우리가 데이터 분석에 활용할 데이터를 보면, 대부분의 데이터가 정제되어 있지 않을 것이기에 전처리를 통해 불필요한 데이터를 직접 처리해야하는 경우가 많다. 우리가 흔히 데이터 전처리하는 경우는 결측치와 이상치를 처리하는 것이다. 이번 시간에는 결측치를 처리하는 방법에 대해 집중적으로 알아보겠다.
결측치란 데이터에 값이 없는 것을 의미한다. 쉽게 데이터가 존재하지 않는다고 보면 된다. 결측치는 데이터를 수집할 때 누락하거나 데이터가 유실되는 경우가 발생한다. 그래서 결측치는 데이터 분석이나 모델링 과정에 부정적인 영향을 끼칠 수 있기에 데이터 전처리 과정에서 미리 처리해줘야한다. 결측치는 보통 N/A, NULL, NaN 등의 표기로 쓰이는데 파이썬에서는 NaN으로 쓰인다.
데이터를 확인할 때 결측치가 존재하는지, 존재한다면 얼마나 있는지, 처리 방법은 무엇인 지 알아볼 것이다.
1. 결측치 파악하기
결측치가 데이터에 존재하는지 파악하는 방법은 데이터의 정보를 확인하는 것이다. info 메소드를 통해 데이터프레임의 다양한 정보를 한 눈에 볼 수 있는데, null value가 얼마나 있는지도 확인할 수 있다.
우리가 이번에 사용할 데이터는 '항공권 가격 예측 데이터(Flight Price Prediction)'인데 이 데이터는 결측치가 존재하지 않아서 임의로 결측치를 만들어 줄 것이다. 인덱스 범위 내에서 5000개의 랜덤한 결측치를 생성하여 결측치 여부를 파악해보겠다.
import pandas as pd
import numpy as np
import random
# 데이터 불러오기
df = pd.read_csv("Clean_Dataset.csv", encoding="cp949")
# 첫번째 컬럼이 지정 인덱스이기에 제거해주기
df.drop([df.columns[0]], axis=1, inplace=True)
# 같은 결과를 출력하기 위해 seed 고정
random.seed(2023)
np.random.seed(2023)
# 랜덤한 위치에 결측치 5,000개를 포함한 데이터 df_na 생성하기
df_na = df.copy()
for i in range(0,5000):
df_na.iloc[random.randint(0,300152), random.randint(0,10)] = np.nan
# 0부터 3000152 자리에 랜덤하게 0부터 10의 값을 5000개 생성
# 결측치 처리 여부 확인을 위한 1번, 3번 인덱스 전체 결측치 처리하기
df_na.iloc[1]=np.nan
df_na.iloc[3]=np.nan
# 데이터 정보 확인
df_na.info()
# info를 통해 결측치 여부만 파악하고 구체적인 수는 다른 방법을 사용하는게 효과적임.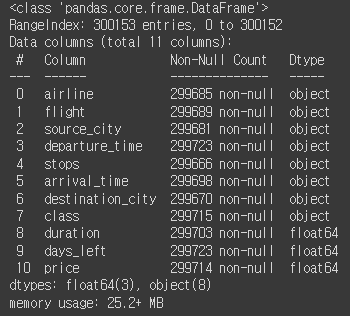
임의의 결측치 5000개를 생성하고 info 메소드를 사용하여 데이터프레임의 정보를 확인해보았다. 전체 인덱스의 개수는 300153개인데, 컬럼들의 데이터 개수를 보면 더 적은 것을 확인할 수 있다. 다만 구체적으로 결측치가 몇개인지는 파악하기 힘드므로 info 메소드를 통해 결측치의 여부만 파악하고 구체적인 개수는 다른 방법을 사용하는 것이 효과적이다.
결측치 수 확인하기
df_na.isna().sum(axis=0)
# isna 대신 isnull 사용 가능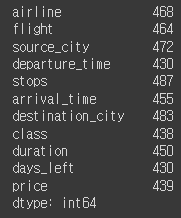
isna 메소드를 사용하면 컬럼별로 결측치의 개수를 한 눈에 파악할 수 있다. isna는 결측치가 있는가?를 물어보는 것이라서 결과값이 Boolean(True or False) 형태인데, sum()을 써주면서 True의 개수를 파악하는 원리다.
2. 결측치 제거하기
결측치를 처리하는 방법 중 하나는 결측치를 제거하는 것이다. 결측치가 포함된 인덱스를 제거할 수도 있고, 컬럼을 제거할 수도 있다. 다만 결측치를 제거하는 방법은 데이터가 손실될 우려가 있기에 상황에 맞게 사용해야한다. 결측치를 제거하는 방법은 결측치의 비중이 적을 때 사용하는 것이 좋다.
# 데이터 변경을 위해 원본 데이터 복사
df_na_or = df_na.copy()# 결측치가 하나라도 있는 모든 행 제거(단점: 데이터 손실이 많을 수 있다.)
df_na = df_na.dropna()
df_na.info()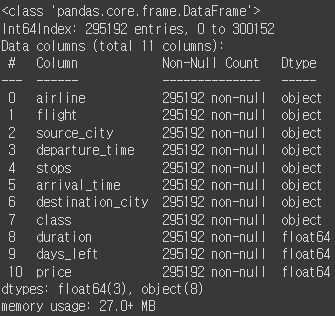
전체 데이터가 300,152인데 결측치 제거 후가 295,192개이므로 4,961개의 데이터가 제거된 것을 확인할 수 있다. dropna를 사용하면 결측치를 아주 간단하게 제거할 수 있지만, 최대한의 데이터 손실을 감안해야한다. 데이터 손실을 최소화하기 위해 'how'와 'thresh' 파라미터를 사용할 수 있다. how 파라미터의 기본값은 'any'인데, 'all'로 바꾸면 모든 데이터가 결측치인 행만 제거한다. thresh는 결측치가 아닌 컬럼의 수를 보장한다.
# 결측치 삭제하기 전 원래 데이터 가져오기
df_na = df_na_or.copy()
# 모든 데이터가 결측값인 행만 제거하기
df_na.dropna(how='all')
df_na.info()다음은 결측치가 있는 컬럼을 완전히 제거하는 방법이다. 특정 컬럼에 결측치가 너무 많은 경우에는 데이터 분석에 악영향을 끼칠 수 있어 제거하는 것이 좋다. 보통 결측치 비율이 50% 이상인 경우 컬럼 제거를 고려하는 경향이 있다. 다만, 결측치가 많다고 무조건 제거하는 것이 아니라 데이터 모델링에 있어 컬럼의 중요성을 따져보고 결정하는 것이 중요하다.
# 결측치가 일정 비율 이상인 경우, 향후 데이터 분석이나 모델링을 위해 제거하는 것이 효과적임.(대략 50% 고려)
# 데이터 초기화
df_na = df_na_or.copy()
# stops와 flight 컬럼 제거
df_na = df_na.drop(['stops', 'flight'], axis=1)
df_na.info()3. 결측치 대체하기
결측치를 처리하기에 가장 이상적인 방법은 결측치를 특정값으로 대체하는 것이다. 평균값, 최빈값, 중간값 대체를 보편적으로 많이 사용하지만 더욱 정확하게 대체 하기 위해서는 예측된 값으로 대체하는 것이 좋다. regression을 사용할 수도 있고, 시계열 데이터를 사용할 수도 있다. 다만, 어떤 값을 대체해도 데이터의 오차가 발생할 수 있다는 것을 염두에 두어야한다. 또한 너무 많은 값을 같은 값으로 대체하면 데이터의 편향이 발생할 수 있으므로 유의해야한다.
평균값 대체를 예시로 해보자.
# 결측치를 제거하는 것은 데이터 손실의 우려가 있어서 데이터를 대체하는게 일반적임
# 주로 평균값, 최빈값, 중간값 대체를 많이 사용하지만, 같은 값을 많이 대체하면 데이터 편향이 생길 수 있음
# 데이터 초기화
df_na = df_na_or.copy()
df_na=df.fillna(df_na.mean())
df_na.head()결측치를 근처에 있는 값으로 대체하는 방법도 있다. fillna의 method 파라미터를 사용하면 된다. method 파라미터에 사용할 수 있는 값은 두 가지가 있는데, ffill과 bfill이 있다.
ffill은 이전 인덱스의 값으로 대체하는 것이고, bfill은 다음 인덱스의 값으로 대체하는 것이다.
# 결측치를 근처의 값으로 대체하는 방법
# ffill -> 이전 인덱스의 값
# bfill -> 다음 인덱스의 값
df_na=df_na.fillna(method='bfill')
df_na.info()