자연어 생성 모델
자연어 생성은 단어들의 sequence를 output으로 예측해내는 Task이다. 일반적으로 생성 모델은 각각 디코딩 단계에서 전체 단어 사전에 대한 확률 분포를 예측한다. 결국 단어를 실제로 뱉어내기 위해서는 모델이 예측한 확률 분포를 통해 각 Time Step의 단어로 decoding하는 과정이 있어야 한다.
모델이 예측한 확률 분포에 대해 디코딩하기 위해서는 예측된 확률 분포에 따라 가능한 모든 아웃풋 시퀀스의 조합을 탐색(Search) 해야 한다. 그런데 일반적으로 단어 사전은 수만 개의 혹은 그 이상의 토큰을 포함하고 있기 때문에 전체 공간을 탐색하는 것은 계산적으로 불가능하다. 여러가지 방법을 통해서 beam search가 고안되었다고 볼 수 있겠다.
Beam Search
Greedy decoding

greedy라는 단어를 보면 바로 감이 올 것이다. 매 Time Step마다 가장 높은 확률값을 가진 단어 하나만 선택하면서 이같은 과정을 계속 반복진행한다.
방법자체도 되게 간단하고 속도도 빠르다. 하지만 단어를 잘못 예측했을 때 문제가 발생한다. 정답 문장이랑 어긋난 후 뒤늦게 잘못 예측했다는걸 깨달아도 다시 돌아가는 것이 불가능하다. 즉 최적의 output을 내어주지 못한다.
Exhaustive search

결합분포의 chain rule을 활용하였다. 에서 작은값을 가져더라도 이후 값들에서 큰 값을 얻어 바뀔 수 있다. 하지만 가능한 모든 값들을 계산해야하기에 시간적 손실이 너무 크다는 단점이 있다. t Time Step까지 계산하는데 vocab_size=V라면 t시점까지 총 계산량은 가 될것이다. 시간복잡도가 어마어마하다.
Beam search
이방법은 greedy decoding과 Exhaustive search의 사이에 있는 것이다. '1개만 보자니 정확도가 떨어지고, 모두 다보자니 시간적 손실이 너무 크니까 개만 골라서 탐색을 해보자' 라는 아이디어이다. 여기서 우리는 를 beam size라 부르고 보통 5~10로 설정한다고 한다.
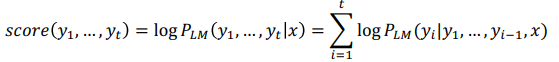
추가로 값을 계산식도 Exhaustive search와 비슷하지만 Time Step마다 전체단어가 아닌 값이 높은 상위 개만 탐색하고 log를 취해줌으로써 곱연산을 합연산으로 바꿔주었다.
항상 최적값을 제공한다는걸 보장하지는 못하지만 exhaustive search와 비교했을때는 엄청난 효율성을 보여준다.
example
아무리 글로만 주구장창 설명해도 예시가 있어야 아무래도 개념을 이해하는데 있어 머리에 잘들어오는 것 같다.
Beam size: 로 두고 beam search를 진행해보자
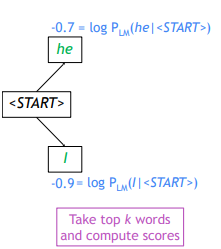
토큰부터 시작해 확률값이 가장 높은 2개를 선정한다.() 처음 값이 각각 -0.7, -0.9가 나오는데, 확률값에 로그를 취해주었기 때문에 값이 ~ 0까지의 값을 가지게 된다.
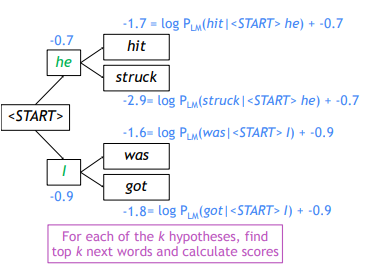
또 각 단어로부터 2개를 선정하여 값을 계산한다. he 뒤에 나올 가장 유력한 단어로는 hit, struck이 가장 확률값이 높다는 것이고, I 뒤의 was와 got도 마찬가지이다. 이 4개의 단어의 score값은 각각 -1,7, -2.9, -1.6, -1.8이므로 다음단계에서는 확률값이 높은 2개단어인 hit, was에서만 다음단어를 예측한다.
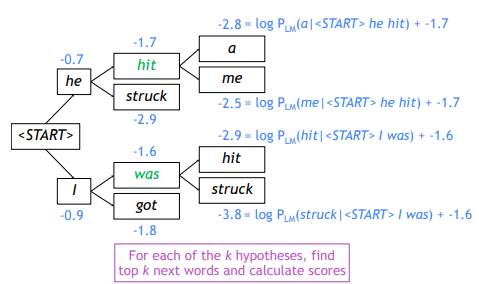
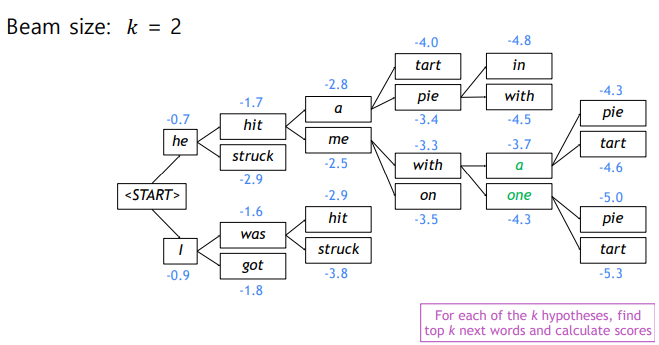
이와 같은 과정을 거치면서 단어를 예측한다.
decoding 과정을 끝낼 때, greedy decoding은 토큰을 예측하면 그즉시 종료하면 되지만, beam search는 서로 다른 Time Step에서 토큰을 만들 수 있기 때문에 T라는 Time step을 미리 설정해두었다가 모든 hypothesis를 종료할 수도 있고, n개의 hypothesis가 생성되면 종료하는 방법도 있다.
마지막으로 여러개의 hypothesis중에서 가장 높은 값을 가지는 문장만 선택하면된다. 그러나 여전히 모든 hypothesis의 sequence의 길이가 달라 문제가 생긴다. 더 많은 word를 가진 sequence가 더 많은 음수값이 더해지면서 점수가 낮아지기 때문에 공정하게 비교를 하기 위해 score값을 단어개수로 나눠줌으로써 최종score를 구할 수 있다.

references
https://littlefoxdiary.tistory.com/4
