데이터 모델링을 진행할 때 각 특성별로 스케일이 다르면 모델링 결과가 달라질 수 있어서 사전에 꼭 데이터 스케일링을 진행해줘야 한다. 예를 들어 특성 A와 B를 사용하여 모델링을 진행할 때, 특성 A의 스케일이 0~1,000이고, 특성 B의 스케일이 0~10이라면, 컴퓨터는 각 특성이 무엇을 의미하는 지 모르기에 특성 A의 영향을 더 크게 받는다. 따라서 수치형 데이터(Numeric Data)의 경우에는 각 특성의 스케일의 크기 차이를 제거할 필요가 있다.
이번에 소개할 데이터 스케일링의 종류는 5가지다.
- Standard Scaler
- Min-Max Scaler
- MaxAbs Scaler
- Robust Scaler
- Normalizer
1. Standard Scaler
Standard Scaler는 평균(mean)을 제거하고 단위 분산(unit variance)으로 조정한다. 각 특성의 평균을 0, 분산을 1로 스케일링 한다. Standard Scaler는 Min, Max를 따로 제한하지 않아서 이상치가 큰 데이터에는 취약하기 때문에 꼭 이상치를 제거해줘야 한다. regression 보다는 classification에 유용하다.
# 수치형 데이터로만 데이터프레임 구성
df_num = df[['duration', 'days_left', 'price']]
from sklearn.preprocessing import StandardScaler
standardScaler = StandardScaler()
print(standardScaler.fit(df_num))
df_standardScaled = standardScaler.transform(df_num)
df_standard = pd.DataFrame(df_standardScaled, columns=['duration', 'days_left', 'price'])
df_standard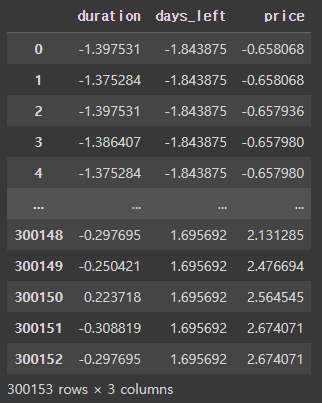
2. MinMax Scaler
MinMax Scaler는 각 특성이 0과 1 사이에 위치하도록 스케일링한다. 최댓값이 1이고, 최솟값이 0이 되는 것이다 . MinMax Scaler는 특성의 최댓값과 최솟값을 기준으로 스케일링 하므로 극단적인 이상치 값에 매우 취약하다. 그래서 꼭 이상치를 제거해주는 과정을 거쳐야한다.
df_num = df[['duration', 'days_left', 'price']]
from sklearn.preprocessing import MinMaxScaler
minMaxScaler = MinMaxScaler()
print(minMaxScaler.fit(df_num))
df_minMaxScaled = minMaxScaler.transform(df_num)
df_minmax = pd.DataFrame(df_minMaxScaled, columns=['duration', 'days_left', 'price'])
df_minmax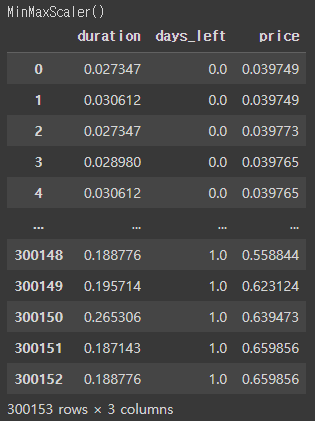
3. MaxAbs Scaler
MaxAbs Sclaer는 절댓값이 0과 1사이에 위치하도록 스케일링한다. 즉, -1부터 1 사이로 조정한다. 만약 모든 데이터가 양수인 경우에는 MinMax Scaler와 동일하게 작동한다. 이 또한 극단적인 이상치에는 민감할 수 있으므로 꼭 이상치를 제거하도록 하자.
df_num = df[['duration', 'days_left', 'price']]
from sklearn.preprocessing import MaxAbsScaler
maxAbsScaler = MaxAbsScaler()
print(maxAbsScaler.fit(df_num))
df_maxAbsScaled = maxAbsScaler.transform(df_num)
df_maxabs = pd.DataFrame(df_maxAbsScaled, columns=['duration', 'days_left', 'price'])
df_maxabs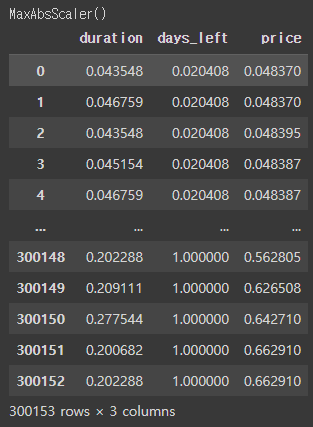
4. Robust Scaler
Robust Scaler는 다른 스케일러와 다르게 평균과 분산 대신 사분위수(Quartile)를 사용한다. 즉, 중앙값과 IQR(InterQuartile Range)를 사용하기 때문에 이상치의 영향을 최소화 시킨다.
df_num = df[['duration', 'days_left', 'price']]
from sklearn.preprocessing import RobustScaler
robustScaler = RobustScaler()
print(robustScaler.fit(df_num))
df_robustScaled = robustScaler.transform(df_num)
df_robust = pd.DataFrame(df_robustScaled, columns=['duration', 'days_left', 'price'])
df_robust
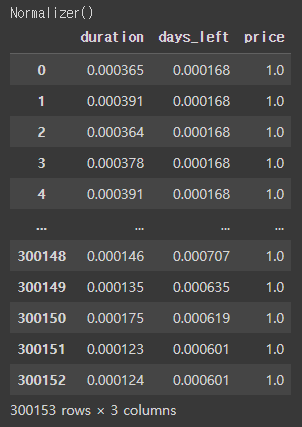
5. Normalizer
Normalizer는 위에서 본 4가지 스케일러들과 다른 특성을 가진다. 앞의 4가지 방법은 각 featrue의 통계치를 이용한다. 즉 column을 기준으로 진행한다. 반면에 Normalizer는 row를 기준으로 row(data point)마다 정규화를 진행한다. 이러한 방식은 한 행의 모든 features 사이에 유클리드 거리가 1이 되도록 데이터를 만들어준다. Normalizer를 사용하면 학습 속도도 빨라지고 과대적합 확률을 낮출 수 있다.
df_num = df[['duration', 'days_left', 'price']]
from sklearn.preprocessing import Normalizer
norm = Normalizer()
print(norm.fit(df_num))
df_normScaled = norm.transform(df_num)
df_norm = pd.DataFrame(df_normScaled, columns=['duration', 'days_left', 'price'])
df_norm