EDA란 무엇인가
데이터 분석을 시작하는 과정에서 가장 중요한 것은 데이터를 이해하는 것이다. 데이터를 이해하지 못한 상태에서는 데이터 분석의 방향성을 잡기 어렵고 잘못된 방식으로 데이터 분석을 진행하여 결국 원점으로 돌아오게 될 수도 있다. 그래서 우리는 데이터를 탐색하고 이해하는 과정을 가져야 한다. 탐색적 데이터 분석(EDA, Exploratory Data Analysis)을 통해 데이터를 탐색하고 이해할 수 있다. EDA를 통해 어떤 컬럼을 분석할 지, 어떤 특성을 제거할 지 등의 데이터 정제 방향을 결정할 수 있고, 시각화와 통계값을 통해 데이터의 분포를 한 눈에 파악할 수 있다. 지표와 시각화를 통해 EDA 하는 방법을 알아보도록 하자.
지표로 데이터 탐색하기
1) describe
수학적 통계 정보를 통해 데이터의 분포를 쉽게 파악할 수 있다. pandas의 describe 함수는 데이터의 요약 통계를 보여준다. describe 함수는 count, mean, std, min, 25%, 50%, 75%, max를 대표적으로 보여준다.
# 기초 통계량 확인
df.describe()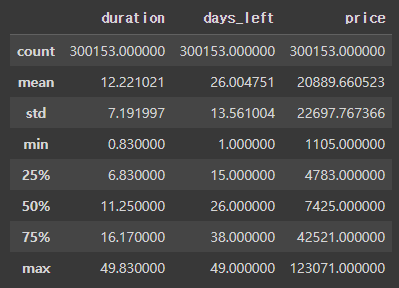
이처럼 수치형 데이터들의 요약 통계값을 확인할 수 있다. 문자형 또는 범주형 데이터의 통계값을 확인하려면 describe 함수의 include 파라미터를 사용해야 한다.
# include 파라미터를 사용하여 범주형 데이터의 기초 통계량까지 확인 가능
df.describe(include='all')
# unique : 고유한 데이터 수
# top : 최빈값
# freq : 최빈값이 존재하는 개수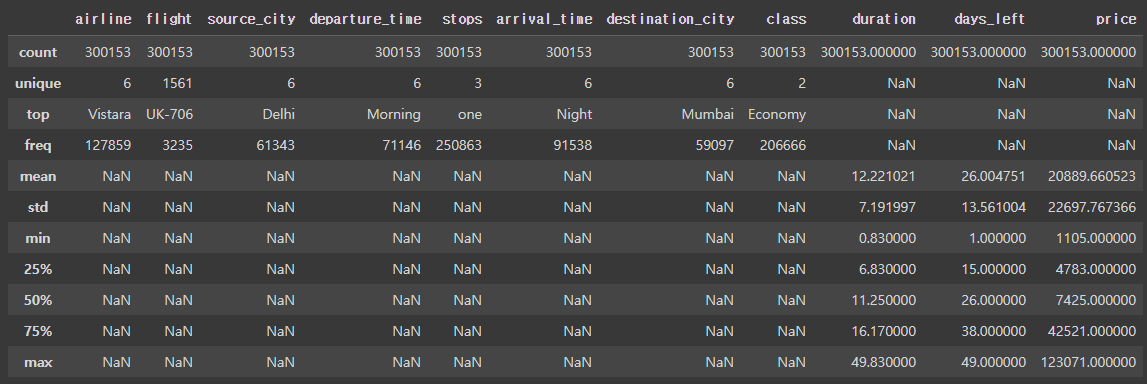
범주형 데이터를 분석하는 경우는 보통 빈도수를 파악하는 경우일 것이다. value_counts() 메소드를 사용하면 각 칼럼의 빈도를 보여주고, 이를 통해 결측값이나 찾고 싶은 데이터를 쉽게 파악할 수 있다.
# 빈도표 확인 -> 범주형 데이터
print(df['airline'].value_counts())
print(df['source_city'].value_counts())
print(df['destination_city'].value_counts())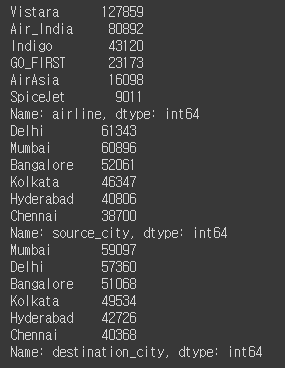
2) Corr
다변량 데이터의 경우는 상관계수를 통해 두 변수가 얼마나 상관관계에 있는 지 파악할 수 있다. 상관관계는 두 변수 간의 선형 상관관계를 계량화한 수치로, -1부터 1까지의 범위를 가진다. -1에 가까울 수록 강한 음의 상관관계를 가지고, 1에 가까울 수록 강한 양의 상관관계를 가진다. 0에 가까울 수록 상관관계가 없는 것이다. 데이터를 분석하는 과정에서 상관관계를 파악하는 것은 매우 중요하다. 변수가 많은 경우에 상관관계를 파악 함으로써 불필요한 변수를 제거하여 모델링을 단순화할 수 있다. 상관계수는 수치형 데이터에만 존재한다.
df.corr()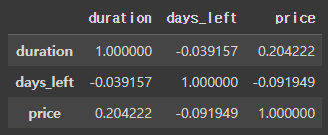
두 범주형 데이터의 상관관계를 파악하기 위해선 교차표를 확인해야 한다. 이때 변수들의 빈도수를 이용하여 연관성을 파악하는데, 검정통계량으로 카이제곱() 통계량을 이용한다.
교차표는 pandas의 crosstab 함수를 사용하면 확인할 수 있다.
# 교차표(범주형데이터 상관관계) -> crosstab
pd.crosstab(df['source_city'], df['departure_time'])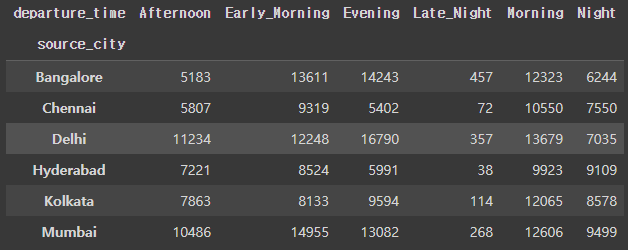
다음 결과를 통해 우리는 Morning에 비행 편수가 많은지, Bangalore의 경우 타 도시에 비해 Afternoon에 비행 편수가 적은지 등을 확인할 수 있다.
시각화로 데이터 탐색하기
시각화는 방대한 양의 데이터를 한 눈에 파악하여 유의미한 특성을 발견하도록 도와준다. 전체적인 데이터의 구조를 시각적으로 파악하여 분석의 방향성을 잡을 수 있고, 잘못된 데이터가 존재하는 지 확인하여 수정할 수 있다. 또한 모델링의 결과를 이해하고 의사 결정에 반영할 수 있도록 도와준다.
파이썬에서는 다양한 시각화 라이브러리가 존재한다. 기본적으로 matplotlib을 가장 범용적으로 사용한다. matplotlib은 line plot, bar plot, pie plot, histogram, box plot, scatter plot 등 통계적으로 기본적은 그래프들을 제공한다.
또 다른 라이브러리는 seaborn 라이브러리다. seaborn은 matplotlib에 의존하지만, 다양한 색상과 통계 기능을 제공한다는 장점이 있다.
우리가 시각화를 진행할 때 가장 중요한 점은 데이터의 특성을 이해하고 어떤 그래프를 그려야할 지 미리 파악해야 한다는 것이다. 예를 들어 시간에 따른 데이터의 흐름을 이해하려고 하는데 pie plot을 그려버린다면 의미 없는 결과가 도출 되지 않을까? 우리의 목적에 맞는 그래프를 아는 능력도 매우 중요하다. 이제 시각화를 matplotlib과 seaborn으로 직접 해보자.
1) matplotlib
matplotlib을 사용하기 위해선 라이브러리를 import 해야한다. import code는
"import matplotlib.pyplot as plt"이다.
matplotlib을 사용할 때는 딱 3가지만 기억하면 된다.
1) figure : 시각화 하는 영역 -> plt.figure()
2) plot : 시각화 내용 -> plt.plot()
3) show : 시각화한 객체 출력 -> plt.show()
다양한 그래프들을 하나씩 살펴보자.
1. line plot
line plot은 시간이나 순서에 따른 데이터의 연속적인 변화량을 관찰할 때 유용하다. 데이터를 점으로 표현한 후 선으로 이은 것이기에 증가와 감소에 대한 상태 변화를 파악할 수 있다. 예시로 데이터를 하나 만들어보자.
# Visualization
days_left = df.groupby('days_left').mean()
days_left.head()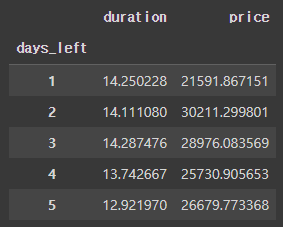
출발까지 남은 일자(days_left)와 가격(price)를 가지고 출발까지 남은 일자에 따른 가격이 어떻게 변화하는지 파악해보자.
import matplotlib.pyplot as plt
plt.figure()
plt.plot(days_left['price'])
plt.xlabel("Days_left") # 가로축 이름
plt.ylabel("Price") # 세로축 이름
plt.show()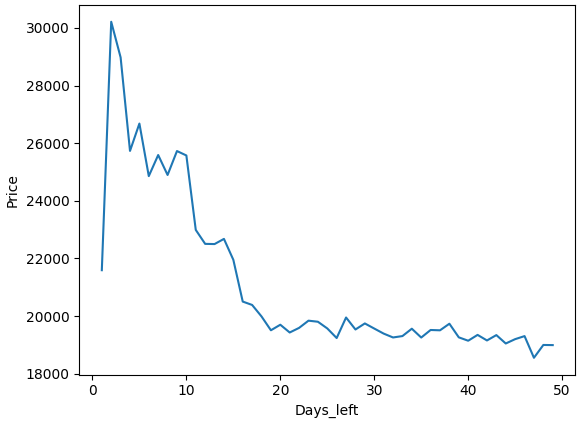
기간이 많이 남을 수록 가격이 저렴하고, 기간이 적게 남을 수록 가격이 비싸지는 것을 파악할 수 있다. 이처럼 line plot은 시간이나 순서에 따른 데이터의 연속적인 변화량을 파악하는 데 유용하다.
2. bar plot
bar plot은 범주에 대한 통계 데이터나 양을 막대 모양으로 나타내는 그래프다. 막대 그래프는 각 항목의 수량을 한 눈에 파악하기 쉽고, 변수 간의 비교가 매우 쉽다. 목적에 따라 가로, 세로, 누적, 그룹화된 막대 그래프를 사용할 수 있다.
막대 그래프를 사용하여 항공사별 평균 항공권 가격을 비교해보자.
airline = df.groupby('airline').mean()
airline.head()
label = airline.index
plt.figure
plt.bar(label, airline['price'])
plt.xlabel('airline')
plt.ylabel('price')
plt.show()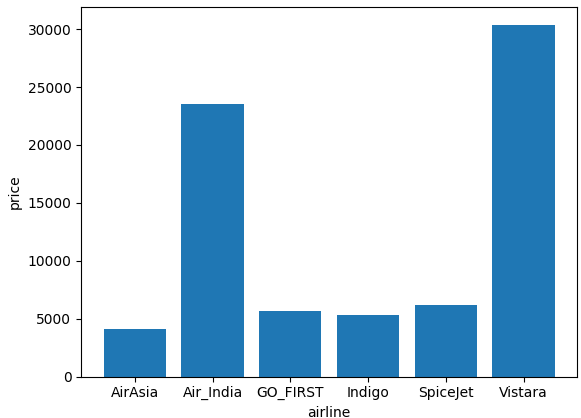
Air_India와 Vistara가 다른 항공사에 비해 가격이 비싼 것을 한 눈에 파악할 수 있다. 이처럼 bar plot은 각 항목의 수량을 한 눈의 파악하고 크고 작음을 비교하는데 매우 유용하다.
3. pie plot
pie plot은 전체에 대한 각 부분의 비율을 부채꼴 모양으로 나타낸 그래프다. 점유율, 투표율, 구성 비율 등을 한 눈에 파악할 수 있다.
이번에는 출발 시간에 따른 비행기 스케줄을 파악해보자.
# pie graph
departure_time = df['departure_time'].value_counts()
plt.figure()
plt.pie(departure_time, labels = departure_time.index, autopct='%.1f%%')
plt.show()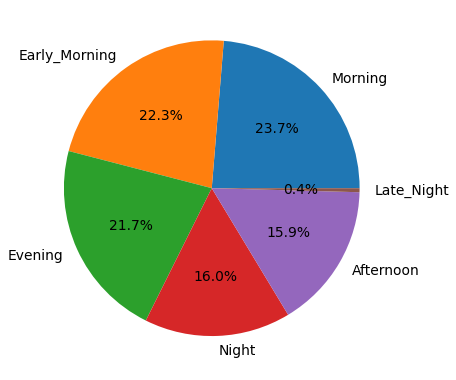
4. histogram
hitsogram은 특정 데이터의 빈도수를 막대 모양으로 표시한 그래프다. histogram은 가장 많인 사용 되는 통계 도구 중 하나다. 데이터의 특성과 분포를 파악하고, 빈도, 빈도밀도, 확률 등의 분포를 그릴 때 사용한다.
목적지까지 소요 시간의 분포를 파악해보자. histogram에서는 bins 파라미터가 중요하다. bins 파라미터를 이용해 x축을 몇 개의 구간으로 나눌 지 정할 수 있다.
#hist
plt.figure
plt.hist(df['duration'], bins=10)
plt.hist(df['duration'], bins=20)
plt.xlabel('duration')
plt.ylabel('flights')
plt.legend(("Bin 10", "Bin 20"))
plt.show()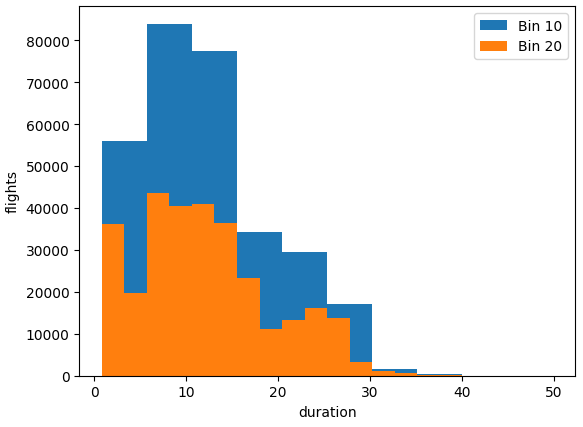
5. box plot
box plot은 사분위수를 중심으로 수치적 요약 통계 자료를 시각화하는 그래프다. box plot에서는 IQR(InterQuartile Range)이 무엇인지 알아야한다. IQR을 통해 box plot의 max와 min을 구할 수 있기 때문이다.
max는 Q3+1.5IQR 이고, min은 Q1-1.5IQR이다. 각각 max와 min을 벗어난 값들은 이상치(outlier)로 취급한다. outlier를 파악함으로써 특정 변수의 통계값이 믿을만한 값인지 파악할 수 있다
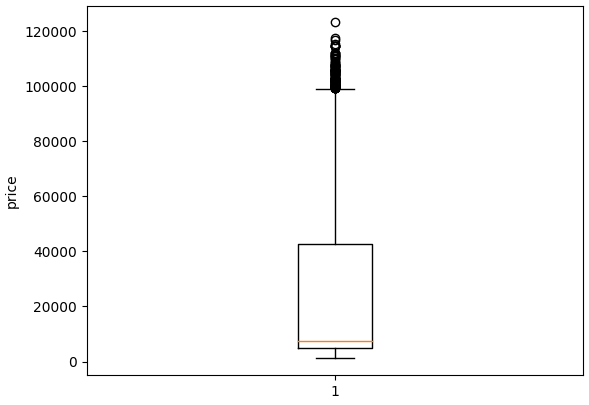
# boxplot
plt.figure()
plt.boxplot(list(df['price']))
plt.ylabel("price")
plt.show()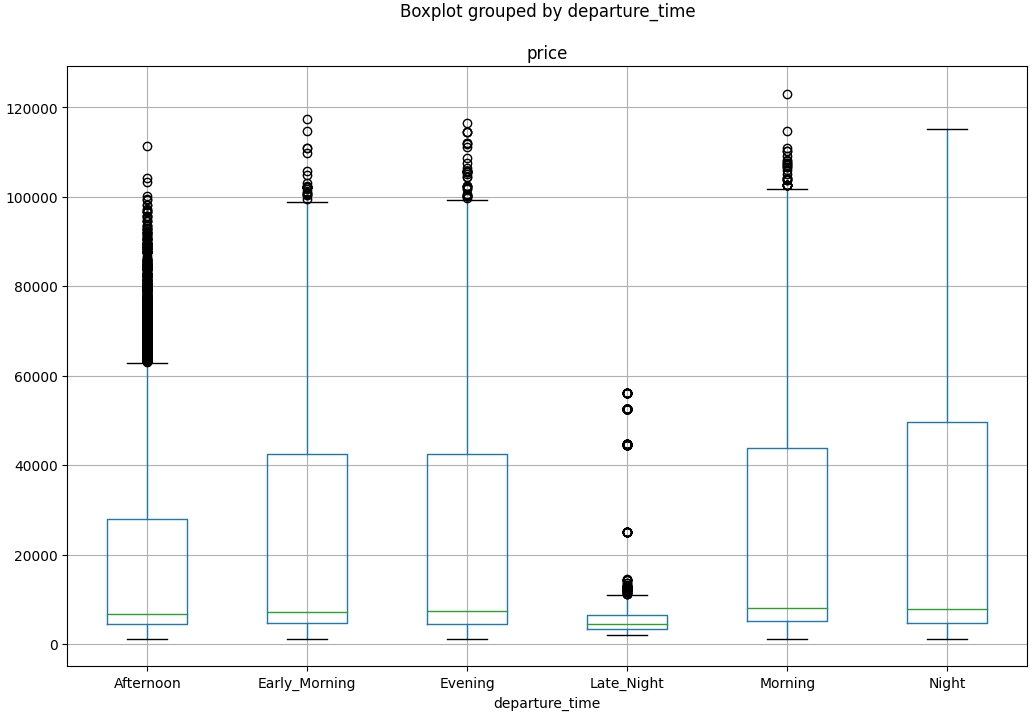
df.boxplot(by='departure_time', column='price', figsize=(12,8))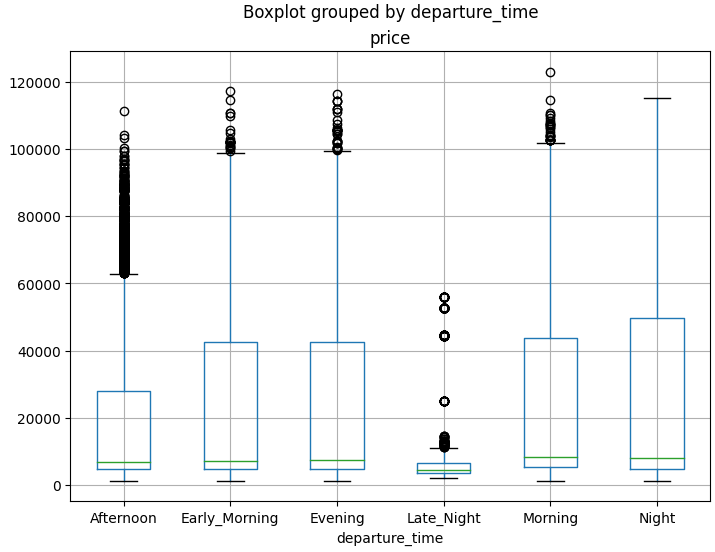
6. scatter plot
산점도(scatter plot)는 2개의 연속형 변수의 관계를 보기 위해 좌표의 X축과 Y축에 표시하는 점들을 찍어서 만드는 그래프다. 산점도에 표기되는 점들은 자료들의 관측값이다. 키와 몸무게 같은 두 변수 간의 상관관계를 확인할 수 있다.
duration과 price의 관계를 파악해보자.
#scatter plot
plt.figure(figsize=(16,8))
plt.scatter(y=df['price'], x=df['duration'])
plt.xlabel('duration')
plt.ylabel('price')
plt.show()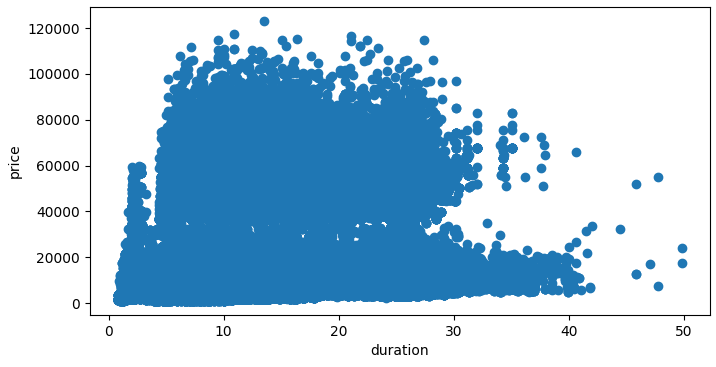
7. heatmap
heatmap은 데이터의 배열을 색상으로 표현해주는 그래프다. 두 값 또는 각 변수 간의 상관관계를 나타낼 때 주로 사용한다. matplotlib에서 heatmap은 plt.pcolor()로 사용한다. 다만, heatmap은 matplotlib 보다는 seaborn 라이브러리를 사용하는 것이 더욱 좋다.
# heatmap
heat = df_eco.corr()
plt.pcolor(heat)
plt.xticks(np.arange(0.5,len(heat.columns),1),heat.columns)
plt.yticks(np.arange(0.5,len(heat.index),1),heat.index)
plt.colorbar()
plt.show()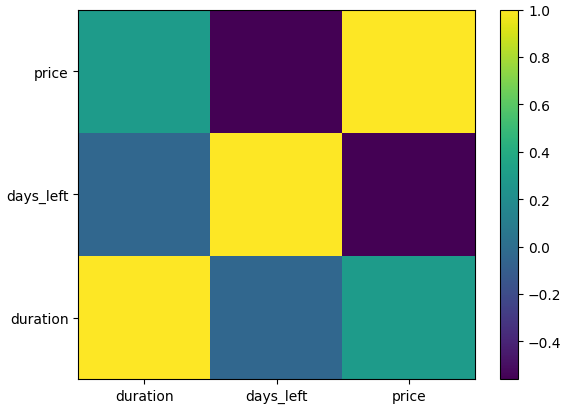
양의 상관관계는 노란색, 음의 상관관계는 보라색, 상관관계가 없을 수록 파란색을 나타낸다.
