Precision & Recall
이미지 분류 모델처럼 cross-entropy loss와 같이 일반적인 방법들을 NLP모델에 적용한다면 맞지 않는 상황이 많이 생길 것이다. 만약에 문장 생성 task에서 한 문장이나 단어를 빼먹거나 문장을 더 많이 생성한다면 현재 상황을 제대로 반영하지 못한다.
예를 들어 I love you -> Oh I love you로 예측했다고 하면, 인간이 봤을때는 잘 예측한것으로 보이지만, 결론적으로 이 모델은 하나도 맞추지 못한 것이다. 하지만 이 경우는 Oh를 제외하기만 하면 모두 맞는 모델인데 기존 평가방법들은 이러한 정보를 반영하지 못한다.
그래서 이전에 배웠던 precision(정밀도)과 recall(재현율) 개념을 다시 생각할 수 있다.
precision: positive라고 예측한것 중에서 실제로 positive인 비율
recall: 실제 positive인것 중에서 positive라고 예측한 비율

하지만 만약 예측을 'Havana na in heart my is Half ooh of na'로 했다고 치면 비록 순서는 맞지않지만 모든 단어를 예측하는데 성공했다. 따라서 성능지표면에서는 되게 우수하게 나오지만, 말이되지않는 엉터리 문장이기 때문에 우리는 BLEU Score를 사용한다.
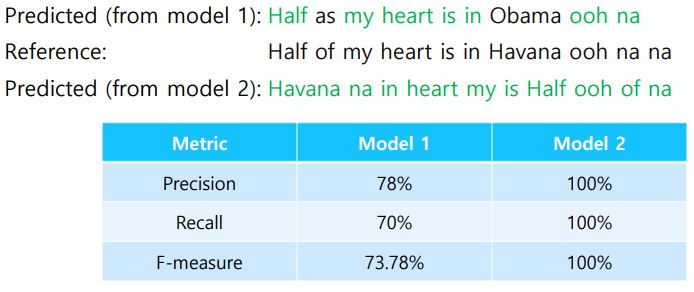
BLUE Score
- 하나하나 ground truth와의 비교뿐만 아니라 N-gram으로 연속된 단어와의 비교도 한다.
- Recall은 무시하고 Precision만을 가지고 구한다.
- 얼마나 빠짐없이 번역을 했는가 보다는 번역이 된 문장이 얼마나 의미를 잘 담고있는지가 더 중요하기 때문이다. NLP번역의 특징이라고 볼 수 있겠다.
정밀도는 실제로 negative인 데이터를 positive로 잘못 예측하면 치명적인 경우 더 중요한 지표료 여겨지고, 반대로 재현율은 실제로 positive인 데이터 예측을 negative로 잘못 예측하면 치명적인 결과로 이어지는 경우 더 중요한 지표로 여겨진다.
예를 들어 'I love this movie very much.'라는 문장이 있다고하자.
정답문장은 '나는 이 영화를 정말 많이 사랑한다.'가 될 것이다.
한글번역으로 '나는 이 영화를 많이 사랑한다.'라고 번역했을 때, '정말'이라는 단어가 있지 않아도 의미를 전달하는데는 큰 문제가 없다. 하지만 '나는 이 노래를 많이 사랑한다.'라고 번역했다면 똑같이 단어 하나 차이지만 의미를 전달하는데 큰 오류가 생긴것이다. 기계는 '노래'라는 단어를 positive라고 예상햇지만, 실제로는 negative인것이다. 이것이 정밀도만을 사용하는 이유이다.

수식에서 앞부분은 Brevity penalty라고 한다. reference의 길이보다 짧거나, 길지 않도록 penalty를 주기 위함이다. 산술평균을 취하지 않고 기하평균을 채택한 이유는 좀더 낮은값에 가중치를 부여하겠다는 의도가 담겨있다. 그러나 조화평균은 지나치게 가중치를 부여하기 때문에 기하평균을 택한것이다.(산술>=기하>=조화)
수식에서 뒤부분은 기하평균 수식이다. 1-gram ~ 4-gram의 기하평균을 내기위함이다.
Example
위에서 봤던 예시를 다시봐보자.
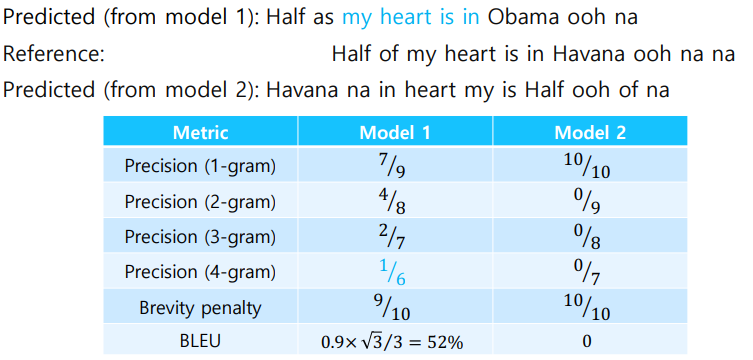
앞에서 봤던 pattern이 이상함에도 100%라는 성능지표를 보이는 문제가 BLEU Score를 사용함으로써 해결되었다.
