✔ 과적합이란?
- ML 모델이 학습된 데이터에선 정확한 예측을 하지만, 새로운 데이터에 대해서는 그렇지 못할 때 발생하는 현상을 뜻한다.
✔ 교차 검증이란?
- 데이터를 train/test로 한 번만 나누는 것이 아닌, 여러 번 다른 방식으로 나누고, 나눈 train/test 데이터를 교차하여 선택하여 이를 토대로 모델의 성능을 평가하는 방법이다.
✔ 교차 검증을 하는 이유
예를 들어, ML 모델 학습을 위해 데이터를 train/test 데이터로 나눈다고 하면, 고정된 train/test 데이터를 통해 학습 및 예측을 하게 된다. 즉, test에서 쓰이는 데이터는 train에서 전혀 쓰이지 않는다는 것이다. 만약, train/test 데이터를 다른 방식으로 나누었다면 예측 결과가 나쁘게 나왔을 수도 있다. 즉, 과적합이 발생할 가능성이 있다. 따라서, 데이터를 train/test 데이터 세트로 여러번 나눈다면 한 번 나누어서 학습한 것에 비해 일반화된 성능을 얻을 수 있다.
✔ 교차 검증의 종류
K-Fold 교차 검증
K-Fold 교차 검증을 한 문장으로 표현하자면 다음과 같다.하나의 집합을 여러 개의 부분 집합으로 나눈 후 바꿔가면서 모형의 성능을 측정하는 방식
전체 데이터 세트에서 train/test 데이터로 나눈 후 그 train 데이터를 다시 K개의 데이터 fold로 분할한다. (전체 데이트 세트를 K개의 fold로 나누는 경우가 있는데, test 데이터는 학습 및 검정에 관여하면 안 되므로 전체 데이터 세트에서 분할하면 안 된다. test 데이터는 최종 성능 평가에만 관여한다. 다만, 데이터의 수가 너무 적어서 test 데이터까지 포함하여 교차 검증을 진행해야 할 수도 있다.) 그 이후, 1,2,...,k번째의 fold를 각각 valid로 사용하고 나머지를 train으로 사용하여 교차 검증을 실시한다. 말로 설명하면 이해하기 어렵지만 다음 그림을 보면 이해가 훨씬 수월해진다.
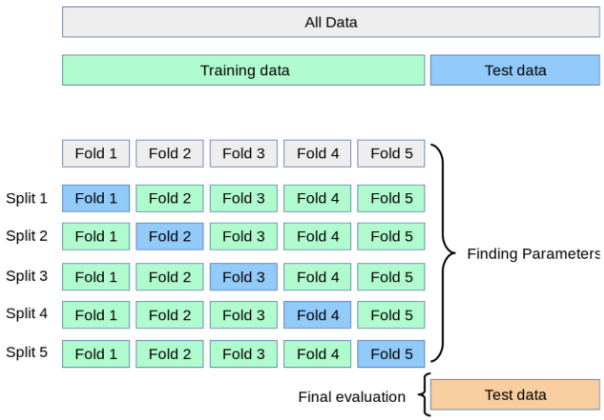
K-Fold 교차 검증의 과정은 다음 순서와 같다.
- 전체 데이터를 train/test 데이터로 분할한다.
- train 데이터를 다시 train/valid 데이터로 K개의 fold로 분할한다.
- Split1에서 Fold 1을 valid, Fold 2 ~ Fold 5를 train으로 사용하여 train으로 모델을 훈련한 후, valid로 평가한다.
- 마찬가지로, Split k에서 Fold k를 valid, Fold k를 제외한 나머지 fold를 train으로 사용하여 train으로 훈련 후 valid로 평가한다.
- Split k개에서 각각 성능을 평가하므로 총 k개의 성능 결과가 나오는데, 이 k개의 평균을 낸 것이 해당 학습 모델의 성능이라 한다.
K-Fold를 실행하는 코드는 다음과 같다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
from sklearn.datasets import load_iris
import numpy as np
iris = load_iris()
features = iris.data
label = iris.target
kfold = KFold(n_splits = 5) # 각 Split에 몇 개의 fold로 분할할지 정해줌
cv_accuracy = []
dt_clf = DecisionTreeClassifier(random_state = 156)
for train_index, test_index in kfold.split(featrues): # 각 Split에 대해 train/valid로 분할
x_train, x_test = features[train_index], features[test_index]
y_train, y_test = label[train_index], label[test_index]
dt_clf.fit(x_train, y_train) # 어차피 fit 한 것이 overwrite 됨 -> 다시 DT Classifier를 실행할 필요가 없음
pred = dt_clf.predict(x_test)
acc = np.round(accuracy_score(y_test, pred), 4)
cv_accuracy.append(acc)
print(np.mean(cv_accuracy))-
위 코드에 대한 설명
- 직접 각 Split에 쓰일 train/valid 데이터를 선정한 후 이를 교차하며 선택하여 성능을 측정한다. 측정한 성능은 리스트에 저장 후 마지막에 평균을 이용하여 교차 검증 결과를 구한다.
- 각 Split에 대해 몇 개의 fold로 분할할 지는 KFold( )의 n_splits 인자를 통해 선택한다. 일반적으로는 5 혹은 10으로 설정하지만, 데이터의 종류 및 컴퓨터의 성능 등 상황에 따라 맞추어 설정해야 한다.
- 주의사항 : 각각의 Split의 train을 학습할 때마다 DT Classifier( )를 다시 불러서 이전 Split에서 학습한 데이터를 초기화해야 한다고 생각했다. 하지만, ML 모델에 학습, 즉 fit( )을 할 경우 이전에 학습시켰던 데이터는 사라지고 가장 최신으로 학습시킨 데이터만 학습을 한다. 즉, 이전에 학습시킨 데이터는 overwrite 된다.
- 직접 각 Split에 쓰일 train/valid 데이터를 선정한 후 이를 교차하며 선택하여 성능을 측정한다. 측정한 성능은 리스트에 저장 후 마지막에 평균을 이용하여 교차 검증 결과를 구한다.
교차 검증에서 쓰이는 성능?
K-Fold 교차 검증을 실시할 때, 각 Split 별 accuracy를 평균하여 검증 결과를 산출하였다. 항상 accuracy가 쓰이는 것은 아니며, 주어진 문제의 성격과 목적 및 데이터의 종류에 따라 사용되는 평가 방식이 달라질 수 있다. 예를 들어 회귀 문제에서는 MSE, MAE 등을 사용할 수 있으며, 분류 문제에서는 F1 score, precision, recall 등을 사용할 수 있다.
Stratified K-Fold 교차 검증
Stratified K-Fold 교차 검증을 한 문장으로 표현하면 다음과 같다.데이터의 label 분포도 특성을 반영한 K-Fold 교차 검증 방식
Stratified K-Fold 교차 검증은 위에서 설명한 K-Fold 교차 검증과 매우 유사하다. 다만, label의 특성을 반영해준다. 따라서, 불균형한 label 분포를 가진 데이터 세트에 굉장히 효과적이다.
예를 들어, 대출 사기 데이터를 예측한다고 하면, 총 데이터 수가 1억 건이고 그 중 단 1,000건의 대출 사기로 구성되어 있다 하자. 그렇다면, 교차 검증 시 train/valid로 분할할 때 1 레이블 값의 비율이 매우 작기 때문에 label 비율을 반영하지 못할 수 있고, 이로 인해 제대로 된 예측을 하지 못할 수 있다. (조금 과장을 보태자면 train에서는 모든 label : 0, valid에서 모든 label : 1로 구성될 수도 있다.) 따라서, 원본 데이터와 유사한 label 분포를 train/valid 데이터에도 유지하는 것이 중요하다.
Stratified K-Fold 교차 검증은 이와 같은 문제점을 해결해준다. train/valid 분할 시 label 분포도에 따라 분할해준다. 따라서, split( ) 인자로 feature 데이터 뿐만 아니라 label 데이터도 기입하여야 한다. (K-Fold의 경우 feature 데이터만 입력하고 label 데이터는 입력하지 않아도 된다.)
Stratified K-Fold를 실행하는 코드는 다음과 같다.
from sklearn.metrics import accuracy_score
import numpy as np
from sklearn.model_selection import StratifiedKFold
dt_clf = DecisionTreeClassifier(random_state=156)
features = iris_df.drop('label', axis = 1)
label = iris_df['label']
skfold = StratifiedKFold(n_splits = 3)
n_iter = 0
cv_accuracy = []
# StratifiedKFold의 split() 호출 시 반드시 레이블 데이터 세트도 추가 입력 필요
for train_index, test_index in skfold.split(features, label):
x_train, x_test = features.loc[train_index], features.loc[test_index]
y_train, y_test = label.loc[train_index], label.loc[test_index]
dt_clf.fit(x_train, y_train)
pred = dt_clf.predict(x_test)
acc = accuracy_score(y_test, pred)
cv_accuracy.append(acc)
n_iter += 1
print('\n#{0} 교차 검증 정확도: {1}, 학습 데이터 크기: {2}, 검증 데이터 크기: {3}'
.format(n_iter, acc, len(train_index), len(test_index)))
print('#{} 검증 세트 인덱스:'.format(n_iter), test_index)
print('## 교차 검증별 정확도:', cv_accuracy)
print('## 평균 검증 정확도:', np.mean(cv_accuracy))-
위 코드에 대한 설명
- 전반적인 코드는 KFold를 실행하는 코드와 유사하다. 다만, split( )인자로 label 데이터를 추가적으로 입력하여 label 데이터의 특성 (분포도)을 반영해준다.
- 전반적인 코드는 KFold를 실행하는 코드와 유사하다. 다만, split( )인자로 label 데이터를 추가적으로 입력하여 label 데이터의 특성 (분포도)을 반영해준다.
-
cross_val_score( )
위에서는 교차 검증을 하기 위해 K-Fold, Stratified 모듈을 이용하였다. 다소 코드가 복잡하였는데, 사이킷런에는 교차 검증을 더 편리하게 해주는 모듈을 제공한다. 형식은 다음과 같다.
cross_val_score(estimator, x, y = None, scoring = None, cv = None)
estimator : 분류 알고리즘인 Classifier, 회귀 알고리즘인 Regressor를 의미
cv : 교차 검증 fold 수cross_val_score( )는 cv로 지정된 횟수만큼 지정된 평가 지표로 평가 결괏값을 배열로 반환해준다. 일반적으로, 이 결과값들의 평균을 평가 수치로 사용한다.
내부적으로 Stratified K-Fold를 사용하지만, estimator로 회귀가 입력되면 Stratified K-Fold 방식으로 분할할 수 없으므로 K-Fold 방식을 사용한다. (분류가 입력되면 Stratified K-Fold 이용)
분류를 이용하려면 label로 함께 입력하여야 한다. estimator의 종류에 따라 cross_val_score( )가 자동으로 방식을 채택한다.cross_val_score( )의 예시 코드는 다음과 같다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
iris_data = load_iris()
dt_clf = DecisionTreeClassifier(random_state=156)
data = iris_data.data
label = iris_data.target
# 성능 지표는 정확도(accuaracy), 교차 검증 세트는 3개
scores = cross_val_score(dt_clf, data, label, scoring = 'accuracy',cv=3)
# estimator, features, label, 성능 지표 측정값, fold 개수
print('교차 검증별 정확도:', np.round(scores,4))
print('평균 검증 정확도:', np.round(np.mean(scores),4))만약, 분류에 Stratified K-Fold 방식이 아닌 K-Fold 방식으로 사용하고 싶다면, 다음과 같이 사용하여야 한다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
from sklearn.datasets import load_iris
iris_data = load_iris()
dt_clf = DecisionTreeClassifier(random_state=156)
data = iris_data.data
label = iris_data.target
kfold = KFold(n_splits = 6, shuffle = True, random_state = 0) # 직접 KFold 객체를 생성하여 제어
# 성능 지표는 정확도(accuaracy), 교차 검증 세트는 3개
scores = cross_val_score(dt_clf, data, label, scoring = 'accuracy', cv = kfold)
# estimator, features, label, 성능 지표 측정값, 사용하고 싶은 방식
print('교차 검증별 정확도:', np.round(scores,4))
print('평균 검증 정확도:', np.round(np.mean(scores),4))✔ 교차 검증의 장단점
장점
- 특정 데이터셋에 대한 과적합 방지
- 더욱 일반화된 모델 생성 가능
- 데이터 부족으로 인한 underfitting 방지
단점
- 모델 훈련 및 평가 소요시간 증가
- 모델 훈련 및 평가 소요시간 증가
✔ 교차 검증은 언제 사용?
- 계산 부담이 크지 않은 소규모 데이터 세트의 경우 사용
- 대규모 데이터 세트의 경우 단일 검증 세트로도 충분 (하나의 validation set으로 충분)
