[Multimodal RAG] ColPali: Efficient Document Retrieval with Vision Language Models (2024)
Multimodal RAG
목록 보기
1/3
ColPali: Efficient Document Retrieval with Vision Language Models
Multimodal Retrieval-Augmented Generation (RAG) system by combining the colpali(https://huggingface.co/blog/manu/colpali) retriever for document retrieval with the Qwen2 Vision Language Model (VLM)(https://qwenlm.github.io/blog/qwen2-vl/)
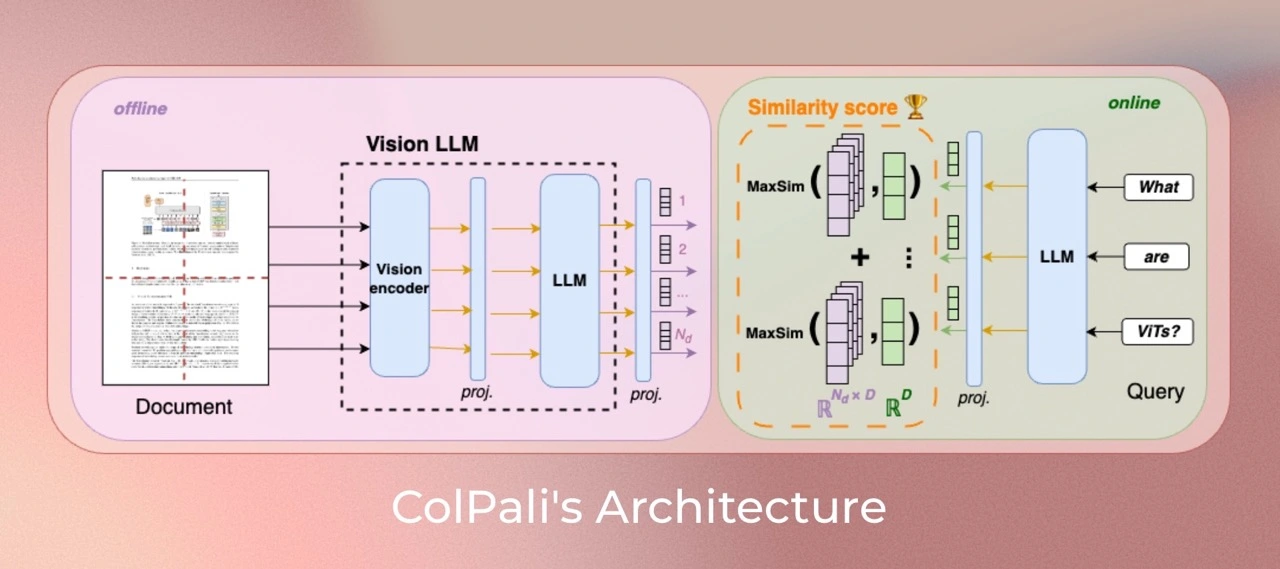
- Colpali : 최신 VLM의 문서 이해 능력을 활용하여 문서 메이지 이미지로부터 임베딩을 생성하는 retrieval model 구조
효율적으로 문서 인덱싱 - ColBERT-style의 multi-vector 표현(텍스트와 이미지의)을 생성해내는 PaliGemma-3B의 확장
- ColBERT의 late interaction mechanism을 통해 multi-vector retrieval
- OCR을 통해 데이터를 추출하는 복잡한 document processor pipeline에 의존하는 것 대신, 사용자 쿼리를 기반으로 관련 문서를 효율적으로 검색하는 Document Retrieval Model을 사용
- Interpretability visualization
- page-level retrieving tasks
✏️ ColPali architecture
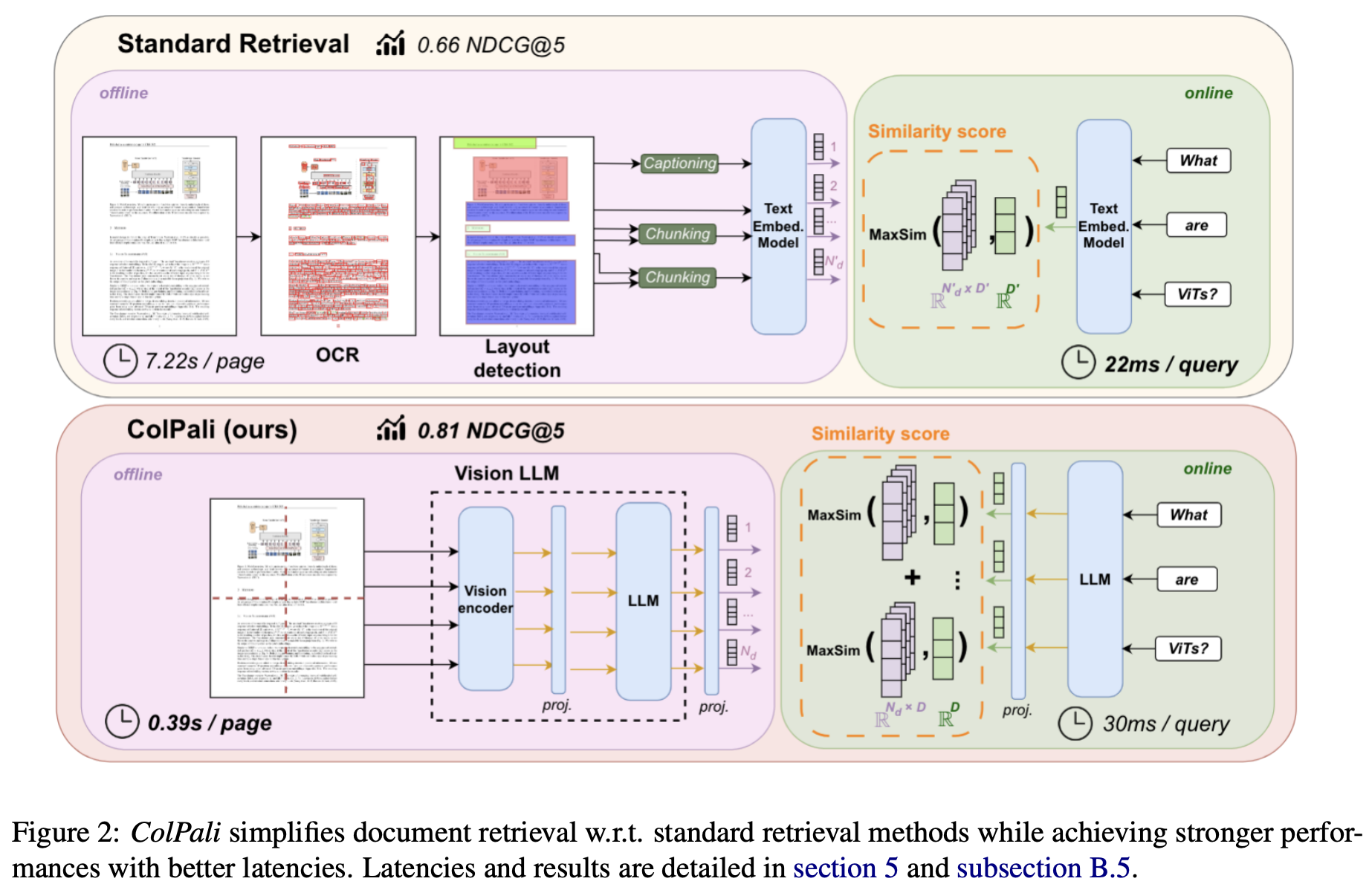
At its core, ColPali is built upon the PaliGemma, which combines:
- A SigLIP => patch embeddings
- A gemma-2b language model => contextualized embeddings
The ColPali architecture extends PaliGemma by adding:
- A projection layer to map language model embeddings to a lower-dimensional space (D=128)
=> multi-vector representation for each page - A late interaction mechanism inspired by the ColBERT.
- paligemma-3b-pt-224 : https://huggingface.co/google/paligemma-3b-pt-224
- SigLIP-so400m-patch14-384 : https://huggingface.co/google/siglip-so400m-patch14-384
- gemma-2b : https://unfoldai.com/gemma-2b/
- ColBERT : https://github.com/stanford-futuredata/ColBERT
- During querying, the query is embedded by the language model,
and a ColBERT-style late interaction (LI) matches query tokens to document patches. - The most similar patches for each query term are scored and summed to produce the final query-document match, offering efficient and rich retrieval.
- This combination allows ColPali to generate high-quality contextualized embeddings for document images and efficiently match them with text queries.
Contribution - page-level 문서 검색 시스템을 평가하기 위한 ViDoRe라는 comprehensive benchmark 만듦
- ColPali 주요 기여는 multi-vector와 late interaction based search를 VLM으로 확장한 것
효율적인 문서 인덱싱을 위한 모델 구조와 학습 전략 제안
late interaction mechanisms 기반으로 빠른 쿼리 매칭이 가능한 방법
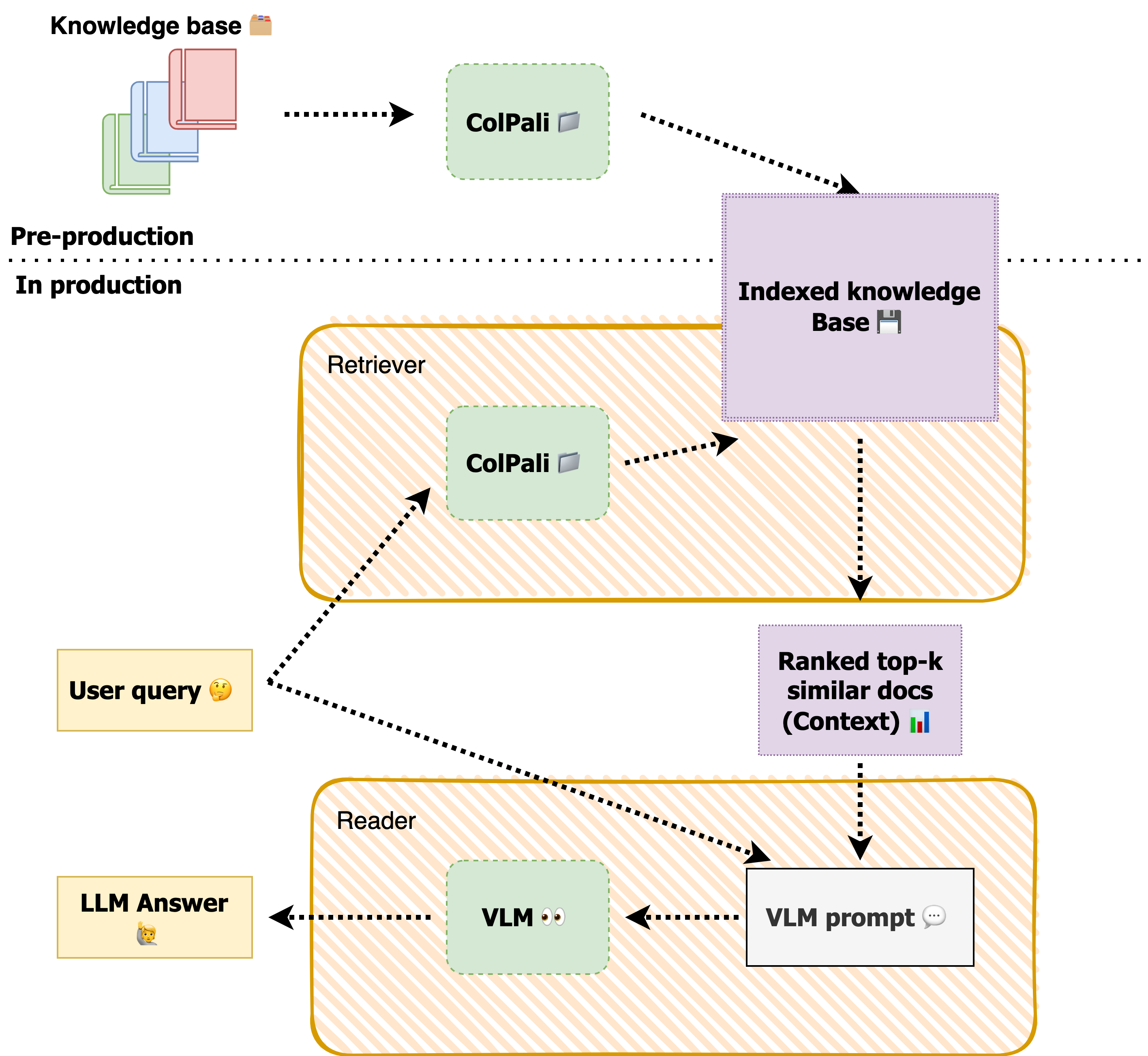
✏️ Documents retrieval 방식
🔍 Multi-vectors and Late Interaction
The authors of https://arxiv.org/abs/2004.12832 (2020) found that using a bag of vectors, instead of a single vector, not only improves retrieval accuracy, but also reduces retrieval latency as well as computation cost.
- query token - document token pair에 대해 Maxsim 계산
- 전체 문서에 대해 최대 유사성을 합산 = query-document match score
- 모든 쿼리 텀에 대해 각각 문서 텀에 대한 MaxSim을 계산하고, 이를 합쳐 스코어를 구함
- 유사도는 cosine similarity나 squared L2 distance 사용
- 문서와 쿼리가 검색 시에만 상호작용한다는 점에서 "late interaction"
- ColBERT에서 "l"이 late를 의미
- 문서에 대한 인덱싱/임베딩은 미리 해두고, 검색 시에는 query 임베딩만 생성
