
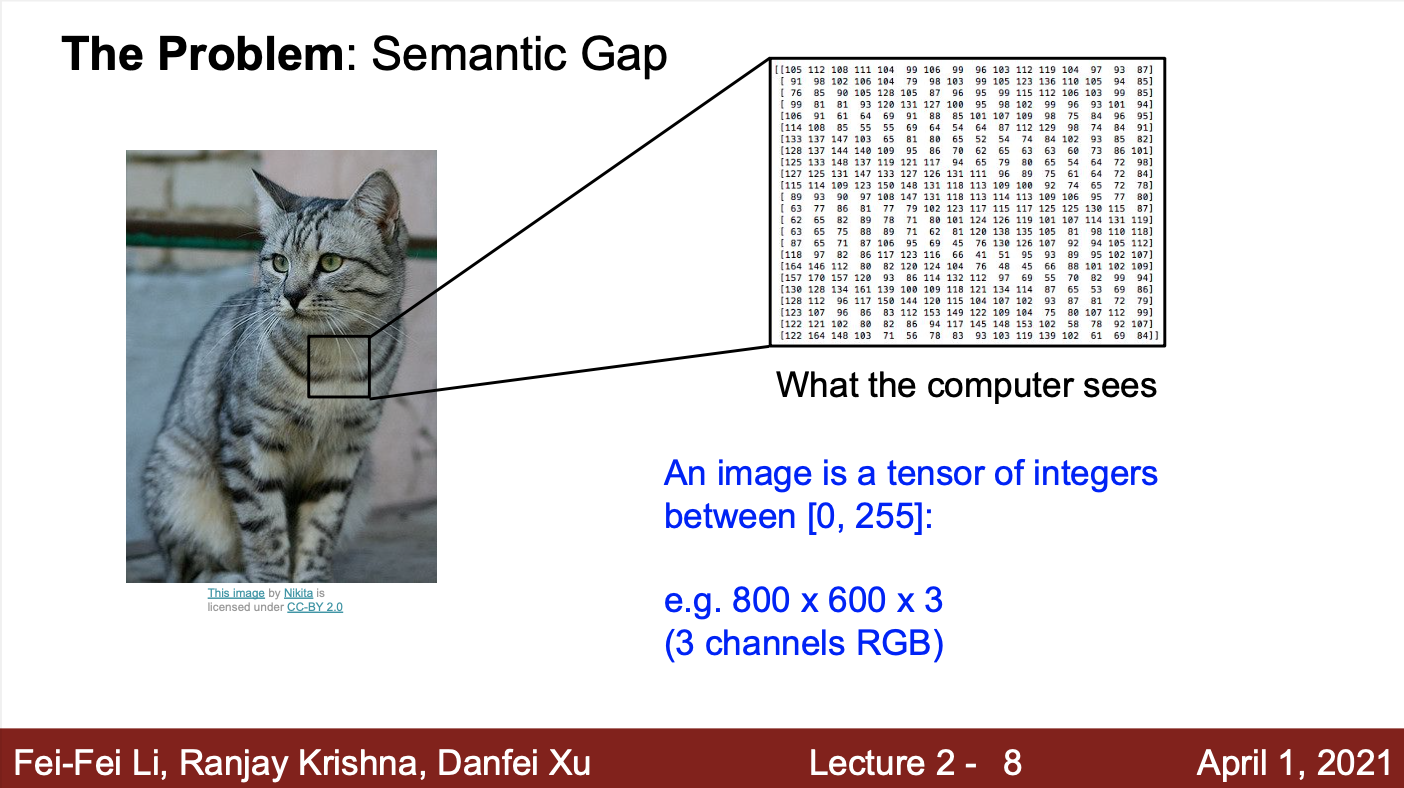
- 컴퓨터는 어떻게 이미지를 인식하는가? Semantic Gap이란 무엇인가?
- 사람은 이미지를 보고, 해당 물체가 고양이라는 것을 쉽게 인식
- 기계는 해당 이미지를 pixel로 이루어진 데이터로 봄
- 따라서, 기계는 해당 이미지가 고양이인지 쉽게 인식할 수 없음
- 이렇게 사람과 기계 사이의 이미지 인식 차이를 Semantic Gap이라고 부름
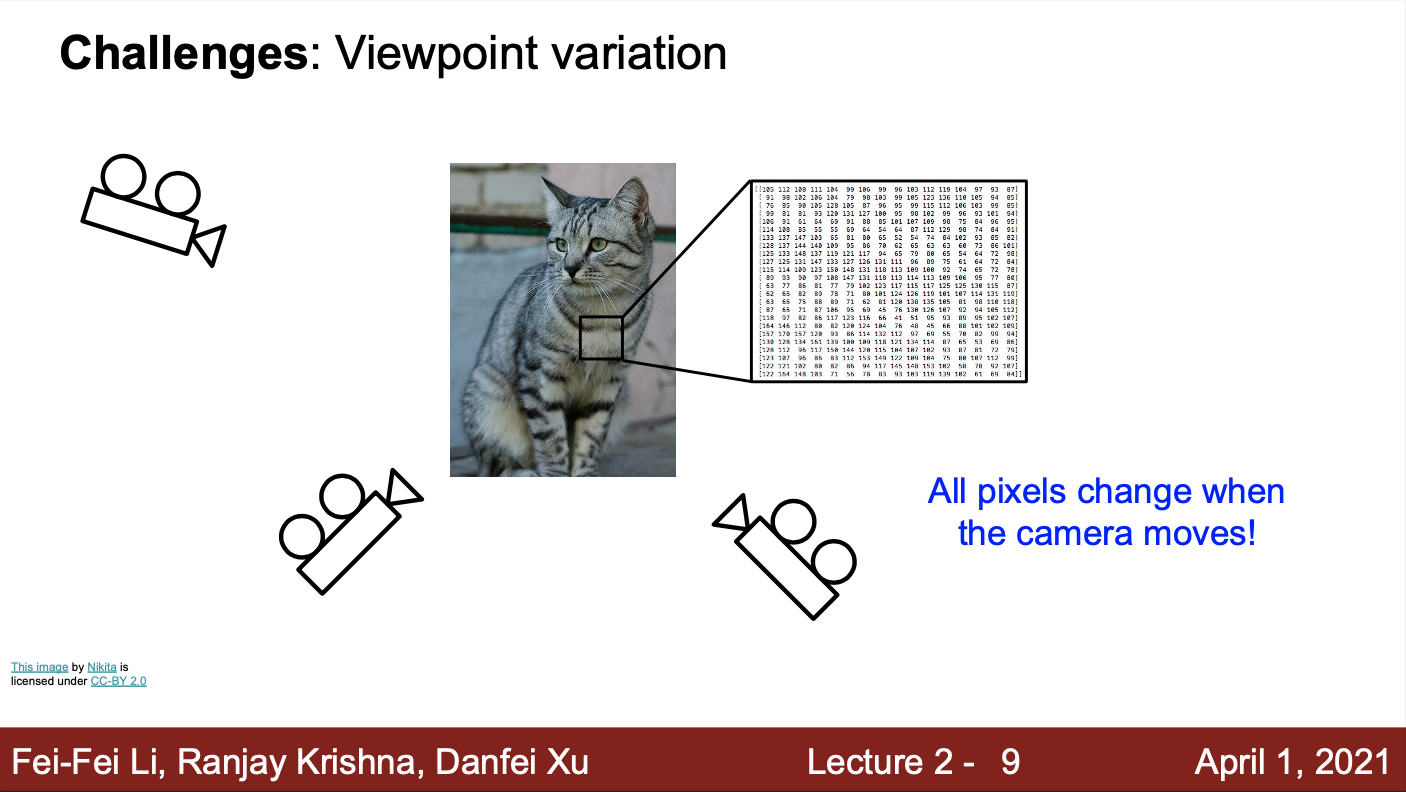
- 기계가 이미지를 인식하는 것이 어려운 이유는 무엇인가?
- 카메라의 위치를 조금만 옮겨도, 픽셀 값이 달라질 수 있음
- 이러한 문제는, 바라보는 방향 뿐만 아니라, 조명, 객체의 자세, 객체의 일부가 가려짐, 배경과 객체가 유사함, 하나의 클래스(고양이)에서 다양성이 존재하는 경우에도 발생
- 이러한 문제에 강건한 알고리즘을 만드는 것이 중요함 (다양한 고양이의 모습을 ‘고양이’라는 하나의 클래스로 전부 소화할 수 있도록 만드는 것이 중요)
- 중요한 점은, 고양이만 분류하는 것이 아니라, 이 외에 다른 여러가지 객체에 대해서도 잘 분류할 수 있어야 함 (기계도 인간처럼 분류를 잘 하도록 만들어야한다)
- 이는 굉장히 어려운 일이지만, 일부 제한된 상황을 가정한다면 가능한 일
- 카메라의 위치를 조금만 옮겨도, 픽셀 값이 달라질 수 있음

- 앞서 언급한 문제들을 해결하기 위한 방법?
- Image Clssifier를 만든다고 가정한다면, 어떤 코드를 작성해야 좋을까?
- 객체를 분류하기 위한, 직관적이고 명시적인 알고리즘은 존재하지 않을 것
- 고양이와 강아지를 분류하는 직관적인 알고리즘???

- 컴퓨터가 이미지를 인식하기 위한 알고리즘들
- 이미지의 코너와 엣지를 이용하여 이미지 속 객체를 인식하는 방법
- 이미지 속에서 엣지를 계산
- 코너와 엣지의 위치를 통해서 각 카테고리를 분류
- 즉, 명시적인 규칙 집합을 이용하는 방법
- 하지만, 이 방법은 잘 동작하지 않음
- 강건한 (Rubust) 방법이 아님
- 만약, 고양이가 아닌 새로운 객체(강아지, 트럭 등)를 인식해야한다면, 처음부터 새롭게 만들어야 함 (확장성이 없음)
- 데이터 중심 접근 방법
- 다양한 객체들에 유연하게 적용 가능한 확장성 알고리즘을 만들기 위해서 시도한 방법
- 기존처럼, 각 객체를 분류하기 위한 규칙을 만드는 방법이 아닌, 각 객체를 표현하는 많은 데이터를 수집하여 이용하는 방법
- 이렇게 수집한 데이터셋을 이용하여 Machine learning을 학습시킴
- Machine learning 알고리즘은 어떤 식으로든 데이터를 요약해서 다양한 객체를 인식할 수 있는 모델을 만듦
-
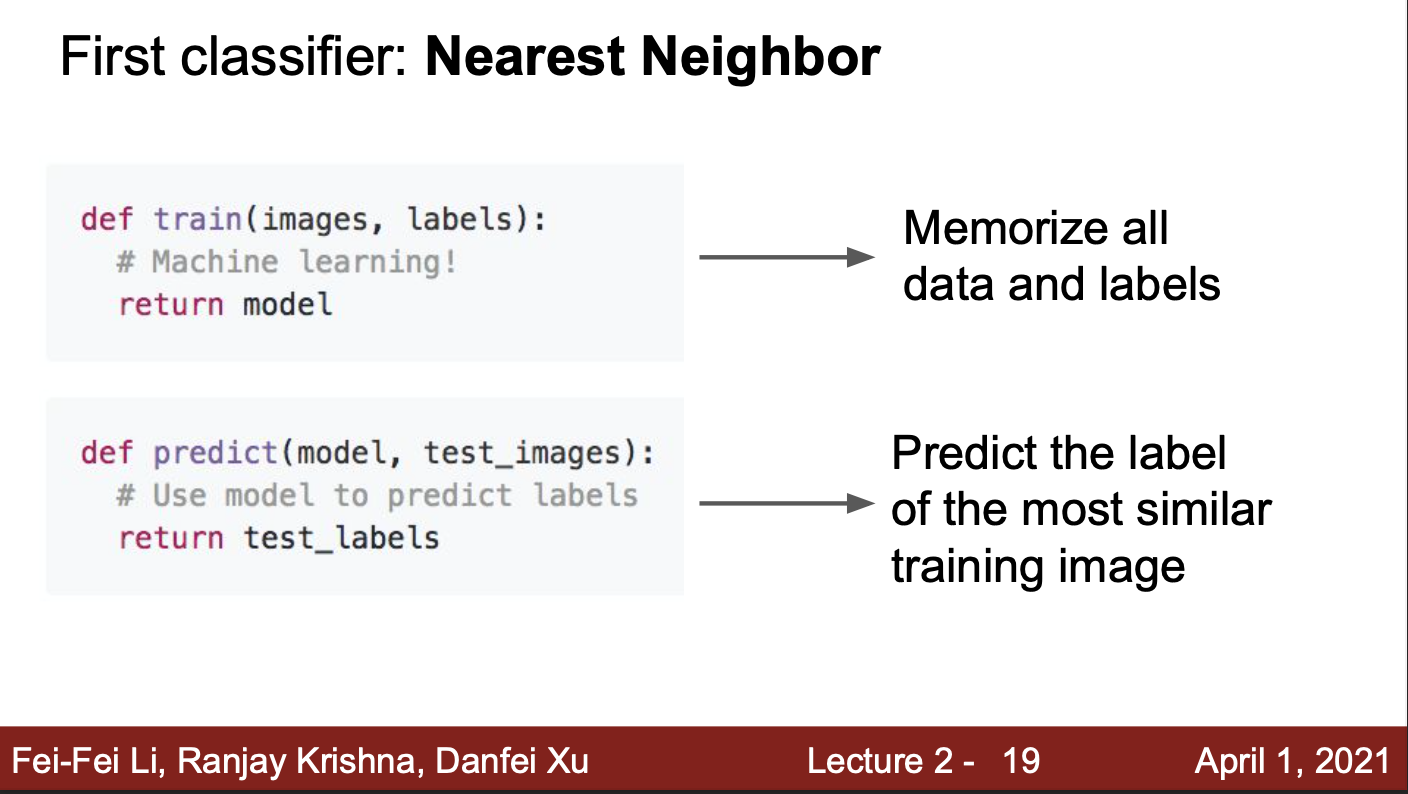
Machine learning을 통해 입력 이미지를 분류하기 위해서는, 2개의 함수가 필요
- Train 함수 → 입력은 이미지와 레이블, 출력은 모델
- 이는 입력 이미지와 레이블을 이용하여, 모델을 학습시키는 함수
- Predict 함수 → 입력은 모델과 테스트 이미지, 출력은 이미지의 예측값
- 이는 학습된 모델을 이용하여, 테스트 이미지를 분류하는 함수
- Train 함수 → 입력은 이미지와 레이블, 출력은 모델
-
데이터 중심 접근 방법 중 하나인 KNN 알고리즘
- Nearest neighbor는 단순한 classifier
- train 과정에서는, 단순히 모든 학습 데이터를 기억함
- 이후 predict 과정에서, 새로운 이미지가 들어오면, 기존의 학습 데이터와 비교해서 가장 유사한 이미지로 레이블을 예측

- Nearest neighbor 예제
- 50,000장의 학습 데이터가 10개의 카테고리로 균일하게 분포
- 10,000장의 테스트 데이터셋이 존재
- KNN 알고리즘을 이용하여 train dataset을 학습한 후, test dataset에 이미지를 이용하여 predict를 진행하게 되면, 오른쪽 이미지처럼 train dataset에 존재하는 이미지들 중 test image와 비슷한 이미지를 뽑아냄
- 그러나 항상 맞는 동일한 레이블을 추출하는 것은 아님
- 즉, NN 알고리즘을 적용하면 training set에서 가장 가까운 샘플을 찾음
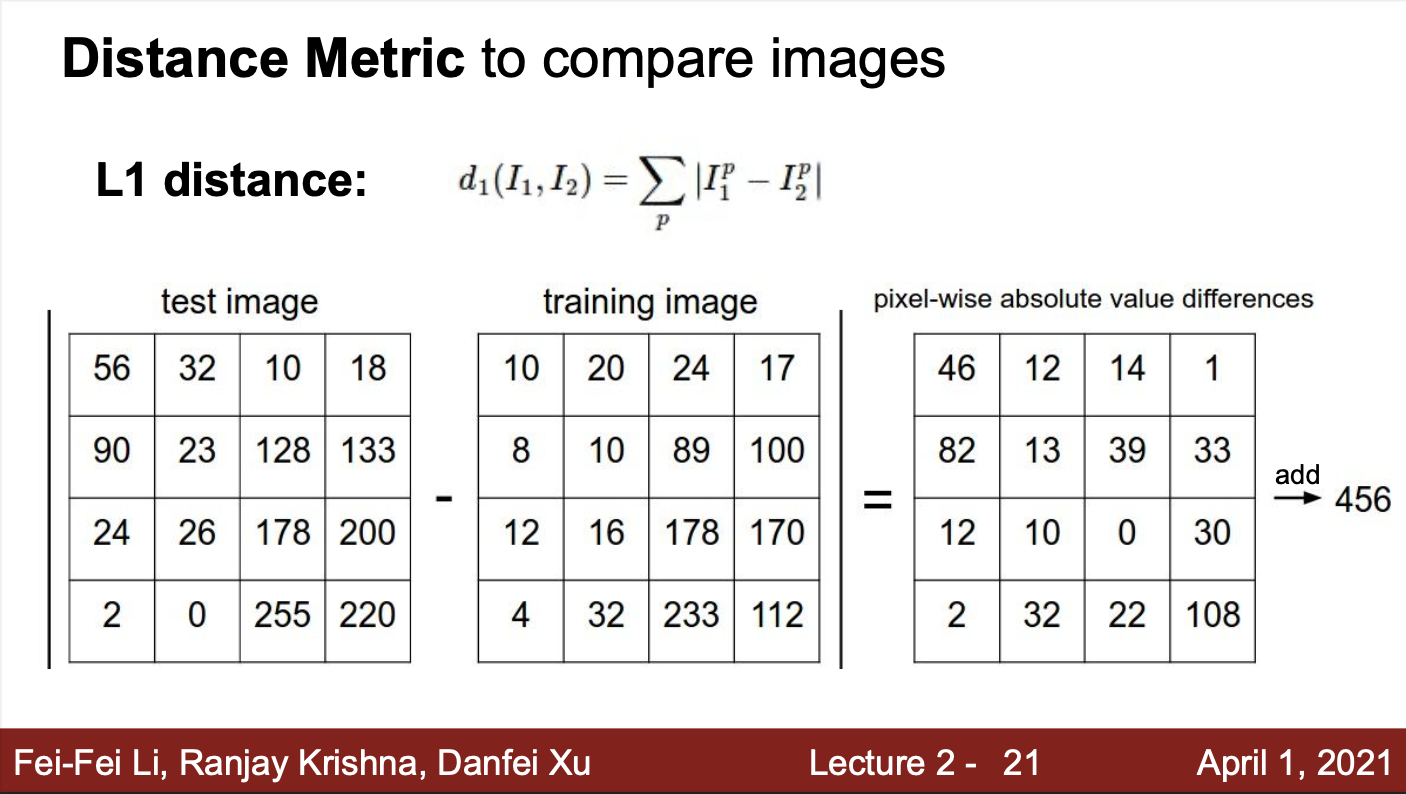
- 그렇다면, 테스트 이미지와 학습 이미지들을 비교할 때, 어떻게 유사함을 판단하는가?
- 유사성을 판단하기 위한 여러가지 방법들이 있음
- 해당 NN 알고리즘 예제에서는 L1 distance를 이용하여 유사성을 판단함
- 각 픽셀들을 서로 뺀 후 절댓값을 취하는 방법

- KNN 알고리즘 코드
- NN 알고리즘에서, train은 단순히 학습 데이터셋을 기억하는 과정이기 때문에, train 함수가 굉장히 단순하게 구현되어 있음
- 이후 predict 과정에서는, test 이미지와 학습된 이미지들 사이의 유사성을 판단하는데, 이때 L1 distance를 이용하였기 때문에, predict 함수에서는 이미지 간의 L1 distance를 측정
- 이후 L1 distance가 가장 작은 값을 계산하는 이미지가 가장 유사한 이미지라고 판단하여 최종 예측값으로 출력
- 그렇다면, 총 N개의 학습 이미지가 있을 때, train/test 함수의 속도는 얼마일까?
- 코드의 시간복잡도를 나타내는 표기 방법인 Big-O 표기법을 알야아 함
- 시간 복잡도란, 입력값의 변화에 따라 연산을 실행할 때, 연산 횟수에 비해 시간이 얼마나 걸리는가?를 나타내는 척도
- 시간 복잡도의 표기법 중 하나가 Big-O 표기법
- Big-O 표기법은 최학의 경우를 고려하는 방법으로, 프로그램이 실행되는 과정에서 소요되는 최악의 시간을 고려하는 표기 방법
- train 단계에서는 단순히 이미지를 입력받고, 저장하는 과정이기 때문에 데이터 자체가 늘어난다고 해서, 연산 횟수가 많아지는 것은 아님
- 따라서, O(1),,, 즉, 상수 시간에 비례
- test 단계에서는 하나의 test 이미지를 모든 학습 이미지들과 비교하여 L1 distance를 측정해야 함
- 따라서, 총 N번의 L1 distance 연산을 수행 O(N)
- 코드의 시간복잡도를 나타내는 표기 방법인 Big-O 표기법을 알야아 함
- test time이 train time보다 더 걸린다는 것은 잘못된 것
- 왜냐하면, 우리는 학습에 소요되는 시간이 오래 걸리는 것은 괜찮지만,
- 해당 모델을 실제로 사용할 때, 시간이 많이 소요되는 것은 좋지 않음
- 단순한 예시로, 스마트폰 어플리케이션의 동작이 느린 것은 좋지 않음
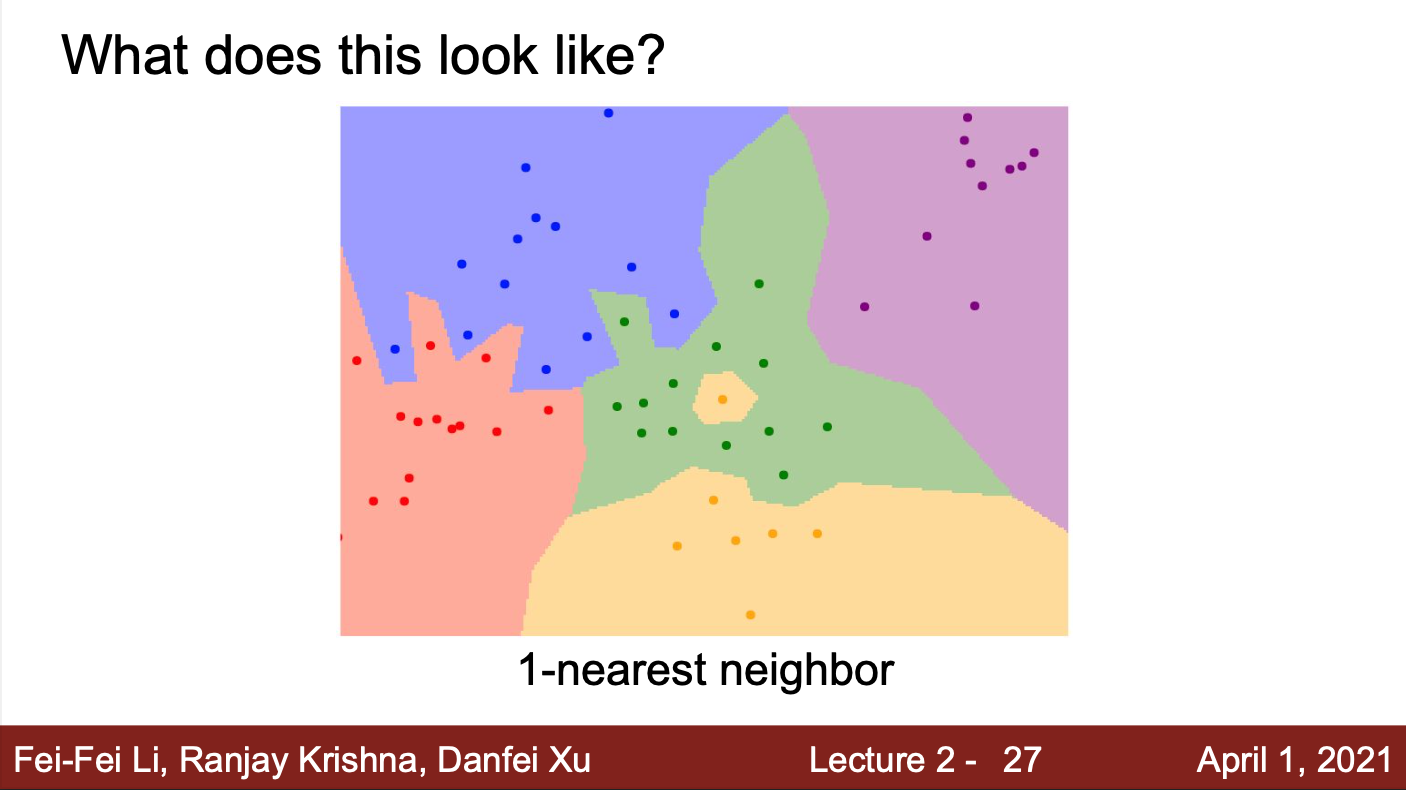
- KNN 알고리즘의 동작 방식
- 각 점은 학습 데이터이고, 점의 색은 클래스 레이블(카테고리)
- 모든 좌표들에 대해서, 각 좌표가 어떤 학습 데이터와 가까운지 계산(L1 distance)
- NN 알고리즘은 공간을 나눠서 각 레이블로 분류
- 이 알고리즘의 문제는
- 초록색 영역 안에 노란 점이 존재한다는 것
- 가장 가까운 이웃만 고려하기 때문에, 이런 현상이 발생함
- 초록색이 파란색 영역을 침범하는 것도 문제
- 즉, 노이즈에 영향을 많이 받는 알고리즘
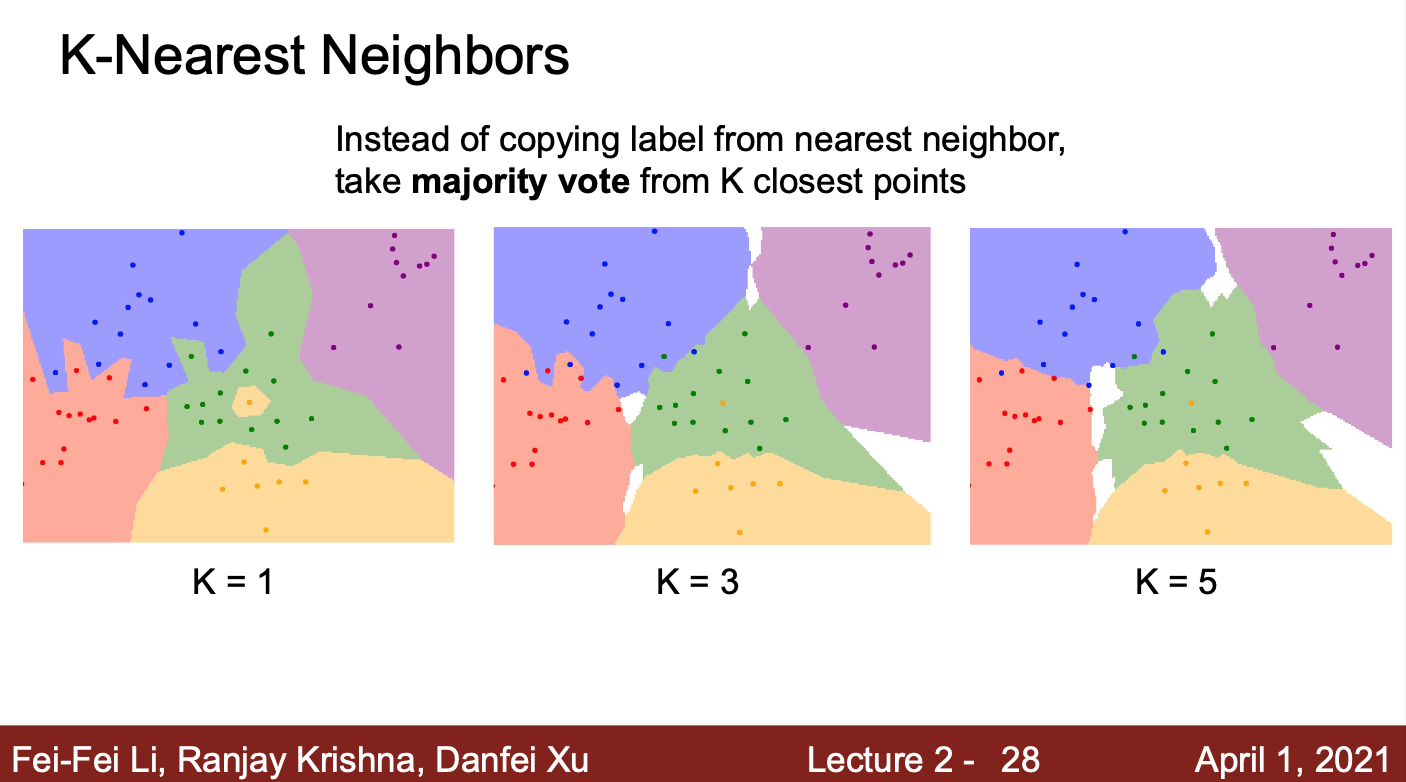
- 이러한 NN 알고리즘의 문제를 해결하기 위해서, KNN 알고리즘이 탄생
- KNN 알고리즘은, 가장 가까운 이웃을 하나만 보는 것이 아니라, K개의 이웃을 이용하여 투표를 통해 최종 결과를 예측을 하는 방식
- K 값이 증가할수록, 앞서 NN 알고리즘에서 발생한 문제들이 해결되고, 각 영역들의 경계가 부드러워지는 것을 확인할 수 있음
- 즉, KNN 알고리즘은 NN 알고리즘보다 노이즈에 강건한 알고리즘이라고 할 수 있음
- 따라서, KNN 알고리즘을 사용할때는 1보다 큰 K 값을 선정해야함

- 실제 KNN 알고리즘을 적용하여 이미지 분류를 한다면, K가 1일때보다, 더 좋은 결과를 얻을 수 있을 것

- 이미지 간의 차이점, 유사성을 어떻게 측정하고 비교할 것 인지?
- 기존에는 L1 distance를 이용했음
- 이는 픽셀 간 차이 절대값의 합
- feature들이 개별적인 의미를 가지고 있다면, L1 distance가 잘 어울림
- 다른 방법으로는 L2 distance가 존재
- 이는 제곱 합의 제곱근을 거리로 이용하는 방법
- feature 간의 실질적인 의미를 잘 모르는 경우에는, L2 distance가 잘 어울림
- 기존에는 L1 distance를 이용했음
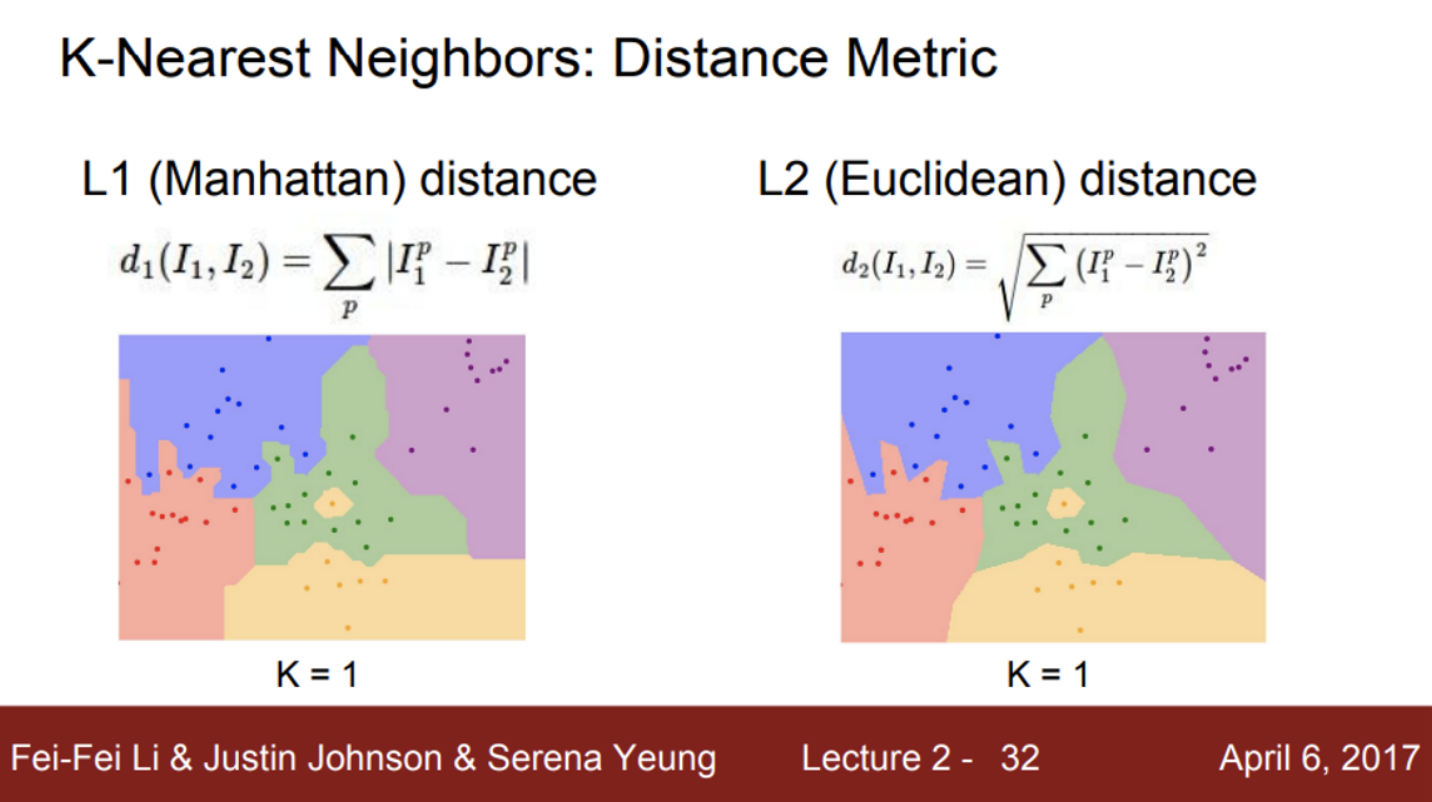
- 어떤 거리 척도를 사용하느냐에 따라, 결정 경계의 차이가 있음을 확인할 수 있음
- L1 distance의 경우, 좌표 시스템에 영향을 받기 때문에, 결정 경계가 좌표축에 영향을 받는 것을 확인할 수 있음
- L2 distance의 경우, 좌표축의 영향을 받지 않고 결정 경계를 만들기 때문에, 조금 더 자연스러움

- KNN을 사용하려면, 반드시 선택해야하는 항목들이 존재
- K, 거리 척도(L1, L2) 등을 어떻게 선택하느냐에 따라서, 예측값이 바뀔 수 있음
- 이 값들을 어떻게 선정해야하는지??
- 실제로 이런 값들을 하이퍼 파라미터라고 함
- 일반적으로 파라미터(혹은 모델 파라미터)라고 부르는 값들은, 해당 모델의 학습 단계에서 업데이트가 되는 값들을 의미 (모델의 가중치)
- 하이퍼 파라미터는 모델의 학습을 통해 업데이트가 되는 값이 아닌, 학습 전에 우리가 선택을 해야하는 값들 (K, 거리척도, learning rate 등)
- 그렇다면, 하이퍼 파라미터 값은 어떻게 정해야 하는가?
- 가장 간단한 방법은, 다양한 하이퍼 파라미터 값을 시도해보고, 가장 좋은 값을 찾는 방법
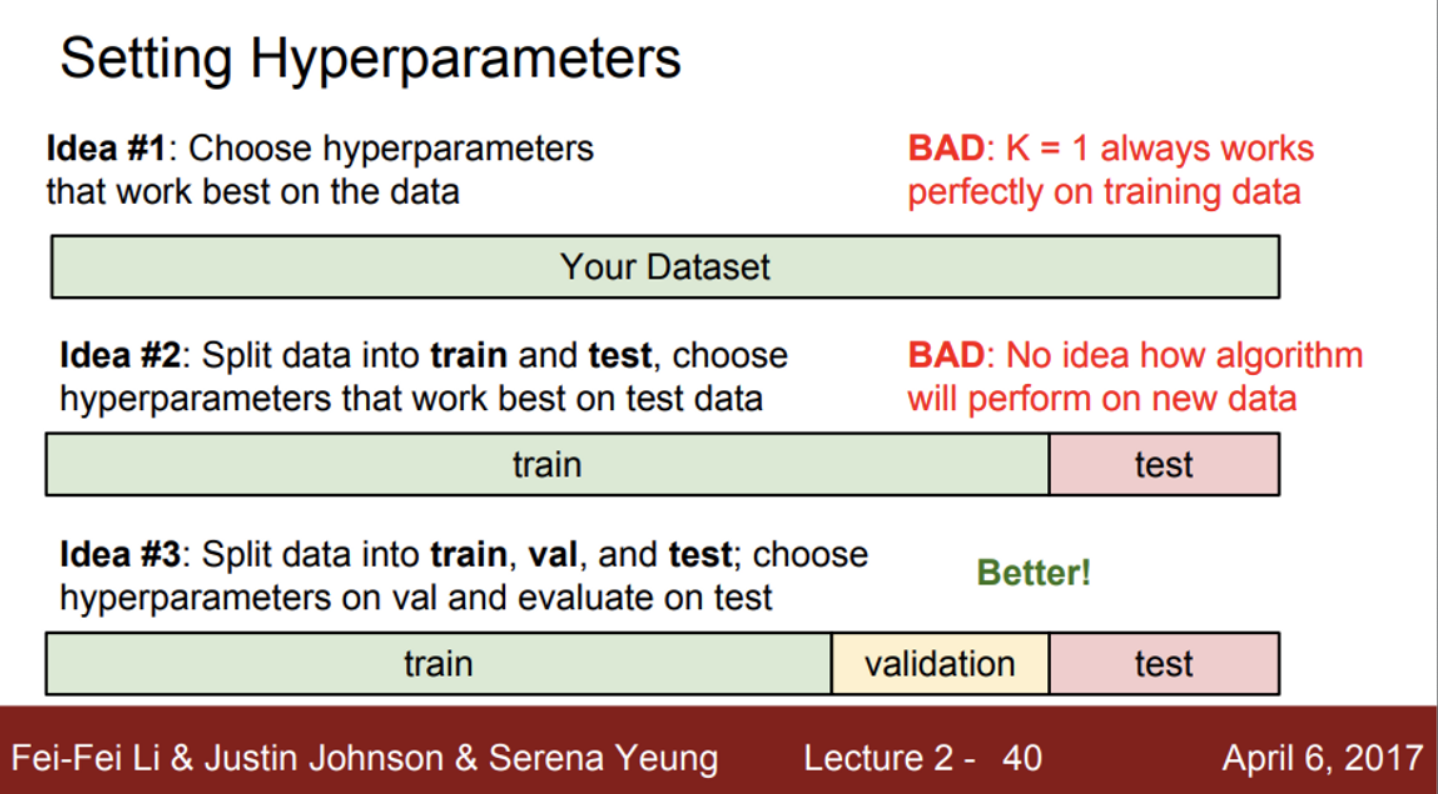
- 그렇다면, 어떤 하이퍼 파라미터를 선택해야 하는가?
- 먼저, 학습 데이터의 정확도와 성능을 최대화하는 하이퍼 파라미터를 선택하는 방법
- 절대로 해서는 안되는 방법
- 이렇게 학습을 하면, 처음보는 새로운 데이터에 대해서는 좋은 성능을 보일 수 없음
- 학습 데이터를 얼마나 잘 맞추는지가 중요한 것이 아니라, 학습된 모델이 새로운 데이터를 얼마나 잘 예측하느냐가 중요
- 다음으로, 전체 데이터셋을 학습 데이터와 테스트 데이터로 나눠서 사용하는 방법
- 학습 데이터로 다양한 하이퍼 파라미터 값들을 학습시키고, 테스트 데이터를 이용해 확인한 후, 하이퍼 파라미터를 선택하는 방법
- 즉, 모델 학습은 학습 데이터로 진행하고, 그 중에서 테스트 데이터를 가장 잘 예측하는 모델을 선택하는 방법
- 이 또한, 나쁜 방법,,, 단순히 테스트 데이터만 잘 푸는 하이퍼 파라미터를 선택한 것일 수도 있음
- 학습 데이터로 다양한 하이퍼 파라미터 값들을 학습시키고, 테스트 데이터를 이용해 확인한 후, 하이퍼 파라미터를 선택하는 방법
- 가장 일반적인 방법은, 전체 데이터셋을 train, validation, test 셋으로 나누는 방법
- training set을 이용하여 다양한 하이퍼 파라미터를 학습
- 이후 validation set으로 모델을 검증
- 이때, validation set에서 가장 성능이 좋았던 하이퍼 파라미터를 선택
- 최종적으로 선정된 모델의 성능을 test set을 이용하여 측정
- 이 수치가 최종 모델의 성능 수치
- 먼저, 학습 데이터의 정확도와 성능을 최대화하는 하이퍼 파라미터를 선택하는 방법
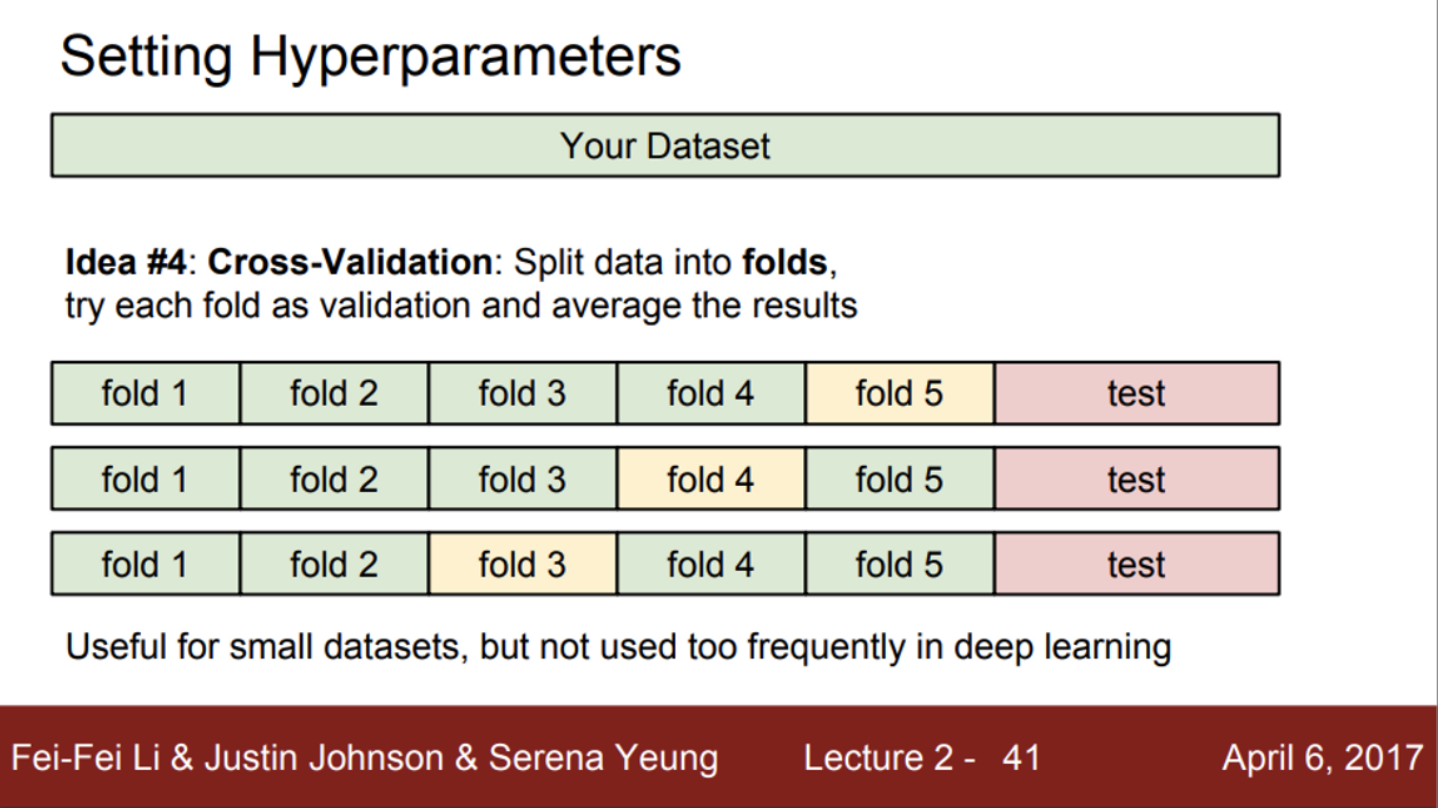
- 또 다른 방법은, 크로스 벨리데이션(교차 검증)
- 이 방법은 데이터셋이 작을 때, 많이 사용
- 먼저, 테스트 데이터셋을 정함 (마지막에만 사용)
- training set을 여러 부분으로 나눠줌
- 이후, validation set을 그림과 같이 번갈아가면서 지정 (K-fold 교차 검증)
- training set 학습 → validation set 검증 → validation set 재 지정 → training set 학습 → validation set 검증 → validation set 재 지정 → …
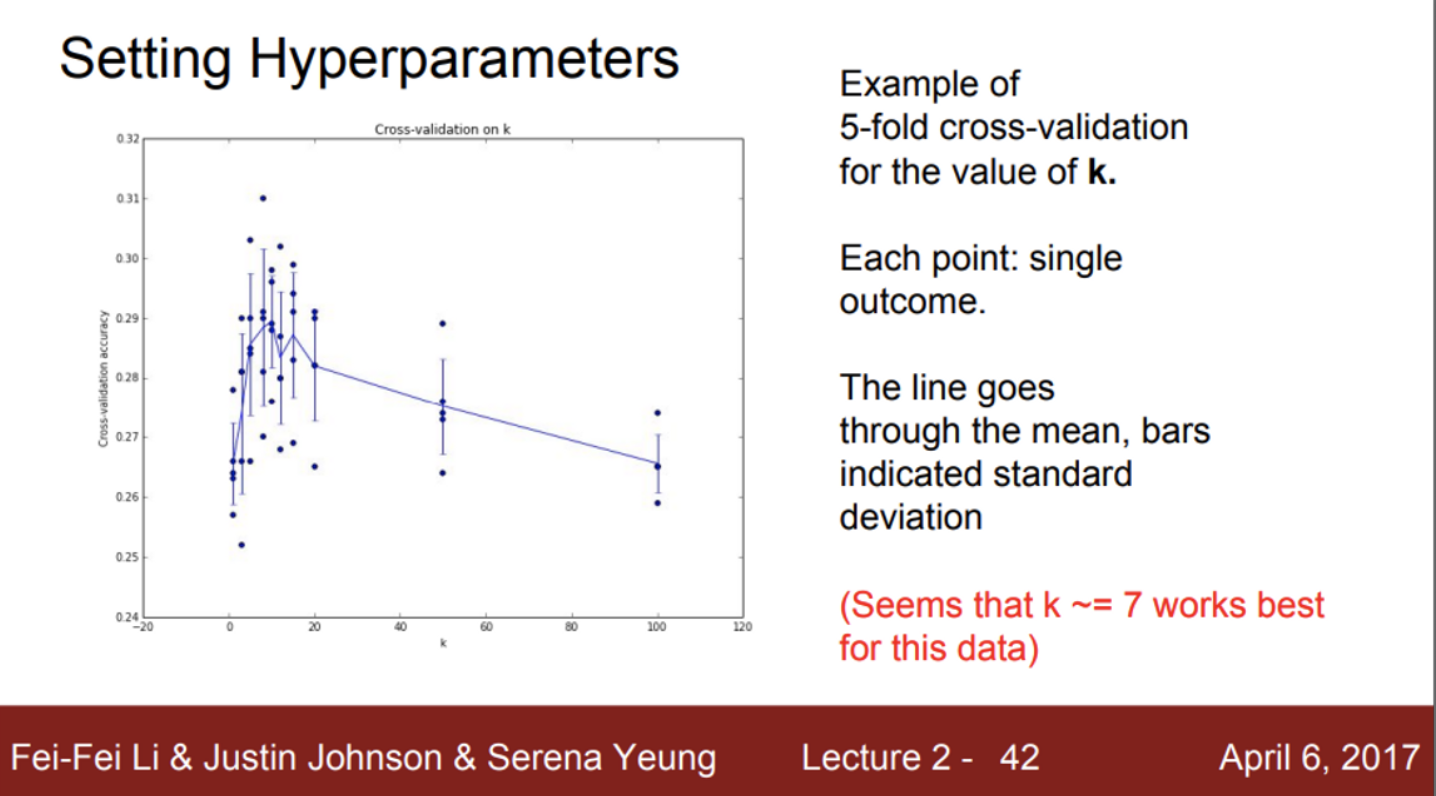

- 실제 이미지 분류에서는 KNN classifier를 잘 사용하지 않음
- 첫 번째 이유는, KNN이 predict 과정에서 느리다는 것
- 다음으로, L1, L2 distance가 이미지 간의 거리(유사도)를 측정하기에는 적절하지 않다는 것
- 해당 이미지들은, 일부러 같은 L2 distance를 갖도록 만든 이미지들인데, 중요한 점은 실제로 이미지들 간의 차이를 L2 distance로 측정하는 것은 좋지 않다는 예시

- 또 다른 문제는, 차원의 저주
- KNN 알고리즘은 데이터셋을 이용하여 공간을 나누는 알고리즘
- KNN이 잘 동작하려면, 그만큼 충분한 데이터셋이 필요함
- 데이터셋이 충분하지 않다면, 가장 가까운 이웃으로 판단되는 데이터가 실제로는 엄청 거리가 먼 데이터일 수도 있음
- 그렇다면, 이미지를 제대로 분류할 수 없음
- 따라서, 학습 데이터가 많아야 함
- 만약 학습 데이터의 차원이 높다면? (즉, 어떤 정수 값이 아닌, 3차원의 컬러 이미지라면?)
- 여기서 말하는 차원은, 간단하게 변수의 갯수라고 생각하면 쉬움
- 차원이 높을 수록, 학습에 필요한 데이터셋이 기하급수적으로 많아짐
- 이렇게 많은 양의 학습 데이터를 모으는 것은 불가능 (비용도 많이 들고, 시간도 오래 걸림)


- Linear classification에 대해서 알아보자
- Linear classification은 아주 간단한 알고리즘
- NN과 CNN 기반의 알고리즘
- Neural Network를 레고 블럭에 비유
- 레고 블럭을 쌓아서 만드는 것 처럼, CNN을 구성할 때, 여러가지 layer를 쌓아서 만듦
- 이후에 여러가지 layer를 살펴보겠지만, 가장 기본이 되는 딥러닝 알고리즘이 Linear classifier

- Image Captioning
- 이미지를 인식하기 위해서, CNN이라는 것을 사용
- 그 이후에 자연어를 인식하기 위해서 RNN을 사용
- 즉, Image Captioning은 CNN과 RNN을 블럭처럼 붙혀서 한번에 학습시키는 방법
- 여기서 말하고자 하는 것은, Neural Network가 레고 블럭처럼 여러가지를 결합시켜서 사용이 가능함
- 그리고, Linear classifier가 기본 레고 블럭 중 하나

- 앞서 CIFAR-10 데이터셋을 이용하여 KNN 알고리즘을 학습했음
- Linear classification에서는 KNN과는 다른 접근 방법을 이용
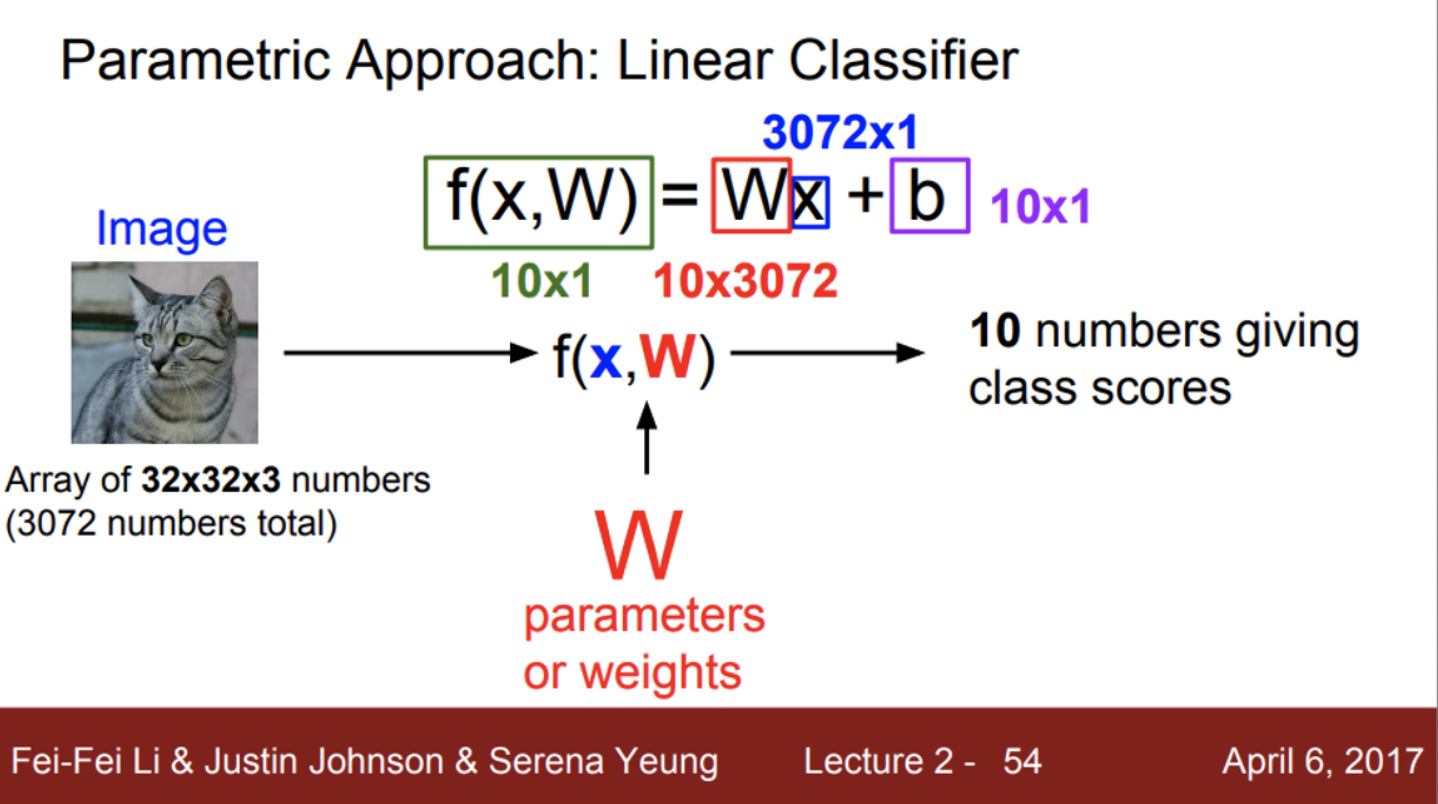
- 밑시딥에서 본 인공 신경망을 생각하면서 보면 좋음
- 입력 이미지 X가 주어짐
- 이 이미지를 input으로 받는 함수 f(x)를 만들 것인데,
- 이때 사용하는 가중치는 W로 표기
- f(x) 함수를 통해 출력된 output은 10개의 카테고리에 대한 각각의 스코어 (고양이, 개, 사슴, 개구리 등등)
- 만약, 고양이 스코어가 높다는 것은, 입력 이미지가 고양이일 확률이 크다는 것을 의미
- 앞서 살펴본 KNN과의 차이점은, KNN은 파라미터가 존재하지 않음
- 즉, KNN은 모든 학습 데이터를 기억하고, 거리 척도를 이용하여 input image와 유사한 학습 데이터를 출력하고, 최종 결과를 예측
- 그러나, Linear classifier는, 모델 학습 과정에서 training data의 정보를 요약하고, 요약된 정보를 파라미터 W에 모아둠
- 이런 과정을 거친다면, predict 단계에서는 더 이상 training set이 필요하지 않음
- 즉, 딥러닝은 함수 F의 구조를 잘 설계하는 일
- 가중치 W와 데이터 X를 어떻게 조합하느냐 (함수를 어떻게 구성하느냐)는 여러가지 방법이 존재하겠지만, 가장 간단하게 생각할 수 있는 방법은 W와 X를 곱하는 것
- 이것이 바로 Linear classification
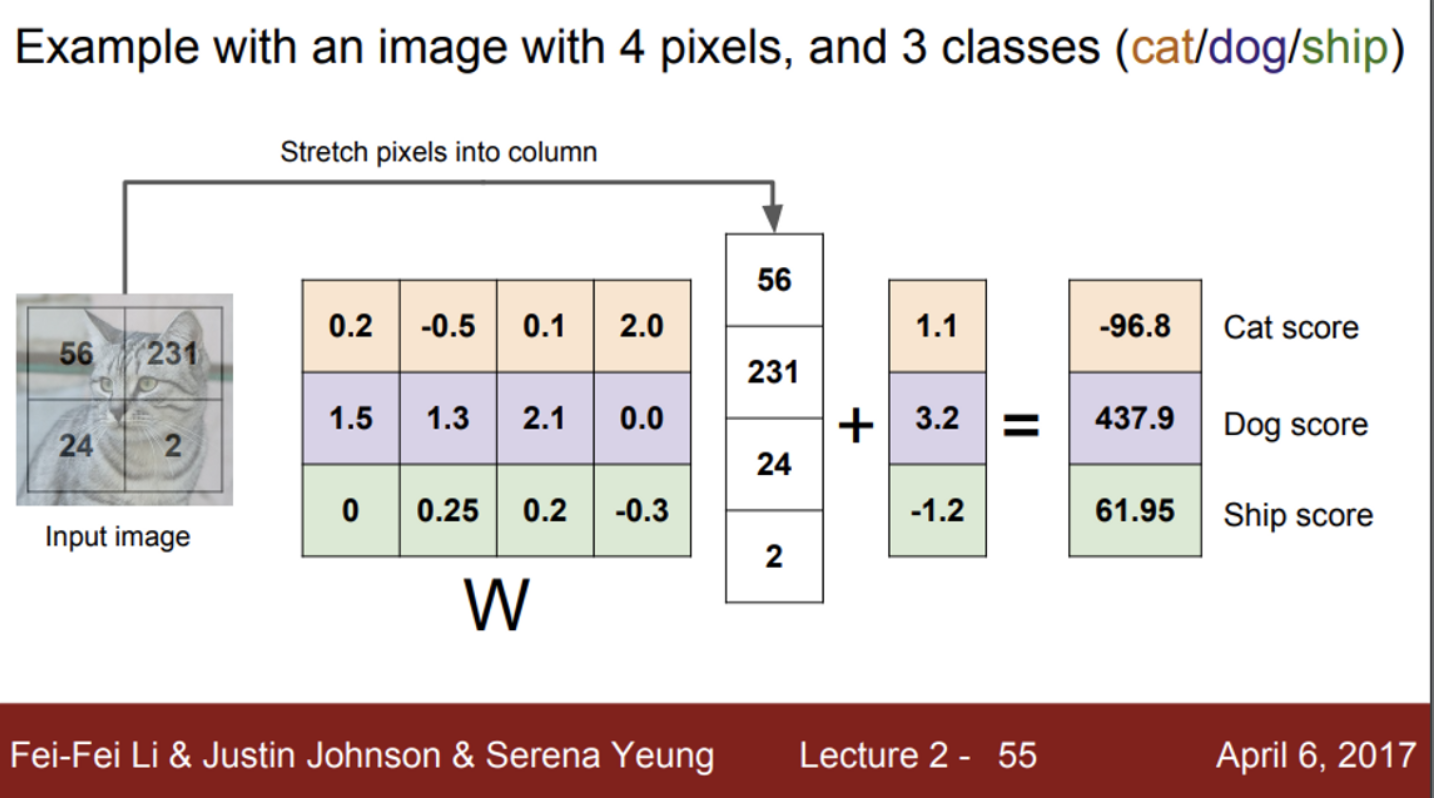
- 계산 과정은 행렬곱 연산
- 최종적으로 계산 후에, 10개의 레이블에 대한 스코어를 출력
- 이 스코어는, 해당 이미지가 각 레이블에 해당할 점수(혹은 확률)이 얼마인지를 확인하는 척도

- 그렇다면, 가중치 W가 의미하는 것은 무엇인가?
- 가중치 행렬 W를 각 행별로 시각화해보면, Linear classifier가 이미지를 인식하기 위해서 어떤 것들을 중점적으로 보는지 대략적으로 확인할 수 있음
- 즉, 각 클래스에 속한 이미지들이 갖는 공통된 특징을 추출하고, 이를 바탕으로 이미지를 분류한다는 것을 예측할 수 있음
- 단, Linear classifier의 문제 중 하나는, 각 클래스에 대해서 단 하나의 템플릿만 학습한다는 것
- 같은 클래스여도, 이미지에 따라서 다양한 특징이 존재할 수 있는데, 이를 평균화시키기 때문에, 이미지를 분류하기 위한 하나의 탬플릿만 존재
- 이 문제는 말 이미지에서 확인할 수 있음
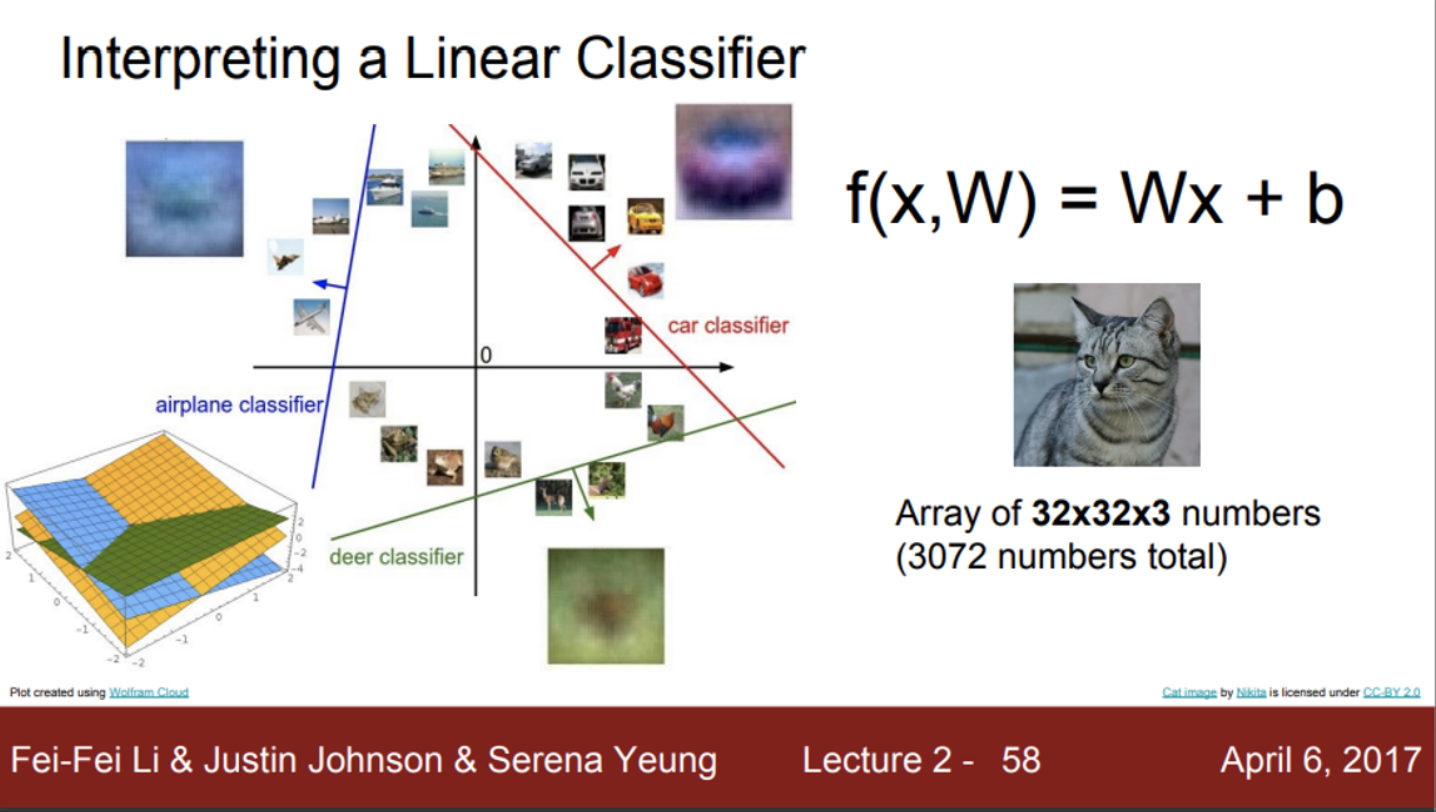
- Linear classifier의 또 다른 관점으로 해석
- 이미지를 고차원의 공간에서 한 점으로 보는 방법
- 이미지를 고차원 공간의 한 점으로 본다면,
- Linear classifier는 각 클래스를 구분시켜주는 선형 결정 경계를 그어주는 역할
- 즉, 그림에서 파란색 선을 기준으로, 비행기 이미지와 아닌 이미지를 구분

- 이렇게 고차원 공간의 하나의 점 관점에서 해석할 때, Linear classification이 갖는 문제를 확인할 수 있음
- 위의 3가지 예시를 하나의 직선으로 구분할 수 없음 (밑시딥에서 XOR 구분 예시)
- 즉, Linear classifier 모델이 해결할 수 없는 문제들이 있다,,, → 이 문제를 해결하기 위해 고안된 방법들은 차차 다룰거임

코딩하는 물리학도