Word Embedding
- 단어들을 특정한 차원으로 이루어진 공간 상의 한 점, 좌표로 변환해주는 기법으로 단어를 밀집표현(Dense Representation)으로 변환한다.
- text dataset을 학습 데이터로 주고 dimension수를 사전에 정하여 Word Embedding 알고리즘에 전달하면 학습이 완료된 후에 결과 값으로 각각의 단어의 최적의 벡터 표현형을 출력한다.
- 비슷한 의미를 가지는 단어는 가까운 공간에 표현(mapping)되도록 한다.
- 이후 다른 task 모델에 데이터를 넣을 때, 성능을 향상시킨다.
Word2Vec
- 워드 임베딩 학습방법중 유명한 방법중 하나
- 같은 문장에서 나타난 인접한 단어들 간 의미가 비슷할거란 가정을 사용
ex)
The cat purrs.
This cat hunts mice.
두 문장이 주어졌다.
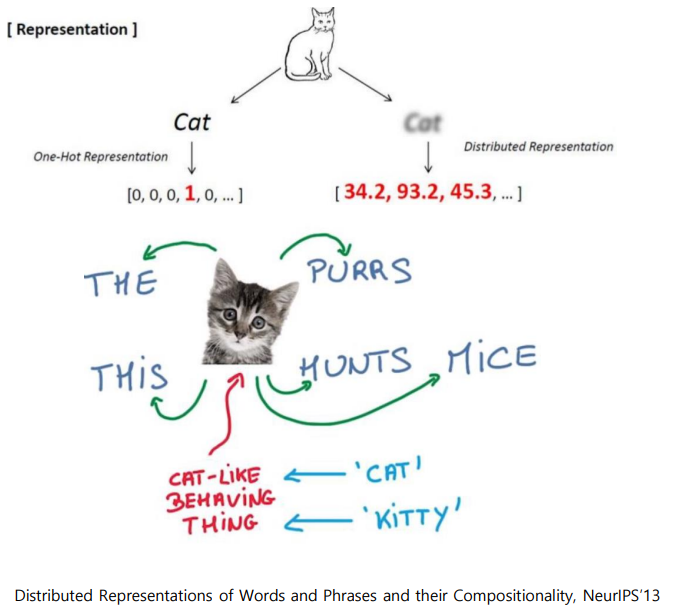
cat 주변 단어들의 확률분포를 예측한다.

만약 cat을 입력으로 주고 나머지 주변단어들을 숨긴채 예측해보면 높은확률로 meow, fleas, pet 단어가 높은확률로 등장함을 의미한다.
Word2Vec 알고리즘
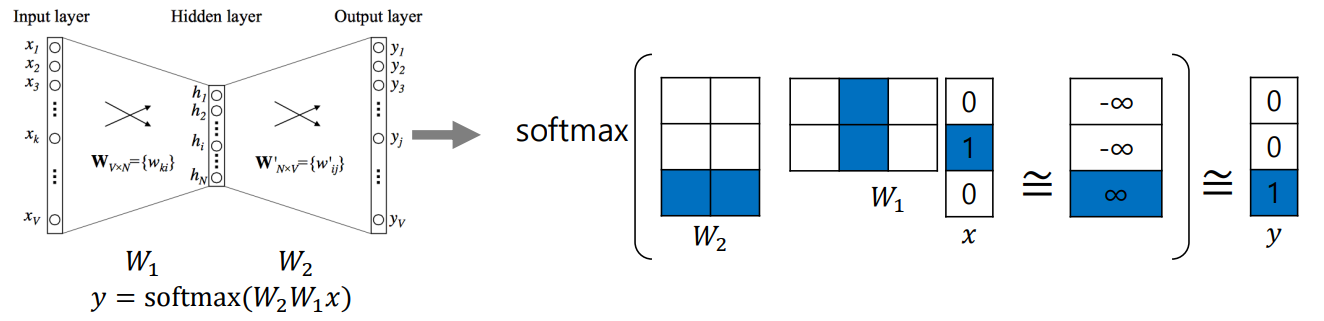
Word2Vec 알고리즘은 위 그림처럼 동작한다.
예를 들어 "I study math"라는 문장이 주어졌다.
- vocabulary={I, study, math}가 될 것이다.
- sliding window 방식으로 한 단어를 중심으로 앞뒤로 나타난 입출력 단어쌍을 구성할 수 있다.(window size=3 -> [(I,study),(study,I),(study,math)...])
- slidng window방식을 활용하여 Word2Vec의 Train 데이터를 구성할수 있다.
이 예제에서는 hidden layer=2로 설정하였다.(hyper parameter)
(x-study,y=math)를 가지고 알고리즘을 진행시켜보자.
x는 현재 [0,1,0]이라는 3차원 벡터이고 이를 2차원으로 매핑시켜야한다. 따라서 은 (2X3)의 모양을 가지고 출력을 다시 3차원으로 만들어야하기에 는 (3X2)의 모양을 가지게 된다. 마지막으로 softmax연산을 취해주어 math의 one-hot vector인 [0,0,1]과 거의 비슷하게 나오도록 학습을 시켜주면 된다.
추가적으로 one-hot vector이기에 (x-study,y=math)케이스에서는 파란색부분만 연산이 이뤄지는 것을 볼 수 있다.
https://ronxin.github.io/wevi/ 를 이용하여 시각적으로 확인 가능.
이를 통해서 Intrusion Detection(나열된 단어들중 가장 의미가 상이한 단어 고르기)뿐만 아니라 Machine translation, Semantic lexicon building 등 여러가지 task에서 사용된다.
Glove
또 다른 Word Embedding 기법중 하나이다.
-
Word2Vec의 장점, LSA의 장점을 모두 활용하는 기법인데, Word2Vec은 sliding window기법을 사용하여 주변단어만 학습하여 전체통계정보를 활용하지 못한다는 단점이 있고, LSA기법은 전체적인 통계 정보를 기반하지만, 단어간 사이의 의미(유사도)를 추출하는 성능은 떨어진다는 단점이 있다.
-
각 입력-출력 단어쌍에 대해 학습 데이터에서 주 단어가 한 window안에서 총 몇번 등장했는지 사전에 미리 계산을 하고 입출력 워드 임베딩 벡터의 내적값()이 에 가까워질 수 있도록 하는것이 목적이다.
: 입력word의 임베딩 벡터
: 출력word의 임베딩 벡터
: 한 window안에서 두 단어가 동시에 등장한 횟수

Glove 특징
- 중복되는 계산을 줄여줌. -> 학습 빨라짐
- 적은 데이터셋에도 학습 잘됨
- 단어간의 문법적 의미와 관계들까지도 효과적으로 학습 가능
Glove는 추후에 좀 더 자세히 다뤄봐야겠다.
