적인지 부정적인지에 간단한 감성분석/ text 요약과 시청자들이 어떤 timeline을 가장 많이 언급했는지 영상 하이라이트구간을 시각화 해보려고 합니다! 먼저 영상 하이라이트 time_info 입니다.
time info 댓글
유튜브의 댓글을 보다보면 시청자들이 개인적으로 재밌어 하는 부분(타임라인)을 태그 하는데요. 이를 api로 가져오면<a href=> 3:12 </a> 태그 형태로 나타나는것을 확인 할 수 있습니다. 이 정보를 갖고 뭘할 수 있을까? 생각하던 도중. 사람들이 가장 재밌어 하고, 댓글까지 남긴 부분을 시각화하면 좋겠다 생각이 들었습니다.
def extract_time_info(comment):
time_pattern = r"(\d+:\d+)</a>" # youtube timetag 의 경우, </a> 태그로 감싸져있음.
time_info = re.findall(time_pattern, comment)
return time_info
comment_df['time_info'] = comment_df['comment'].apply(extract_time_info) 그래서 api로 불러온 comment_df['comment'] 의 댓글에서 a태그 안에 있는 '00:00' 형태의 값들을 전부 가져와서 따로 time_info 라는 컬럼을 추가해줬습니다.
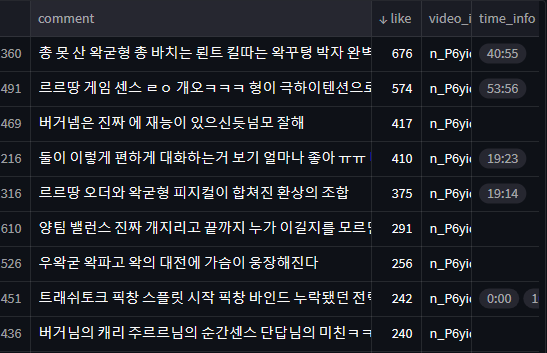
보통 유튜브 영상들이 5~10분이상이기 때문에 ,일단 time_info 값들을 '분' 기준으로 나눠봤습니다.
all_times = [time for times in comment_df['time_info'] for time in times]
minute_only = [int(time.split(':')[0]) for time in all_times]
# 구간별 빈도 계산
from collections import Counter
interval_counts = Counter(minute_only)
#nivo chart 데이터 형식으로 가공
nivo_time_info = [
{
"id": "view_info",
"data": [{"x": key, "y": value} for key, value in sorted(interval_counts.items())]
}
]
해당 데이터를 똑같이 nivo_chart 에 넣어주면 끝!
with st.container(): # time_info
with elements('hot_video_time_info'):
layout = [
dashboard.Item("first_item", 0, 0, 2, 0.8),
]
with dashboard.Grid(layout):
mui.Card( # nivo_line
mui.CardContent(
mui.Typography(
" TimeLine 하이라이트 ",
component="div",
color="text.secondary",
sx={"font-size":"12px",
"text-align" : "left"}
),
),
nivo.Line(
data= nivo_time_info,
margin={'top': 5, 'right': 10, 'bottom': 70, 'left': 10},
xScale={'type': 'point'},
yScale={
'type': 'linear',
'min': 'auto',
'max': 'auto',
'stacked': True,
'reverse': False
},
...... ,key='first_item') TOP3에 선정된 영상의 title을 고르고
submit을 누르면
해당 video_id를 가져와 해당 영상의 댓글 데이터들을 불러옵니다.
댓글 데이터프레임과 / time tag가 된 데이터를 추출해서 해당 영상의 하이라이트 구간을 요약해줍니다!!

이제 comment 데이터들을 저대로 두지 않고! 단발성 한국어 감정 데이터 + 한국어 리뷰 + 유투브 댓글을 라벨링하여 데이터를 학습 시킨 모델을 만들고, 긍/부정으로 분류해서 해당 영상의 민심 (?) ㅋㅋ 이 어떤지 확인해보려 합니다.
자연어처리는 예전에 잠깐 .. 공부해본 적 이 있는데 확실히 전처리 하는데 애를 먹네요... 아무래도 인터넷 용어, 신조어, 비속어들이 많기 때문에 많은 한국어 패키지들 중에 사전추가가 가장 편리한 customized konlpy가 가장 적합해 보였습니다.. 해당 내용은 이어서 작성해보도록 하겠습니다!
