데이터를 전처리 하는 과정에서 수치형 데이터를 처리하는 것도 중요하지만, 범주형 데이터를 처리하는 것도 중요하다. 실제로 많은 데이터를 살펴보면 범주형 데이터의 비율이 꽤 많은 것을 확인할 수 있다. 특히 데이터로 통계를 낼 때, 범주형 데이터를 전처리 해주는 과정이 꼭 필요하다.
컴퓨터는 인간과 다르게 문자를 잘 인식하지 못하고 숫자를 쉽게 인식하는 특성이 있다. 예를 들어 남자와 여자를 구분 지을 때, 데이터가 남/여로 구분되기 보다는 남자는 1, 여자는 0과 같이 숫자로 표기될 때 컴퓨터가 쉽게 남자와 여자를 구분지을 수 있다. 즉, 컴퓨터가 데이터를 잘 이해할 수 있도록 범주형 데이터(Categorical Data)를 수치형 데이터(Numeric Data)로 변경해주는 과정을 범주형 인코딩(Categorical Encoding)이라고 한다.
1. 레이블 인코딩
레이블 인코딩은 범주형 데이터에서 숫자 레이블을 할당한다. 숫자 레이블을 할당할 때, 범주를 알파벳순으로 정렬한 뒤 그것을 기준으로 번호를 매긴다.
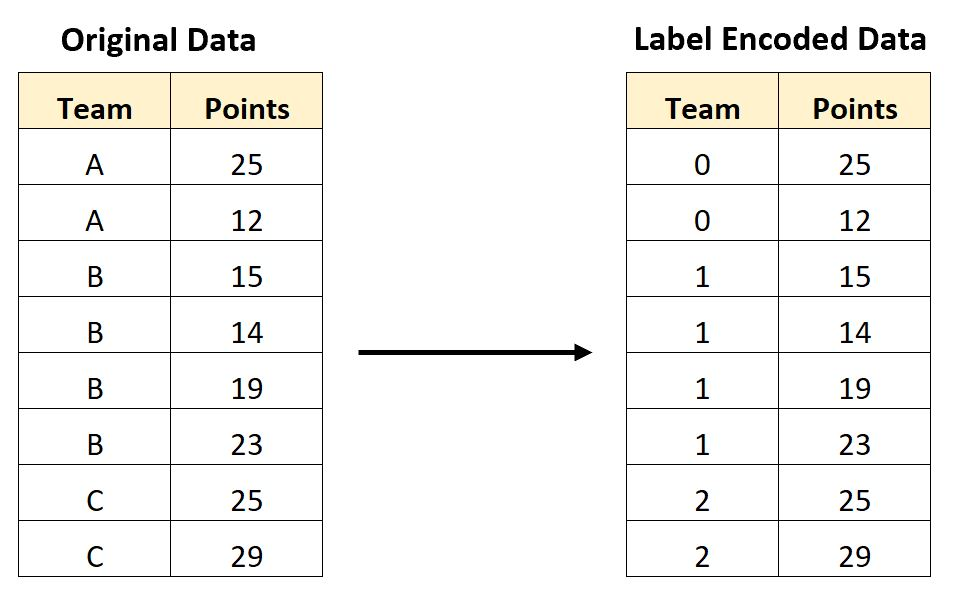
레이블 인코딩은 판다스와 사이킷런을 활용할 수 있다.
1) 판다스로 레이블 인코딩하기
판다스에서는 알파벳순이 아닌, 인덱스를 기준으로 번호를 매긴다. 레이블 인코딩을 하는 함수는 Facorize다. Factorize는 결과값이 tuple값을 반환하기 때문에, 데이터프레임의 새로운 컬럼을 만들기 위해서 array로 변경하고, reshape하여 새로운 컬럼으로 만들어야 한다.
# factorize 메소드로 airlin column label encoding
df['label_encoding'] = pd.factorize(df['airline'])[0].reshape(-1,1)
# reshape에서 -1의 의미는 추정이다. 남은 배열의 길이와 남은 차원으로부터 알아서 행을 지정해준다.
df.head()
결과값을 보면 airline이 SpiceJet, AirAsia, Vistara 순으로 정렬되어 있으므로 레이블 인코딩의 값도 이 순서대로 0, 1, 2로 인코딩 된 것을 확인할 수 있다. 이처럼 판다스는 인덱스를 기준으로 레이블 인코딩을 진행한다.
print(df['airline'].value_counts())
print(df['label_encoding'].value_counts())Vistara 127859
Air_India 80892
Indigo 43120
GO_FIRST 23173
AirAsia 16098
SpiceJet 9011
Name: airline, dtype: int64
2 127859
5 80892
4 43120
3 23173
1 16098
0 9011
Name: label_encoding, dtype: int64
2) 사이킷런으로 레이블 인코딩하기
사이킷런(sckit-learn)은 머신러닝 분석을 할 때 유용하게 사용되는 라이브러리다. 사이킷런의 라이브러리는 sklearn으로 표기된다. 레이블 인코딩을 할 때는 LabelEncoder를 활용하면 된다.
# sckit-learn으로 label encoding
from sklearn.preprocessing import LabelEncoder
# LabelEcoder로 airline label encoding
le = LabelEncoder()
df["airline_Label_Encoder"] = le.fit_transform(df['airline'])
df.head()
사이킷런은 판다스와 다르게 알파벳순으로 레이블 인코딩이 진행되었다.
scikit-learn을 사용하여 레이블 인코딩을 한 경우에는 기존의 데이터로 역변환할 수도 있다.
# 레이블 인코딩 역변환(디코딩)하기
le.inverse_transform(df["airline_Label_Encoder"]).reshape(-1,1)
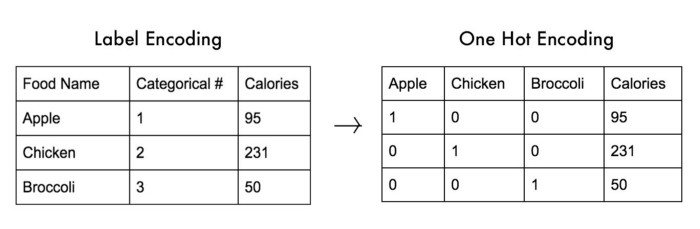
2. 원핫 인코딩
레이블 인코딩을 하면 순서나 랭크가 없는 범주형 데이터가 알파벳순이나 인덱스순으로 인코딩 되기 때문에 생성된 숫자 정보가 모델에 잘못 반영될 수 있다는 단점이 있다. 이를 해결할 수 있는 것이 원핫 인코딩(OneHotEncoding)이다. 원핫 인코딩은 1개의 요소는 True, 나머지 요소는 False로 만들어서 결과적으로 0과 1로만 존재한다. 원핫 인코딩도 판다스와 사이킷런을 활용할 수 있다.
다만 원핫 인코딩은 범주형 데이터의 종류가 늘어날 수록 벡터의 차원이 무수히 커진다는 단점이 있다. 또한 단어의 유사도를 표현하지 못한다는 한계가 존재한다.
1) 판다스로 원핫 인코딩하기
판다스의 get_dummies() 메소드를 사용하면 쉽게 원핫 인코딩을 진행할 수 있다.
# class 칼럼을 원핫 인코딩 하기
pd.get_dummies(df['class'])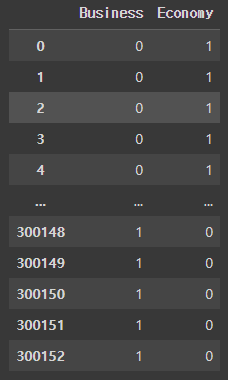
# 원핫 인코딩 결과를 데이터에 반영하기
df = pd.get_dummies(df, columns=['class'])
df.head()
2) 사이킷런으로 원핫 인코딩하기
사이킷런의 레이블 인코딩과 비슷한 방식이다. 레이블 인코딩은 LabelEncoder를 사용했지만 원핫 인코딩은 OneHotEncoder를 사용한다. 다만, 판다스의 get_dummies처럼 데이터프레임에 바로 반영할 수 없어서 원핫 인코딩을 진행한 후 데이터를 추가하기 위해 컬럼을 새로 만들고 추가하는 과정이 필요하다.
# sklearn
from sklearn.preprocessing import OneHotEncoder
# one hot encoding
oh = OneHotEncoder()
encoder = oh.fit_transform(df['class'].values.reshape(-1,1)).toarray()
# 원핫 인코딩 결과를 데이터프레임으로 만들기
df_Onehot = pd.DataFrame(encoder, columns=["Class_" + str(oh.categories_[0]
[i]) for i in range(len(oh.categories_[0]))])
# 원핫 인코딩 결과를 원본 데이터에 붙여넣기
df1 = pd.concat([df,df_Onehot], axis=1)
df1.head()
