앞에서 결측치를 처리하는 방법에 알아봤다. 이번엔 이상치를 처리하는 방법에 대해 알아보자.
이상치(outlier)는 보통 관측된 데이터의 범위에서 많이 벗어난 작거나 큰 값을 의미한다. 예를들어 전국민의 평균 연봉을 파악한다고 가정해보자. 우리가 원하는 값은 보편적으로 국민들의 소득이 어느정도 되는지 파악하고 싶은 것이다. 이때 상위 5%와 하위 5%가 너무 크고 작은 값이라면 데이터 분석에 부정적인 영향을 끼치지 않겠는가? 5000만원의 연봉이 평균 연봉이라면 연봉이 100억 사람의 데이터는 우리가 원하는 값을 도출하는데 있어 매우 불필요한 데이터가 되는 것이다. 이처럼 이상치는 데이터 분석이나 모델링을 할 경우 의사결정에 큰 영향을 끼칠 수 있기 때문에 데이터 전처리 과정에서 꼭 처리해줘야 한다. 다만, 데이터의 범위를 벗어났다는 기준이 애매하기 때문에 이상치를 탐지하는 몇가지 방법을 알아보도록 하자.
1. 특정 추세를 벗어난 데이터
특정 추세를 벗어난 데이터는 시각화를 통해 확인해보는 것이 좋다. scatter plot으로 보통 확인하며 seaborn의 lmplot, joint plot 등을 사용할 수도 있다.
2. 중앙값을 크게 벗어난 데이터
중앙값을 크게 벗어난 데이터는 IQR(Interquartile Range, 75%-25%)로 확인한다. boxplot을 사용하면 쉽게 확인할 수 있다.
1. 이상치 탐지하기
1) Standard distribution(z-score)
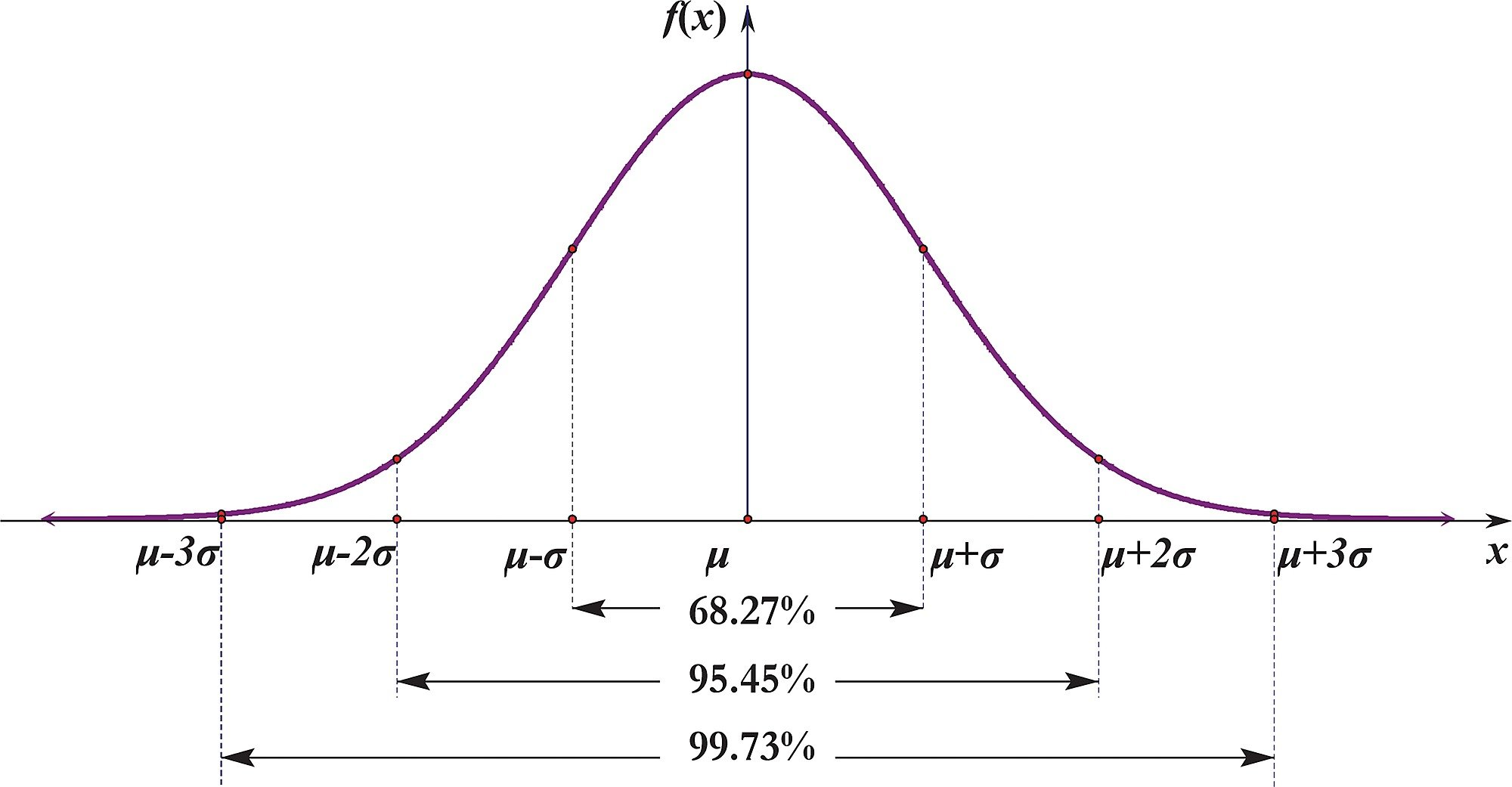
z-score :
신뢰구간을 통해 이상치를 탐지할 수 있다. 신뢰구간은 모수가 실제로 포함될 것이라고 예측되는 범위를 뜻하는데, 신뢰구간에 모집단의 실제 평균값이 포함될 확률을 신뢰 수준이라고 한다.
Z-score는 해당 데이터가 평균으로부터 얼마의 표준편차만큼 벗어나 있는 지를 의미한다. 일반적으로 95% 신뢰수준을 사용하기 때문에 'Z-score 1.96'을 기준으로 이상치를 확인해보자.
# 이상치(z-score)
df[(abs((df['price']-df['price'].mean())/df['price'].std()))>1.96]
2) IQR(Inter Quartile Range)
IQR은 Q3(75%)에서 Q1(25%)를 뺀 값이다. IQR을 사용하여 이상치를 판단하는 기준은 다음과 같다.
보다 작거나, 보다 크거나.
# IQR 기준 이상치 확인하는 함수 def findOutliers(x,column): q1 = x[column].quantile(0.25) q3 = x[column].quantile(0.75) iqr = q3 - q1 y = x[(x[column] > (q3 + 1.5*iqr)) | (x[column] < (q1 - 1.5*iqr))] return len(y) # price, duration, days_left에 대하여 IQR 기준 이상치 개수 확인 print("price IQR outliers: ",findOutliers(df,'price')) print("duration IQR outliers: ",findOutliers(df,'duration')) print("days_left IQR outliers: ",findOutliers(df,'days_left'))
price IQR outliers: 123
duration IQR outliers: 2110
days_left IQR outliers: 0
import matplotlib.pyplot as plt
plt.figure()
# first subplot : 1행 5열로 나눈 영역에서 첫 번째 영역
plt.subplot(151)
df[['duration']].boxplot()
plt.ylabel('duration')
# second subplot : 1행 5열로 나눈 영역에서 세 번째 영역
plt.subplot(153)
df[['days_left']].boxplot()
plt.ylabel('Days')
# third subplot : 1행 5열로 나눈 영역에서 다섯 번째 영역
plt.subplot(155)
df[['price']].boxplot()
plt.ylabel('price')
plt.show()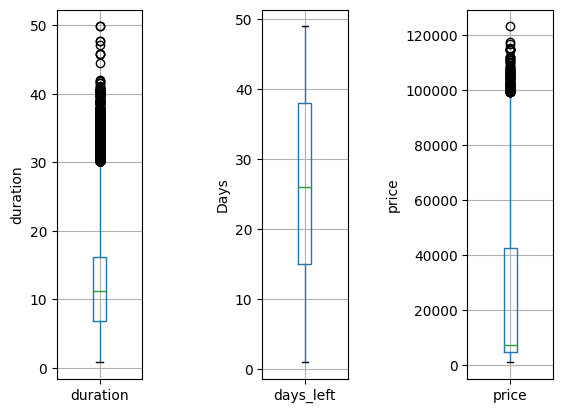
boxplot을 통해 duration과 price에 이상치가 존재하는 것을 쉽게 확인할 수 있다.
2. 이상치 처리하기
이상치도 결측치처럼 제거할 수도 있고 대체할 수도 있다. 삭제하는 경우에는 데이터 손실을 감안해야 하고, 대체하는 경우에는 데이터의 변형을 고려해야 한다.
1) 이상치 데이터 삭제하기
# 신뢰도 95% 기준 이상치 Index 추출
outlier = df[(abs((df['price']-df['price'].mean())/df['price'].std()))>1.96].index
# 추출한 인덱스의 행을 삭제하여 clean_df 생성
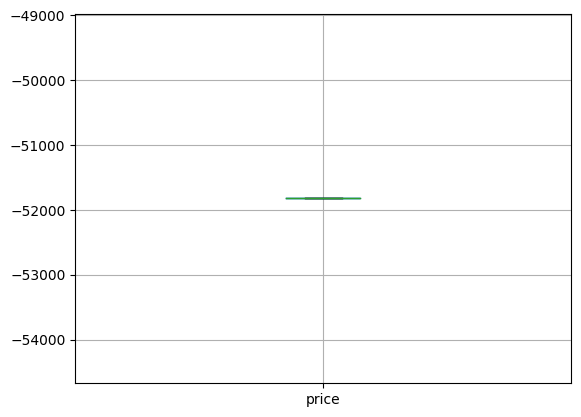
clean_df = df.drop(outlier)plt.figure()
# boxplot
clean_df[['price']].boxplot()
plt.show()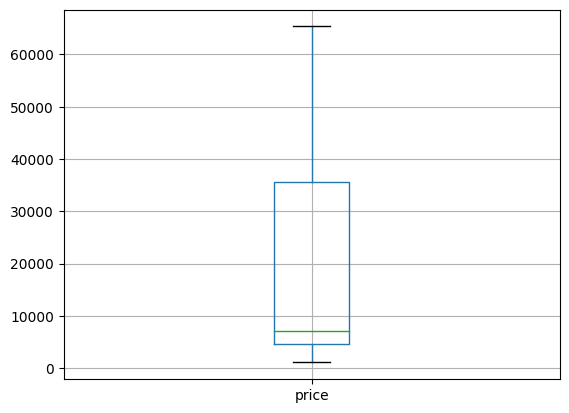
이상치를 제거하기 전 'price'의 boxplot과 비교해보면 이상치가 모두 제거된 것을 확인할 수 있다.
2) 이상치 대체하기
이상치를 대체하는 방법 중 하나는 상한값과 하한값으로 대체하는 것이다. Max보다 큰 값을 Max로, Min보다 작은 값을 Min으로 대체하는 것이다.
# IQR 기준 이상치 확인하는 함수
def changeOutliers(x,column):
q1 = x[column].quantile(0.25)
q3 = x[column].quantile(0.75)
iqr = q3 - q1
# 이상치를 대체할 Min, Max 설정
Min = q1 - 1.5*iqr
Max = q3 + 1.5*iqr
# Max 보다 큰 값을 Max로 , Min보다 작은 값을 Min으로 대체
x.loc[(x[column] > Max), column] = Max
x.loc[(x[column] > Min), column] = Min
return(x)
# price에 대하여 이상치 대체하기
clean_df = changeOutliers(df,'price')
# price에 대하여 IQR 기준 이상치 개수 확인
print("Price IQR Outliers: ", findOutliers(clean_df,'price'))Price IQR Outliers: 0
plt.figure()
clean_df[['price']].boxplot()
plt.show()