[Multimodal RAG] VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents (2024)
Multimodal RAG
목록 보기
2/3
VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents (arxiv preprint 2024)
- paper : https://arxiv.org/pdf/2410.10594
- MiniCPM 개발한 openbmb가 개발
- huggingface : https://huggingface.co/openbmb/VisRAG-Ret
- github : https://github.com/OpenBMB/VisRAG/tree/master?tab=readme-ov-file
✏️ Abstract
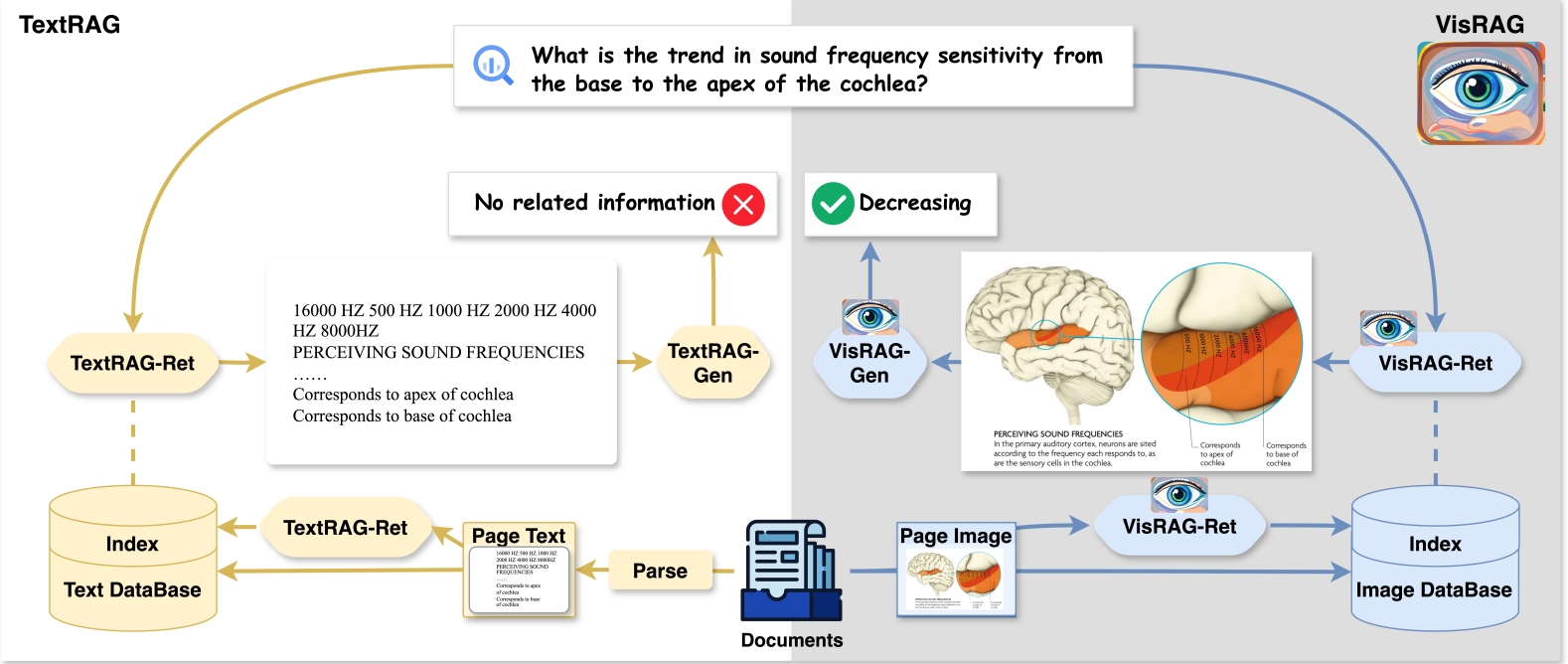
document에서 text를 얻어 parsing하는 것이 아니라, VLM을 활용하여 문서를 이미지로 해서 임베딩
text-based RAG 대비 VisRAG는 원본 문서 내의 정보 유지, 최대 활용 -> parsing 과정에서 발생하는 정보 손실 제거
진행한 실험에서 전통 RAG 대비 25-39%의 성능 향상
강력한 일반화 성능
✏️ Methodology
- (1) VisRAG-Ret : Vision-based Retriever
document embedding model built on MiniCPM-V2.0 (VLM (SigLIP(vision encoder) + MiniCPM-2B(language model)))- (2) VisRAG-Gen : Generator
In the paper, We use MiniCPM-V 2.0, MiniCPM-V 2.6 and GPT-4o as the generators.
Actually, you can use any VLMs you like!
1️⃣ Retrieval - VisRAG-Ret
- document embedding model로 쿼리와 문서 이미지 임베딩 -> 검색 (similar score 계산)
- VLM(MiniCPM-V 2.0)을 사용하여 쿼리와 문서를 encode
- [쿼리 -> text], [문서 -> 이미지]로 별도로 인코딩
- VLM의 마지막 레이어의 hidden states를 position-weighted mean pooling을 적용하여 embedding을 얻음
- similarity score : 쿼리와 페이지 임베딩의 cosine similarity 계산
2️⃣ Generation - VisRAG-Gen
- VLM을 사용하여 user query와 검색된 페이지를 기반으로 답변 생성
- multiple 검색 페이지들을 다룰 수 있도록 하는 메커니즘 제안
- Page Concatenation
- 문서의 모든 페이지를 하나의 이미지로 concatenation
- 단일 이미지만을 처리할 수 있는 VLM을 위함
- 이 논문에서는 horizontal concatenation
- Weighted Selection
- VLM이 유사도 top-k 페이지에 대한 답변을 모두 생성하게 한 뒤, 가장 큰 confidence 값을 가지는 final 답변을 선택하는 방식
- final confidence : weighted generation probability of the answer
- Multiple images를 처리 가능한 VLM 사용
- MiniCPM-V 2.6, Qwen2-VL과 같은 최신 VLM 모델
