학습주제
예제를 이용한 beautifulsoup 실습
- 책 이름 모으기
학습 내용
요소가 웹페이지 전체의 어디에 속하는지 알아야함. html의 형태를 알아야함
chrome을 기준으로 f12
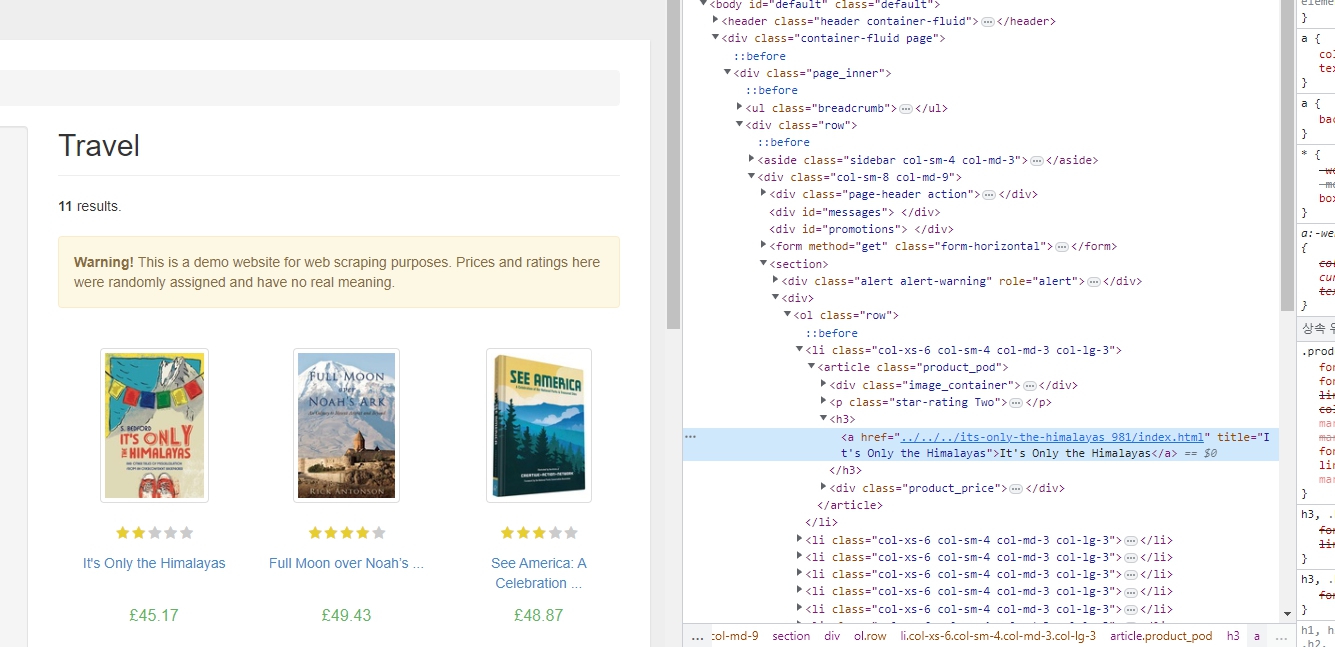
컨텐츠 기반 스크래핑이라고 함. 모든 사이트에 대해 이렇게 웹사이트를 보고 찾아가는 행위는 그렇게 좋지는 않음.
특정 태그를 찾고 스크래핑하는 방법은 가장 간단한 방법이지만 좋은 방법은 아님.
본 강의에선 간단하기 때문에 이용하기로 함.
크롬의 경우 오른쪽 버튼 '검사'를 누르면 원하는 태그를 바로 찾아줌.
저 태그를 찾고 오기 위해선 어떤 정보를 가지고 와야하는 지 알아야함.
h3를 검색해보면 총 11개가 나오는데, 모두 책의 타이틀 이름을 갖고 있는 것을 알 수 있다.
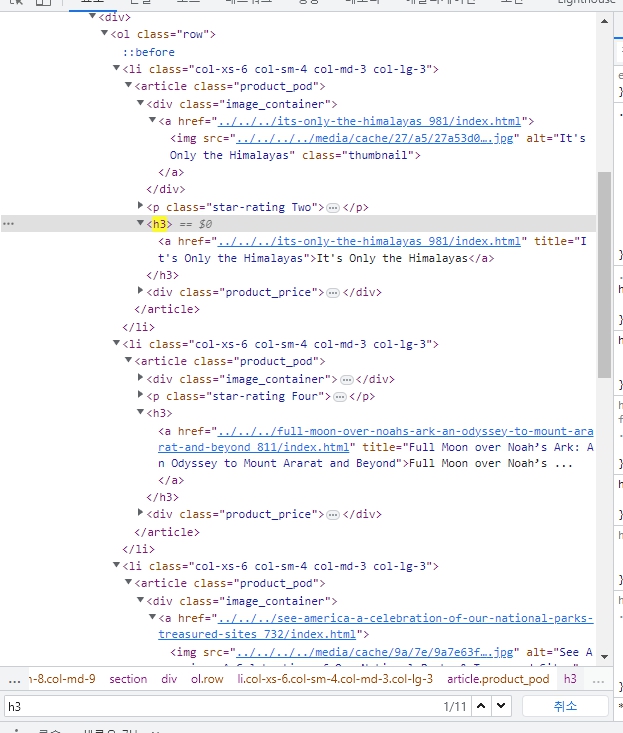
그렇다면 저 h3 요소의 집합을 가져오라는 정책을 세울 수 있음.
이건 관찰에 의한 결론임.
코드로 구현하면 스크래핑은 끝남.
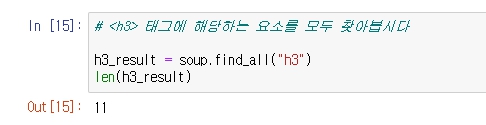
그러나 h3를 가져오려니 생각보다 많은 태그로 감싸져 있는 것을 확인할 수 있다.

requests로 요청한 정보를 get()을 통해 얻었고, bs로 분석까지 마친 상황.

find('h3')을 하자, 제일 첫번째로 파싱된 히말라야 책이름이 나온 것을 확인.

0번째 원소에 히말라야 책이 잘 들어있는 것을 확인.
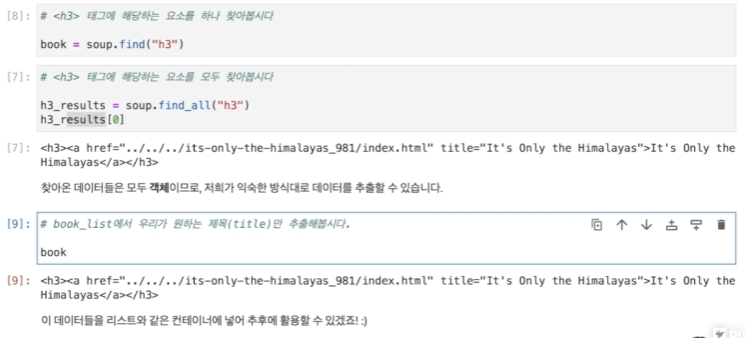
book은 객체이다. 속성과 메서드에 접근할 수 있음.
h3 내에 있는 태그부분을 속성으로 사용할 수 있음.
book.a를 하자

h3 내에 a태그의 요소가 리턴
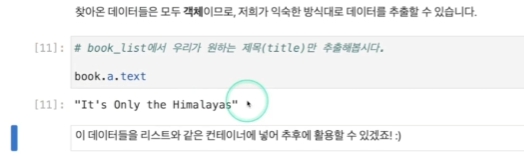
책 타이틀이 리턴된 것을 확인함.

중간에 짤려있는 글자가 있음.
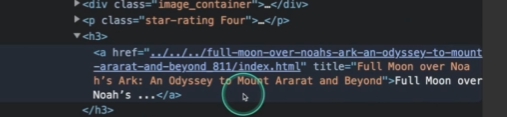
타이틀에는 full name이 들어 있는 것을 확인.
이에 접근하기 위해 딕셔너리를 키로 접근하는 것처럼 활용하면 되는데,
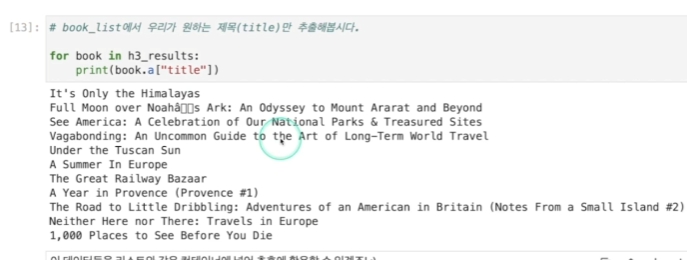
full name이 잘 뜨는 것을 확인할 수 있다.
이 자료를 컨테이너, set, 리스트 등으로 모아서 자료로 활용할 수 있다.
결국 스크래핑을 잘 하기 위해선, html구조를 잘 이해하고, beautifulsoup의 기능을 잘 숙지해야 한다.
