(GCP) Google Cloud Functions/Scheduler/Storage 를 이용한 데이터 자동수집
Youtube(Waktaverse)채널 대시보드 및 분석

저번에 youtube api로부터 얻은 data를 구글 클라우드의 bigquery에 옮기는 것 까지는 확인을 했는데요!
여기서 더 궁금했던 것은 이를 자동화할 수 있는지, 컴퓨터가 꺼진 상태에서도 자동적으로 수집이 가능하도록 만들고 싶었습니다. 즉, 서버 없이 데이터를 수집하고 관리할수 있는지 찾아봤습니다.
(이미지 출처)
서버리스(serverless)란 ? 개발자가 서버를 관리할 필요 없이 애플리케이션을 빌드하고 실행할 수 있도록 하는 클라우드 네이티브 개발 모델
물론, 할당량이 존재하고 넘어서면 유료로 넘어가지만, 저의 경우 그렇게 큰 데이터를 관리하는것이 아니기 때문에 시험삼아 사용하기 딱 좋았습니다.
대략적인 과정, 파이프라인은 다음과 같습니다!
Cloud Functions (Youtube API 데이터 수집용 + 빅쿼리 to_gbq) 파이썬 스크립트 저장 →
Cloud Scheduler (정해진 시간에 자동적으로 함수 실행) →
BigQuery에 데이터 저장/관리 →
Streamlit 연결
파이프라인이라고 하기에 민망한데요.. 의도치 않은 곳에서 자꾸 에러가 나서 해결하는데 굉장히 오랜 시간이 걸렸네요.🤤
과정은 굉장히 간단합니다 ㅎㅎ 기본적인 실행방법과 제가 경험했던 에러들을 정리해보겠습니다.
Cloud Function
일단, Cloud Functions을 생성하려면 저번에 말했던 것처럼 프로젝트가 생성되어있어야합니다. 생성되어있다는 가정하에! 아래의 Cloud Functions에 들어가서 함수만들어 봅시다.
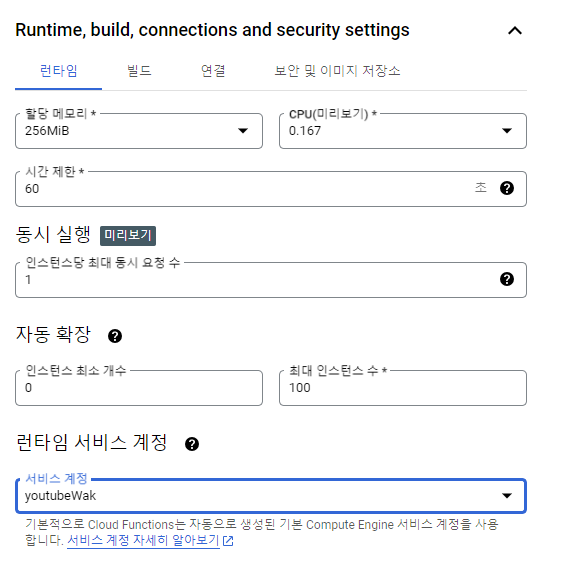
함수 이름은 직접 정해주시고 나머지 값들은 모두 기본값으로 두었습니다.
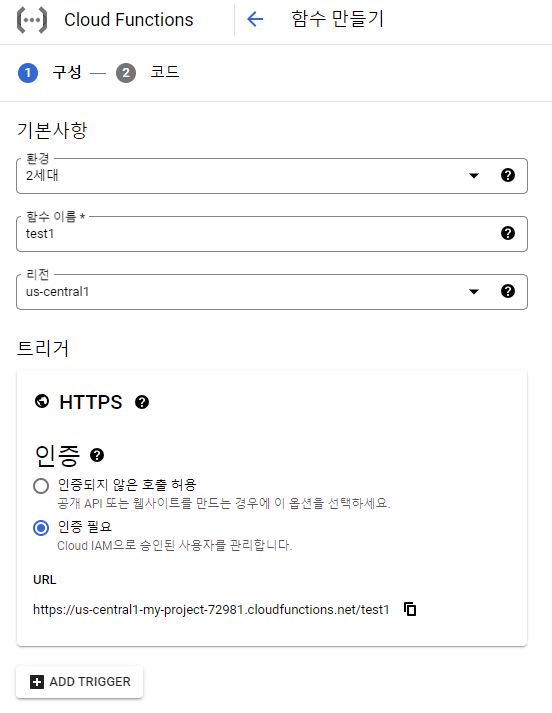
런타임, 빌드, 보안등 기본세팅입니다.
메모리 자원이 많이 필요하시면 필요한 만큼 늘려주시면되고 시간제한은 최대 60분 까지 설정이 가능하더군요. 그리고 런타임 서비스 계정을 사전에 만들어놓은 프로젝트 계정으로 등록했습니다.
( + 함수 실행 시간이 긴 경우를 고려해서 시간 제한을 수정해야합니다. 시간제한을 넉넉히 두시는것을 추천 드립니다. 저의 경우 데이터를 가져오는데 5분이상 걸리는걸 깜빡하고 시간 제한을 그보다 작게 했더니 최종적으로 스케쥴러에서 실패했다고 뜨더군요 🤔. 함수자체는 잘 작동되지만요)
✔️ What is HTTPS ?
HTTP는 요청과 응답을 통해 소통한다. 나(클라이언트) 와 서버 간의 데이터를 전달하기 위한 소통방식이다.
- HTTP: 인터넷 상에서 데이터를 주고받을 때 사용되는 프로토콜 암호화되지 않은 평문으로 데이터를 전송
- HTTPS: 데이터를 암호화하고 인증하는 보안 프로토콜입니다. HTTPS는 기밀성, 무결성, 인증성을 보장하여 중간자 공격이나 데이터 변조, 도용 등을 방지!
파이썬 함수 입력
위 과정을 거치고나면 본격적으로 실행할 함수를 등록하는데요. 저 같은경우 파이썬을 이용하기 때문에 런타임 python 3.11 그리고 해당 함수의 진입점을 입력해주시면됩니다!
코드는 소스코드로 직접입력하시거나, 압축파일이 있으시 첨부해 주시면됩니다.
저의 경우 전체 폴더 구조가 아래와 같습니다.
구조
my_project
├── main.py # 실행함수
├── my-project-72981-c4ea0ddcafb9.json # 빅쿼리 api 를 이용하기 위해 필요한 key
└── requirements.txt # 프로젝트에 설치된 모든 package
여기서 주의할 점은 해당 프로젝트에 쓰인 package 들을 requirements에 꼭 입력해주셔야합니다.
(pip install pipreqs 사용하시면 해당 프로젝트에만 쓰인 패키지들을 알수 있습니다.)
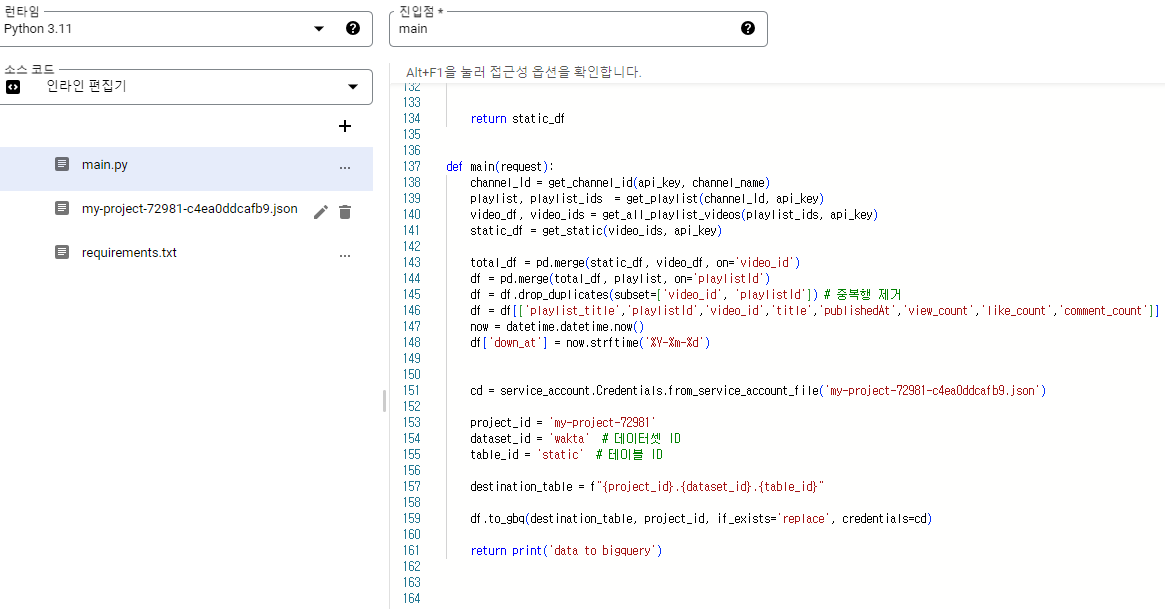
main.py
main.py는 youtube api 와 관련된 함수들 그리고 이 함수들로 data를 얻으면 빅쿼리로 전송하는 def main() 으로 이루어져있습니다. 그렇기 때문에 해당 데이터를 빅쿼리로 옮기는데 필요한 key.json 파일도 필요합니다. 같이 첨부 해줍시다! (중요한 key들은 환경변수로 해놓는 것을 더 권장드립니다.)
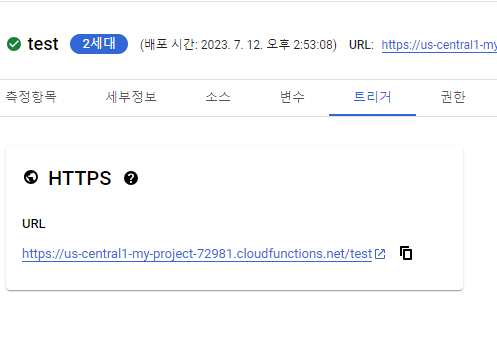
그리고 등록을 하면
아래와 같이 함수 트리거 URL 주소가 뜨고, 해당 URL를 복사해 두었다가! Scheduler에 등록하면 끝!!
또한, 아무나 함수를 사용할 수 없도록 위 함수를 호출할 수 있는 사람, 권한을 플랫폼안에서 정할 수 있습니다.
error 확인
발생한 에러의 대부분이 필요한 package 들을 requirements에 잘입력했는지, 위 함수를 이용할 권한이 있는 사용자인지 였습니다. 특히, 함수를 배포하는데 에러가 난다면 진입점과, 해당 패키키들이 전부 있는지 꼭 확인해봅시다!
Cloud Scheduler
해당 함수를 만들고 일정을 입력 해줍니다. 리전의 경우 직전에 만든 함수에 설정한 그대로 해주는게 좋다고 해서 그냥 두었습니다. 일정 빈도 부분은 unix-cron 형식을 사용하여 지정합니다. 저의 경우 매일 오후 6시에 함수가 작동되도록 설정했습니다.
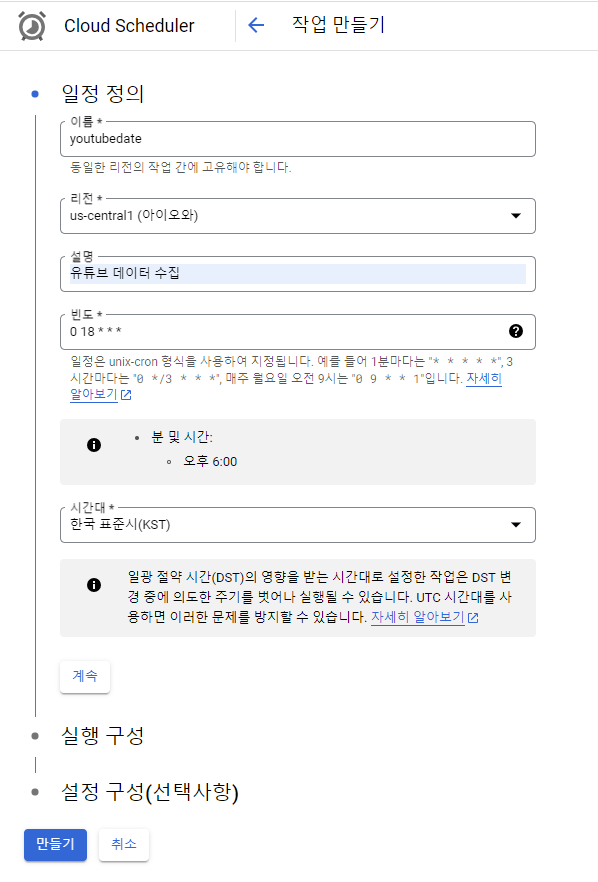
또한, 적절한 사용자 인증 정보가 있는 연결된 서비스 계정을 설정해서 Cloud Scheduler에서 인증이 필요한 HTTP 대상을 호출할 수 있습니다. 아무나 사용하지 못하도록 보안 권장사항이라고 생각하시면 됩니다. 자세한건 공식문서를 보시는게 더 빠르실 겁니다!
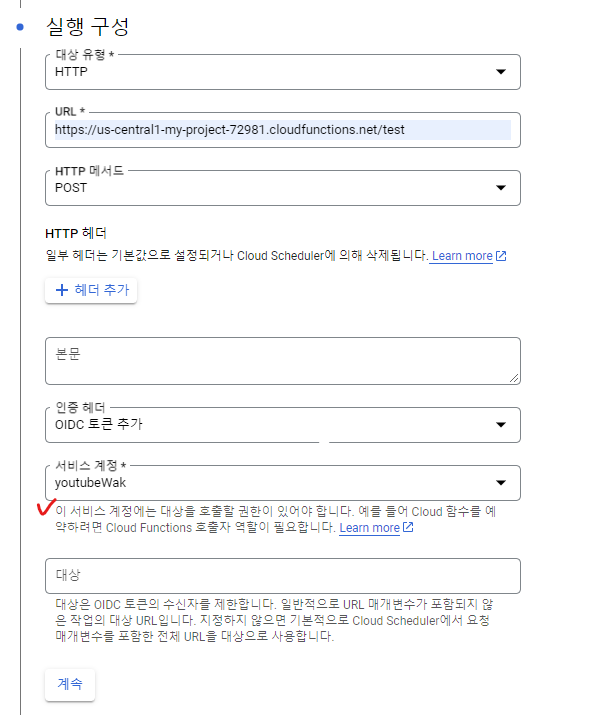
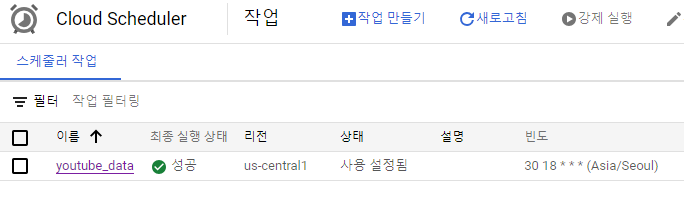
나머지 설정구성(선택)에는 필요한 만큼 설정 해주고, 등록을 하게되면 아래와 같이 스케쥴러 작업이 만들어지고 , 강제실행을 눌러서 해당 함수가 잘 작동 하는지 테스트할 수 있습니다.
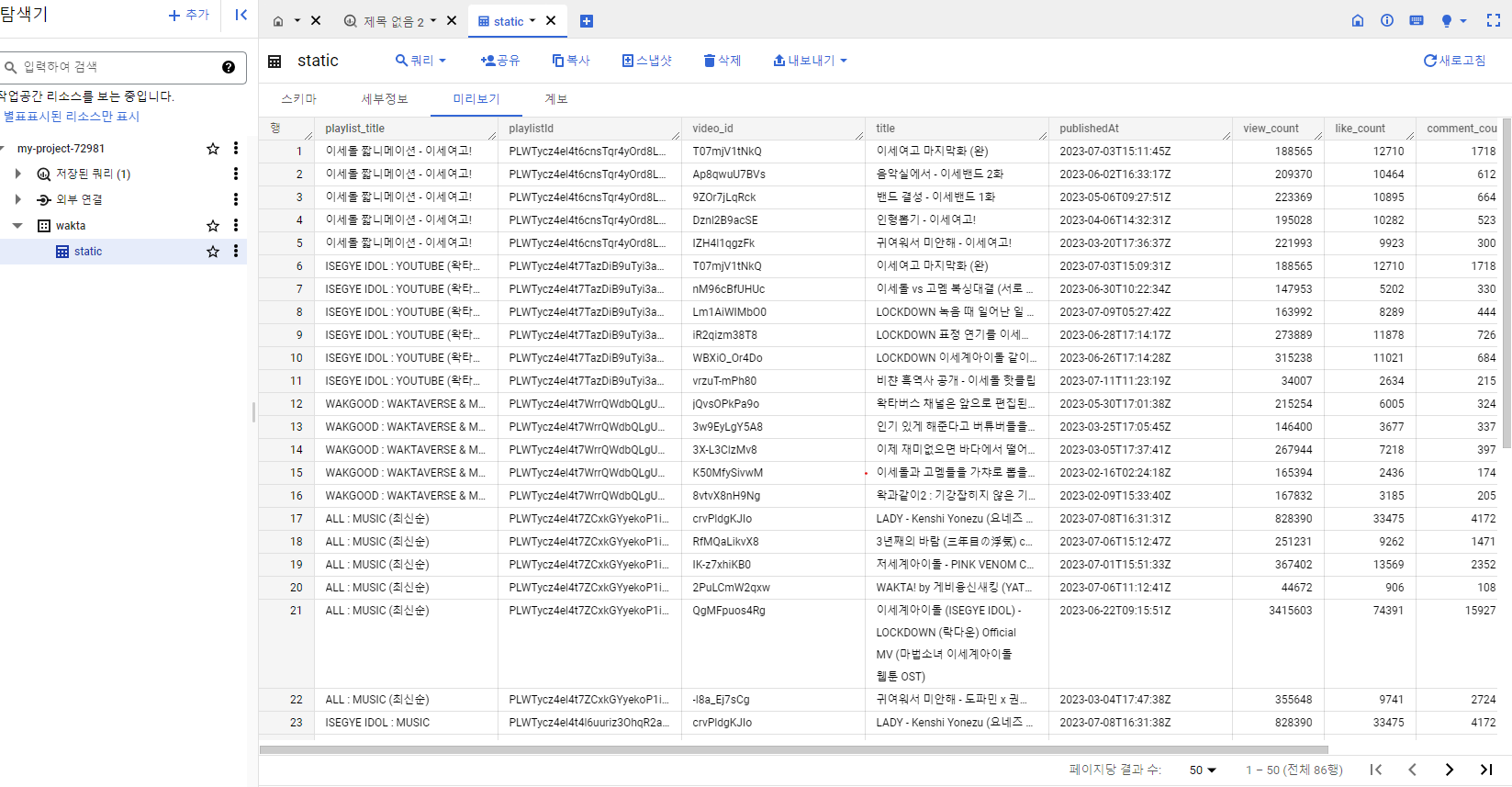
빅쿼리 확인
결과적으로 잘 전송된것을 볼 수 있습니다!
Cloud Storage
(+추가 storage)
만약에 빅쿼리로 바로 옮기지 않고 버킷에 저장하고 싶다면 아까 입력한 함수에서 빅쿼리로 전송하는 코드를 아래와 같이 바꿔주기만 하면 됩니다! ( 생각해보니까.. 아무래도 일단 데이터를 google cloud storage에 저장하고 원하는 데이터를 빅쿼리로 옮겨서 가공해야 하므로, 버킷에 먼저 저장하고 전처리가 필요하다면 따로 빅쿼리에 불러오는 함수를 써주면 될 것 같습니다.)
(+찾아보니 테이블의 경우 60일이 지나면 초기화 된다고 하는데 맞는지는 모르겠습니다! 90일 체험기간이긴 한데 말이죠 🤔.. 또한 빅쿼리에 불러오면 storage에 자동으로 저장되는 줄 알았는데 아니었습네요 하핳.. 결국 storage에 저장 해야합니다. (저장 기간이 있는지 더 찾아봐야겠다.)
from google.cloud import storage
import tempfile
credentials_file = 'key.json' # 경로
cd = service_account.Credentials.from_service_account_file(credentials_file)
client = storage.Client(credentials= cd)
# 데이터프레임을 CSV 파일로 저장
with tempfile.NamedTemporaryFile(delete=False) as temp_file:
df.to_csv(temp_file.name, index=False,encoding='utf-8-sig')
# 업로드할 버킷과 파일 경로 설정
bucket_name = '버킷이름'
blob_name = '파일이름.csv' # 버킷에 저장될 파일 이름
# 버킷과 연결된 Blob 객체 생성
bucket = client.get_bucket(bucket_name)
blob = bucket.blob(blob_name)
# 파일 업로드
blob.upload_from_filename(temp_file.name)
🔥에러
권한설정을 잘했는가?
pandas_gbq.exceptions.GenericGBQException: Reason: 403 POST https://bigquery............... /
Access Denied: Project my-project-72981: User does not have bigquery.jobs.create permission in project my-project-72981.
함수가 정상적으로 등록 되었지만 스케쥴러를 통해 함수를 실행하면 자꾸 에러가 뜬다..
확인해보니 'my-project-72981' 해당 프로젝트에 bigquery.jobs.create 권한 이 없다는 거였다. 뭐지?? 분명히 빅쿼리에 관련된 프로젝트 key도 받았고 Cloud Functions에 등록했는데 왜 안되는걸까... 해매던중
공식문서를 찾아보니 권한을 따로 부여해야했다.

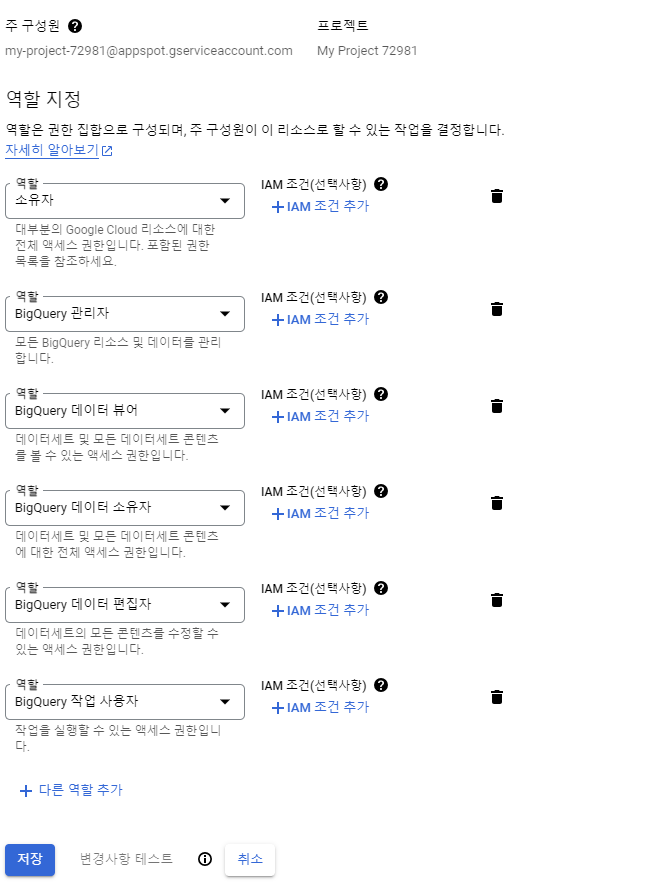
IAM 및 관리자 으로 들어가면 해당 프로젝트의 구성원들의 역할을 설정할 수 있는데, bigquery.jobs.create 에 대한 권한이 없었던것.
공식문서대로 데이터 편집자, 데이터 뷰어, 작업 사용자 역할을 부여하면 정상적으로 작동된다!
('소유자'로 해놓으면 다 되는줄 알았는데 권한 에러가 뜨는거 보면 몇개는 설정해줘야 하나보다..!?)