✔ Hyperparameter vs Parameter
- Hyperparameter : 모델링 시 사용자가 직접 새팅해주는 값
- ex) learning rate, max_depth, n_estimators 등
- Parameter : 모델 내부에서 결정되는 변수
- ex) 정규분포의 평균, 표준편차 등
Hyperparameter와 Parameter를 구분하는 기준은 사용자가 직접 설정하느냐 아니냐이다.
✔ Hyperparameter Tuning
-
Hyperparameter Tuning 정의
- Hyperparameter optimization 이라고도 함.
- 모델을 최적화하기 위해 Hyperparameter를 조정하는 과정
- train/test 데이터로 분할 후, trian 데이터를 이용한 교차 검증을 통해, 선정한 Hyperparameter 조합의 결과를 비교하여 최적의 Hyperparameter를 찾아낸다.
-
Hyperparameter Tuning 필요성
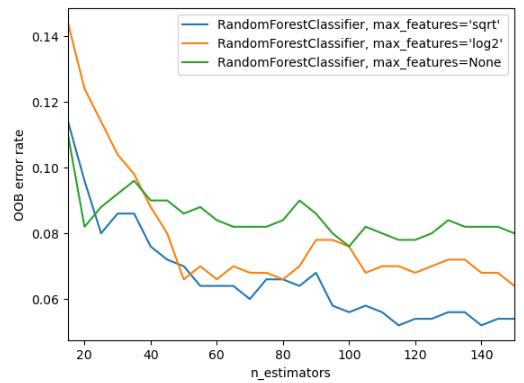 위의 그래프를 보면, 모델은 Random Forest로 동일하지만, 모델의 Hyperparameter인 max_features 변수를 다르게 설정함에 따라 OOB error값이 달라진다. (
위의 그래프를 보면, 모델은 Random Forest로 동일하지만, 모델의 Hyperparameter인 max_features 변수를 다르게 설정함에 따라 OOB error값이 달라진다. (OOB error에 대해서는 다른 포스팅에서 설명하겠다. 지금은, 모델의 성능을 나타내는 값이라 이해하면 된다.) 따라서, 우리가 어떠한 Hyperparameter를 설정, 즉 Hyperparameter Tuning을 어떻게 하냐에 따라 모델의 성능이 좌지우지 될 수 있다.
-
주의사항
📌 Hyperparameter Tuning 시, test 데이터를 사용해서는 안 된다. Test 데이터는 모델의 최종 성능 평가에만 사용된다. (Test 데이터를 우리가 아예 모르는 미래의 어떠한 데이터라 생각하면 이해하기 쉽다.)
📌 주의사항 : Hyperparameter Tuning 의 종류에 따라 시간이 너무 오래 걸릴 수 있다. 따라서, 예를 들어 하나의 변수를 고정하고, 다른 변수를 변화시키면서 하나하나 일일이 대입해보면서 성능의 변화를 통해 대략적인 감으로 튜닝을 진행해야 할 수도 있다. (
실제로 필자가 대용량 데이터를 다루면서 겪어본 바이다.)
✔ Hyperparameter Tuning 의 종류
-
Grid Search
Grid Search를 한 문장으로 표현하자면 다음과 같다.
제시한 Hyperparameter 들을 모두 조합하여 모델에게 가장 적합한 Hyperparameter 를 찾는 방법
-
정의
Grid Search 는 간단하고 광범위하게 사용되는 Hyperparameter 탐색 알고리즘이다. 사용자가 지정한 grid에 속한 모든 Hyperparameter를 조합하여 최고의 조합을 비교해가며 찾는 과정을 뜻한다. 실험할 Hyperparameter를 명시적으로 정해줘야 한다.
-
장점
- 원하는 값을 정확하게 비교하여 분석 가능
-
단점
- 시간이 매우 오래 소요됨
- 미리 정의한 Hyperparameter 세트만 탐색함
- 성능이 최고점이 아닐 가능성이 높음 (여러 개를 비교하여 그 중 최고를 찾는 기법이지, 성능이 가장 높은 점을 찾는 기법이 아님)
-
코드
-
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
### 파라미터를 딕셔너리 형태로 설정
params = {'max_depth' : [1,2,3], 'min_samples_split' : [2,3]}
iris = load_iris()
data = iris.data
label = iris.target
x_train, x_test, y_train, y_test = train_test_split(data, label,
test_size = 0.2,
random_state=121)
dtree = DecisionTreeClassifier(random_state=156)
# param_grid의 하이퍼 파라미터를 3개의 train, test set fold로 나누어 테스트
### refit = True가 default. True이면 가장 좋은 파라미터 설정으로 재학습시킴
grid_dtree = GridSearchCV(dtree, param_grid = params, cv=3, scoring = 'accuracy', refit=True)
# 붓꽃 학습 데이터로 param_grid의 하이퍼 파라미터를 순차적으로 학습/평가
grid_dtree.fit(x_train, y_train)
print('GridSearchCV 최적 파라미터:', grid_dtree.best_params_)
print('GridSearchCV 최고 정획도: {:.4f}'.format(grid_dtree.best_score_))- 위 코드에 대한 설명
- 먼저, Decision Tree 클래스를 만든 후, 임의로 설정한 Hyperparameter 를 조합하여 모든 조합에 대해 평가를 한다.
- GridSearchCV를 통해 먼저 객체를 만든 후, train 데이터로 학습을 한다. 주의할 점은 test 데이터는 아예 사용이 되어서는 안 된다.
- 각 조합에 대해 평가를 할 때에는 교차 검증을 통해 train 데이터를 train/valid로 나눈 후 평가하고, 이를 바탕으로 최고의 Hyperparameter 조합을 찾아낸다.
- 코드 결과
GridSearchCV 최적 파라미터: {'max_depth': 3, 'min_samples_split': 2}
GridSearchCV 최고 정획도: 0.9750
위 코드에서 GridSearchCV 의 인자를 refit = True (default = True)로 설정했기 때문에, 이미 가장 최적의 Hyperparameter로 재학습이 되어 있다. 최적의 Hyperparameter로 결과를 예측하는 코드는 다음과 같다.
from sklearn.metrics import accuracy_score
pred = grid_dtree.predict(x_test)
print('테스트 데이터 세트 정확도: {0:.4f}'.format(accuracy_score(y_test, pred)))- 코드 결과
테스트 데이터 세트 정확도: 0.9667
-
Random Search
Random Search를 한 문장으로 표현하자면 다음과 같다.
주어진 구간 안에서 랜덤으로 숫자를 뽑은 후 이를 조합하여 가장 적합한 Hyperparameter 를 찾는 방법
-
정의
Random Search 는 사용자가 정한 범위 내에서 임의의 조합을 추출하여 최적의 Hyperparameter 조합을 찾는 방법이다. Grid Search 와는 다르게 실험할 Hyperparameter를 구간으로 주거나 직접적인 값을 넣어주기도 한다. 랜덤으로 총 몇 개의 조합을 뽑을지 명시해줄 수 있다. -
장점
- Gird Search 보다 비교적 빠르게 탐색 가능
- 랜덤으로 선택하니, Grid Search 보다 성능이 좋은 점으로 갈 가능성이 높음 (ex. grid = 0.1, 0.2, ..., 0.9 로 가정. 그런데, 최고의 값이 0.178 이라면? 즉, Grid Search 로는 뽑아낼 수 없는 값이라면?)
-
단점
-
Hyperparameter의 범위가 너무 넓으면, 일반화된 결과가 나오지 않음 (할 때마다 달라짐)
-
Grid Search 와 마찬가지로 최종 성능이 최고점이 아닐 가능성이 높음
-
-
코드
-
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import RandomizedSearchCV
iris = load_iris()
data = iris.data
label = iris.target
dt_clf = DecisionTreeClassifier(random_state=156)
x_train, x_test, y_train, y_test = train_test_split(data, label,
test_size = 0.2,
random_state=100)
# 구간으로 주거나 직접적인 값을 넣기도 함. 랜덤으로 뽑아서 사용
params = {'max_depth' : range(1,11),
'max_leaf_nodes' : range(3,31,3),
'criterion' : ['gini', 'entropy']}
# k-fold 방식으로 최적의 하이퍼 파라미터 값을 찾아내는 과정
rs = RandomizedSearchCV(dt_clf, param_distributions = params,
n_iter = 6, cv = 4, refit = True,
scoring = 'accuracy',
random_state = 101, n_jobs = -1)
# param_distributions : 하이퍼 파라미터 목록 전달
# n_iter : 파라미터 검색 횟수 (총 랜덤으로 뽑은 조합 개수)
# cv : 교차검증 시 fold 개수
rs.fit(x_train, y_train)
print('RandomSearchCV 최적 파라미터:', rs.best_params_)
print('RandomSearchCV 최고 정획도: {:.4f}'.format(rs.best_score_))- 위 코드에 대한 설명
- 구현하는 방식은 Grid Search 와 유사하다. 다만, Hyperparameter 를 구간 혹은 직접적인 값을 넣는다.
- RandomizedSearchCV 인자인 n_iter 를 기입하여 총 랜덤으로 뽑을 조합의 개수를 정해준다. (
Grid Search 는 모든 조합을 시도하기에 기입할 필요가 없다.)
- 코드 결과
RandomSearchCV 최적 파라미터: {'max_leaf_nodes': 6, 'max_depth': 4, 'criterion': 'gini'}
RandomSearchCV 최고 정획도: 0.9667
✔ Hyperparameter Tuning 에 대한 조언
만약 여러분이 충분히 원하는 예측 결과가 나오지 않은 상태에서 Hyperparameter Tuning 을 통해 성능 개선을 원한다면, Hyperparameter Tuning 보다는 데이터에 대한 접근 및 모델링 방식을 다시 한 번 생각해 보는것을 추천한다. Hyperparameter Tuning 으로 개선할 수 있는 부분은 어느 정도 한계가 존재한다.
추후에, Bayesian Optimization에 대해 다루고, 이를 이용한 HyperOpt에 대해 소개하겠다. (가능하면 Optuna도)
