seaborn 라이브러리는 matplotlib을 기반으로 만들어진 시각화 도구다. seaborn은 matplotlib보다 다양한 색상과 통계 기능을 제공하기에 데이터 분석에 많이 사용된다. 시각적인 효과를 강조하고 싶다면 seaborn은 좋은 선택일 것이다. 앞서 말했듯이 seaborn은 라이브러리이기에 사용을 하기 위해 import를 우선적으로 해줘야한다. seaborn은 보통 'sns'로 import 한다.
# import seaborn
import seaborn as sns
#seaborn이 설치되어 있지 않은 경우
%pip install seabornseaborn은 매우 다양한 그래프들을 표현할 수 있다. seaborn tutorial만 보더라도 seaborn이 수많은 그래프를 효과적으로 표현하는 것을 볼 수 있다.
seaborn tutorial:
대표적으로 쓰이는 categorical plot, lmplot, joint plot 정도를 알아보도록 하자. 더 다양한 그래프는 seaborn tutorial을 통해 쉽게 알 수 있으니 한 번씩 꼭 보도록 하자.
1. Categorical plot
categorical plot은 범주형 데이터와 수치형 데이터의 관계를 시각화할 수 있는 그래프다. categorical plot은 catplot 함수를 이용하여 만들 수 있고 catplot의 파라미터는 다음과 같다.
seaborn.catplot(data=None, *, x=None, y=None, hue=None, row=None, col=None, kind='strip', estimator='mean', errorbar=('ci', 95), n_boot=1000, units=None, seed=None, order=None, hue_order=None, row_order=None, col_order=None, col_wrap=None, height=5, aspect=1, log_scale=None, native_scale=False, formatter=None, orient=None, color=None, palette=None, hue_norm=None, legend='auto', legend_out=True, sharex=True, sharey=True, margin_titles=False, facet_kws=None, ci=, **kwargs)
이제 예시로 항공사별 항공권 가격이 좌석 등급에 따라 어떻게 변화하는지 categorical plot을 통해 확인해보자.
# import Seaborn
import seaborn as sns
sns.catplot(y='airline', x='price', col='class', data=df)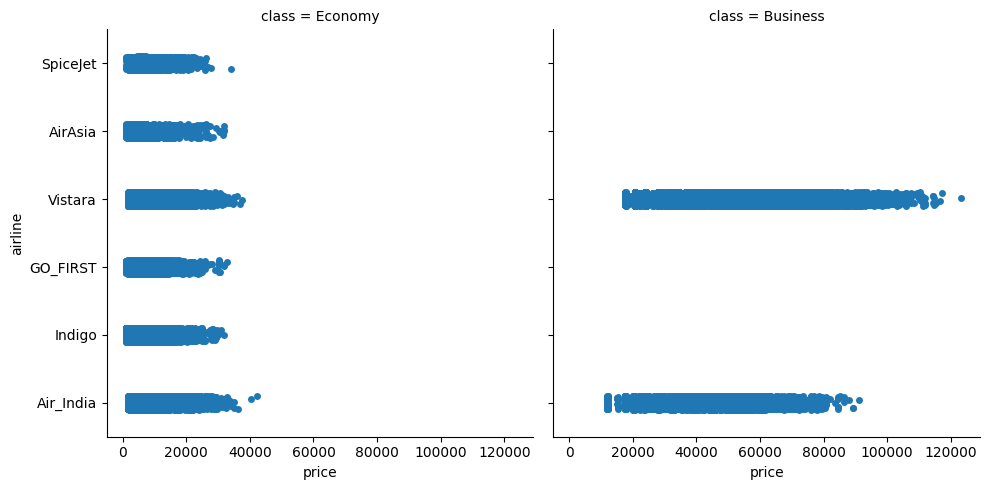
위 그래프를 통해 오직 2개의 항공사(Vistara, Air_india)에서만 Business석을 판매하는 것을 확인할 수 있고 Business의 가격이 Economy보다 2~3배 가량 비싼 것을 확인할 수 있다. 또한 모든 항공사가 Economy의 가격을 40000 이하로 책정하는 것을 알 수 있다.
2. lmplot
linear model plot(lmplot)은 선형회귀(linear regression)모델과 연관성이 있는 그래프다. lmplot은 scatter와 linear를 함께 제공하는 특징이 있다. 일반적인 scatter plot에 linear regression을 함께 제공하여 특성간의 선형적인 관계를 쉽게 파악할 수 있다. 또한 이상치 데이터도 쉽게 파악할 수 있다는 장점이 있다.
lmplot의 파라미터는 다음과 같다.
seaborn.lmplot(data=None, *, x=None, y=None, hue=None, col=None, row=None, palette=None, col_wrap=None, height=5, aspect=1, markers='o', sharex=None, sharey=None, hue_order=None, col_order=None, row_order=None, legend=True, legend_out=None, x_estimator=None, x_bins=None, x_ci='ci', scatter=True, fit_reg=True, ci=95, n_boot=1000, units=None, seed=None, order=1, logistic=False, lowess=False, robust=False, logx=False, x_partial=None, y_partial=None, truncate=True, x_jitter=None, y_jitter=None, scatter_kws=None, line_kws=None, facet_kws=None)
예시로 비행시간과 항공권 가격 간의 선형관계를 파악해보자.
# linear model plot
sns.lmplot(x='duration', y='price', data=df_eco, line_kws={'color':'red'}) 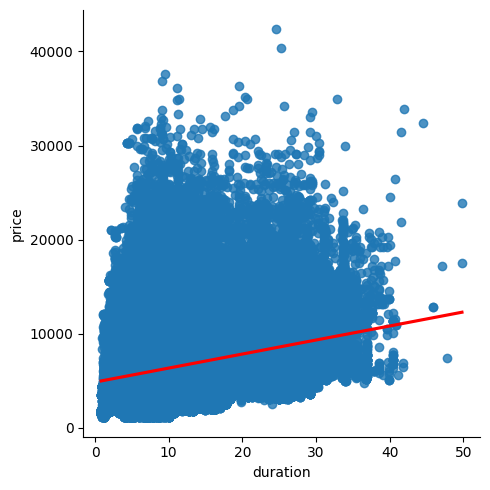
이처럼 산점도와 선형회귀선이 함께 제공되어 특성간의 선형 관계를 쉽게 파악하고 이상치(outlier)도 쉽게 찾을 수 있다.
3. joint plot
joint plot은 scatter와 histogram을 동시에 보여주는 그래프다. 데이터의 분포와 상관관계를 한 눈에 볼 수 있다는 장점이 있지만, 수치형 데이터만 표현할 수 있다는 한계가 있다. joint plot을 사용하면 scatter로 알 수 없는 빈도밀도를 통해 데이터의 분포를 더욱 쉽게 파악할 수 있다. joint plot의 파라미터는 다음과 같다.
seaborn.jointplot(data=None, *, x=None, y=None, hue=None, kind='scatter', height=6, ratio=5, space=0.2, dropna=False, xlim=None, ylim=None, color=None, palette=None, hue_order=None, hue_norm=None, marginal_ticks=False, joint_kws=None, marginal_kws=None, **kwargs)
앞에서 lmplot으로 확인했던 비행시간과 항공권 가격의 관계를 다시 확인해보자.
# joint plot => scatter + hist
sns.jointplot(y='price', x='duration', data=df_eco) 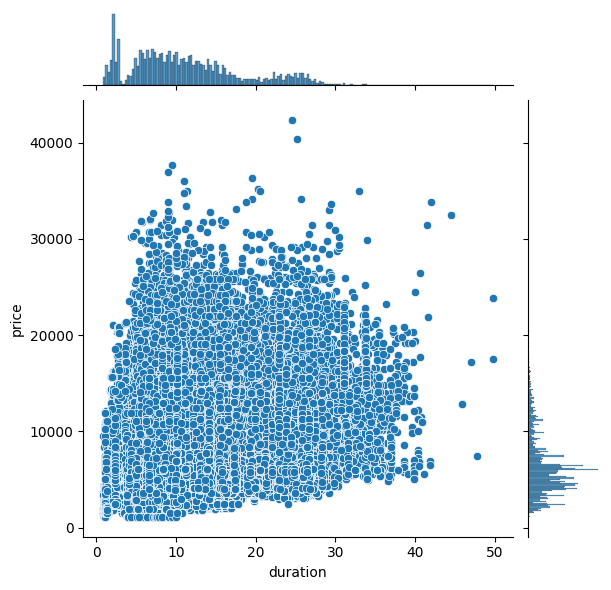
산점도를 통해 항공권 가격과 비행 시간이 양의 상관관계가 성립하는 것을 확인할 수 있다. 빈도밀도를 통해 비행시간이 대부분 0~20 사이에 분포하며 항공권 가격은 대부분 10000 이하에 분포하는 것을 알 수 있다. 이처럼 joint plot을 사용하면 많은 양의 데이터 분포를 쉽게 확인할 수 있다.
대표적으로 사용되는 3가지 plot들을 확인해봤다. seaborn의 함수들에는 수많은 파라미터가 존재하고, 이를 적절하게 사용되면 데이터의 특성을 더욱 알아보기 쉽게 표현할 수 있다. 위에서 설명한 plot 말고도 다양한 plot이 seaborn을 통해 표현되니 tutorial을 보며 하나씩 직접 해보길 권한다. 중요한 파라미터들을 이해하는 것도 데이터를 시각화하는 데에 큰 도움이 될 것이다.
