학습주제
BeautifulSoup
학습내용
이미 bs4을 공부 때 설치해봐서 이미 설치되어 있다고 했다.
html 파일은 requests를 통해 받아올 수 있음.
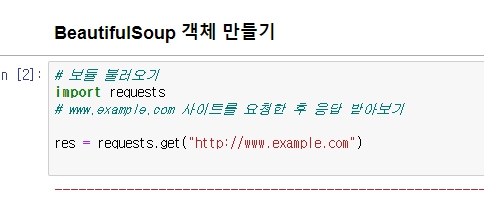
주의할 때 get() 안에 http://까지 full 주소를 넣어야 한다. 안그러면 오류남.
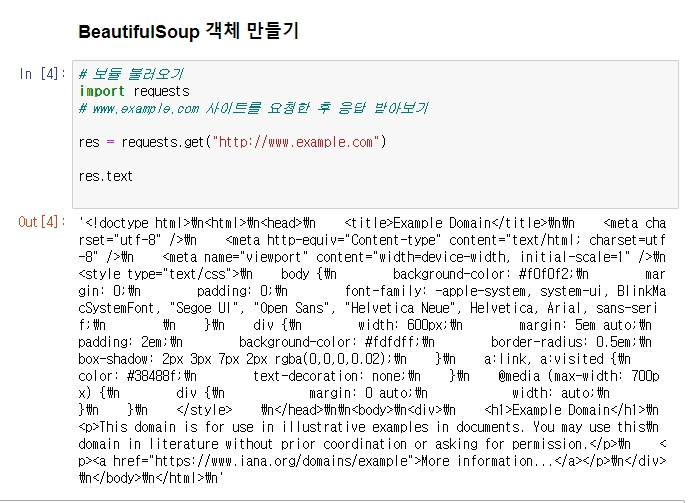
제대로 들어옴
bs는 xml, 다른 마크업 언어도 파싱해줌 따라서 어떤걸로 분석해줄지 넘겨줘야함.
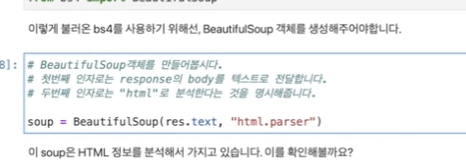
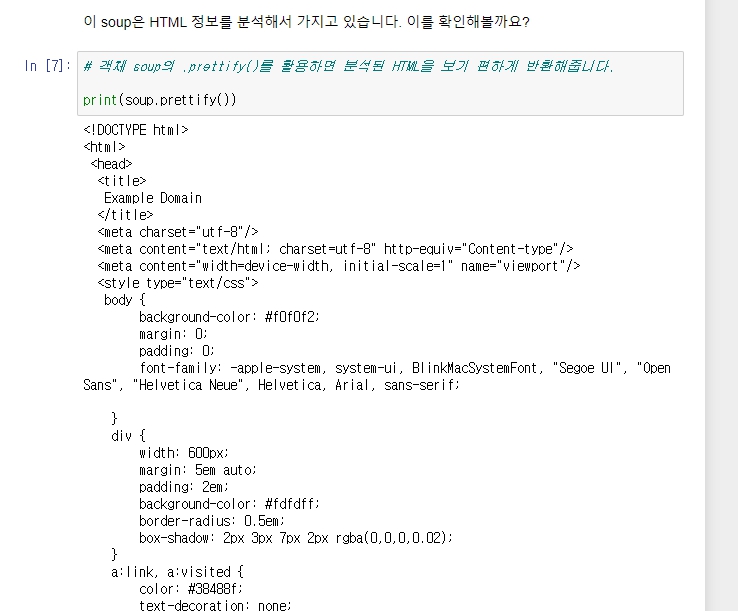
prettify()를 통해 보고 원하는 값이 어디 있는지 대략 확인.
soup을 이용하면 쉽게 얻을 수 있다.
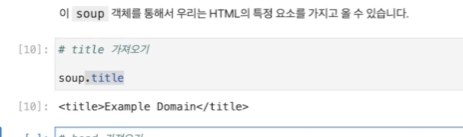

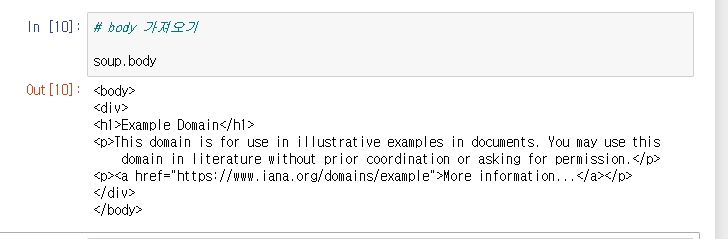
본격적으로 특정 요소를 찾을 수 있다. 이게 메인임.

내가 원하는 내용을 감싸는 태그의 이름을 넣으면, 그 내용을 리턴해준다. soup.find("h1")
를 사용했더니, 결과가 나오는 모습이다. find는 아래로 훑었을 때 제일 먼저 만나는 값 1개를 리턴해준다.
여러개를 가져오고 싶다면, find_all()함수를 사용한다.
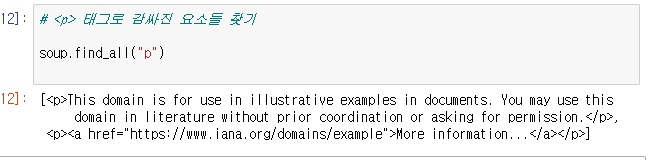
리스트로 두개 반환.
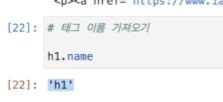
h1은
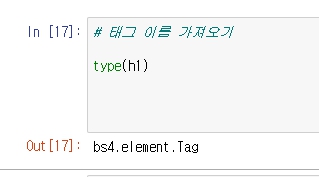
이런 객체이고, 이 겍체의 name에는 태그의 이름이 저장되어 있다.
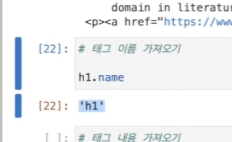

마찬가지로 태그의 내용도 접근할 수 있다.

반갑습니다 햄스터 좋아합니다