Multimodal RAG
1.[Multimodal RAG] ColPali: Efficient Document Retrieval with Vision Language Models (2024)
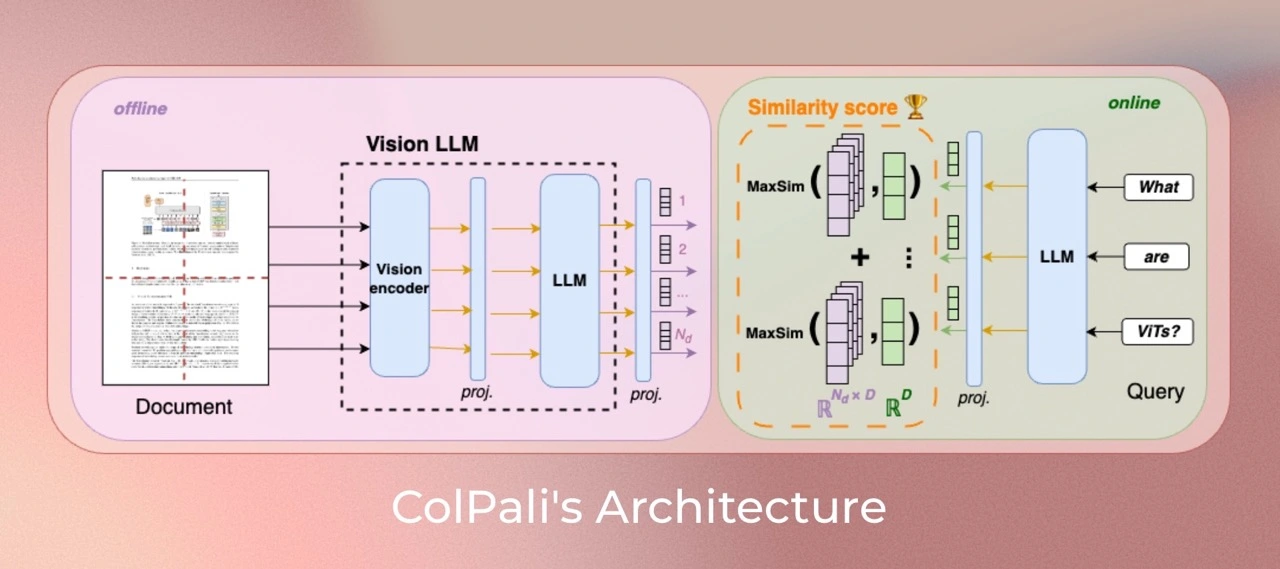
ColPali: Efficient Document Retrieval with Vision Language Models https://arxiv.org/abs/2407.01449 https://huggingface.co/learn/cookbook/multimodalra
2024년 11월 29일
2.[Multimodal RAG] VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents (2024)
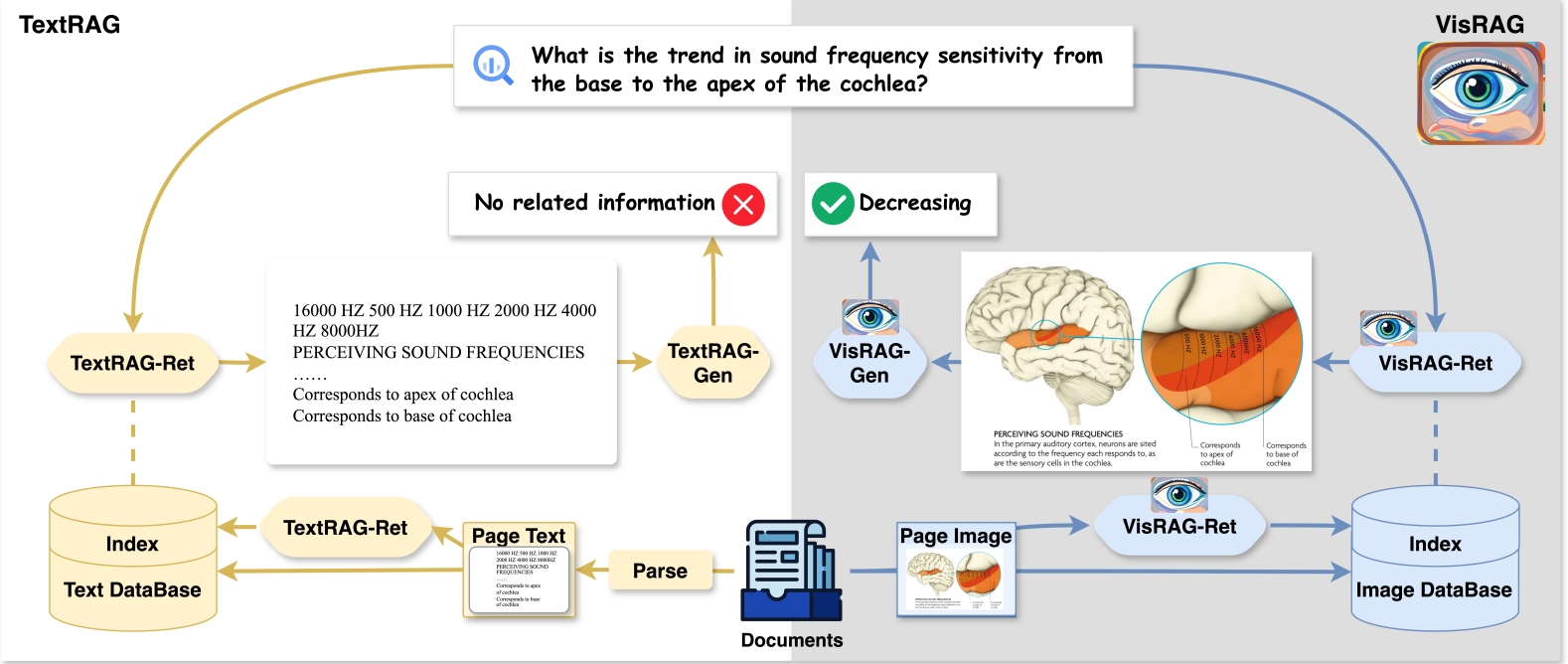
VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents (arxiv preprint 2024) https://arxiv.org/pdf/2410.10594 241014에 나온 pre
2024년 11월 29일
3.[Multimodal RAG] RagVL (RagLLaVA) (2024)
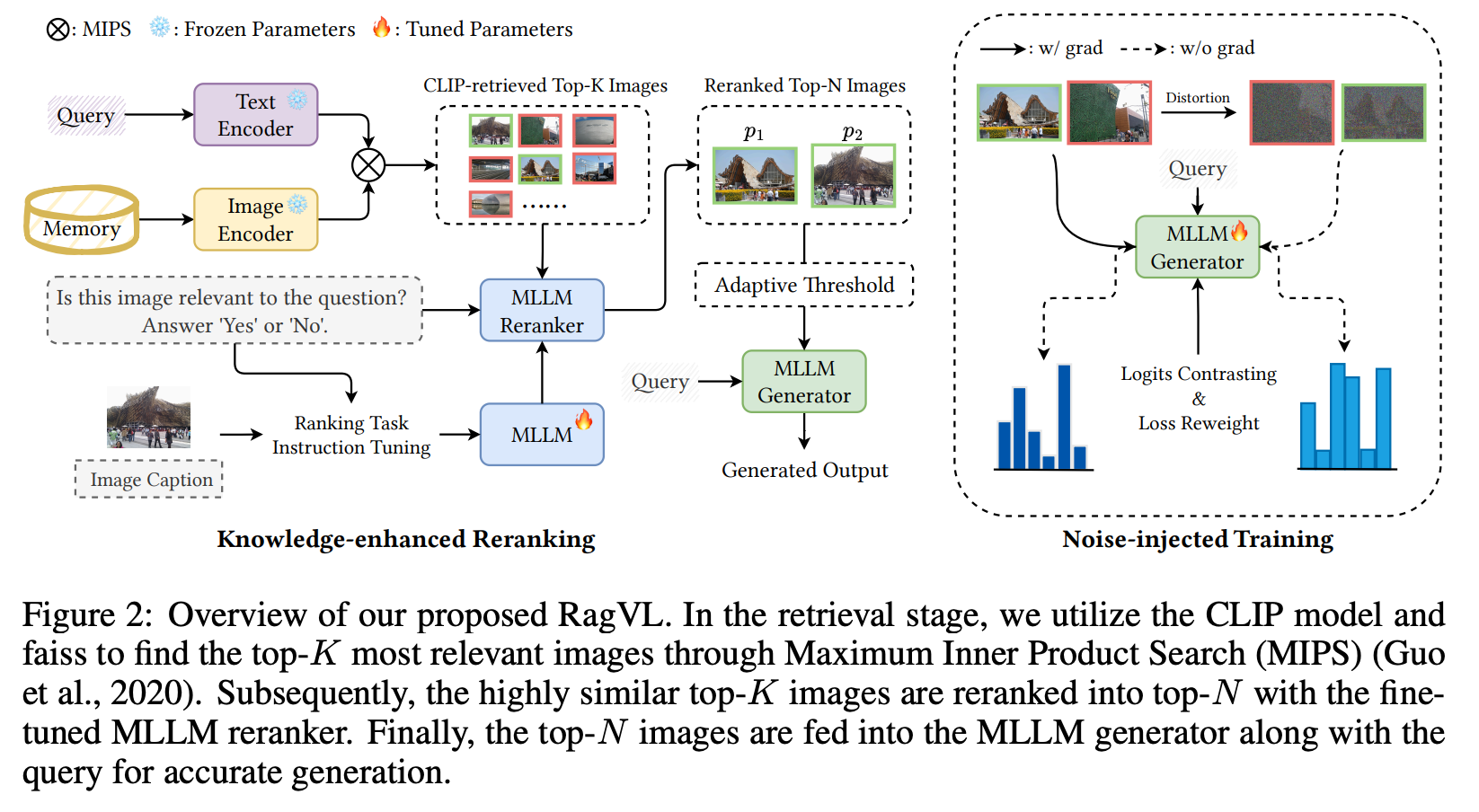
MLLM Is a Strong Reranker: Advancing Multimodal Retrieval-augmented Generation via Knowledge-enhanced Reranking and Noise-injected Training (2024 arXi
2024년 11월 29일