
원래 git 에 자료들을 많이 올렸는데, 여기에 조금 더 가독성이 좋게 정리를 해보려고 합니다.
예전에 읽고 싶엇떤 논문이 dirichlet process mixture model 이라는 단어를 중심으로 전개되었습니다. dirichlet process mixture model, 간단하게 이해할 수 있을 줄 알고 구글링을 몇 번 해봤지만 막막하기만 하더라구요.
그런데 또, 아예 이해 못할정도로 다른 세계는 아닌 것 같았습니다. 그래서 파고들어봤더니 bayesian 에 대한 이해부터 새롭게 할 수 있는 좋은 기회가 되더군요.
1. So What is the Bayesian?
bayesian equation
로 기초적인 확률론만 공부한다면 자명합니다만, 식에 담긴 의미가 아주 깊고, 어렵습니다. 대부분의 교과서에 기술된 , 가 아닌 , 를 사용한 이유도 여기 있습니다.
bayesian equation 은 bayesian inference 라는, 세상에서 가장 유명한 통계적 추론 방법을 나타내는 공식입니다. 딱딱한 용어보다는 예시를 통해서 설명하려고 합니다.
맛집의 대기시간
당신은 아주 좋아하는 식당이 있어서 매일 점심 그 식당을 찾아가는, 식당이 너무 맛집이라 항상 줄이 있습니다. 당신은 기다려야하는 시간의 확률 분포를 알고 싶어서 매일 매일 기다려야하는 시간을 기록했습니다. 100일 정도 대기 시간을 기록한 당신은 어떻게 맛집의 대기시간을 모델링 할 수 있을까요?
이런 경우 사용되는 것이 바로 bayesian inference 입니다.
먼저, 당신은 여러 자료를 조사해서 이 식당의 대기시간은 값에 의해 parameterized된 exponential distribution 을 따름을 알아냅니다. (실제로 대기시간은 주로 beta distribution 을 따릅니다.)
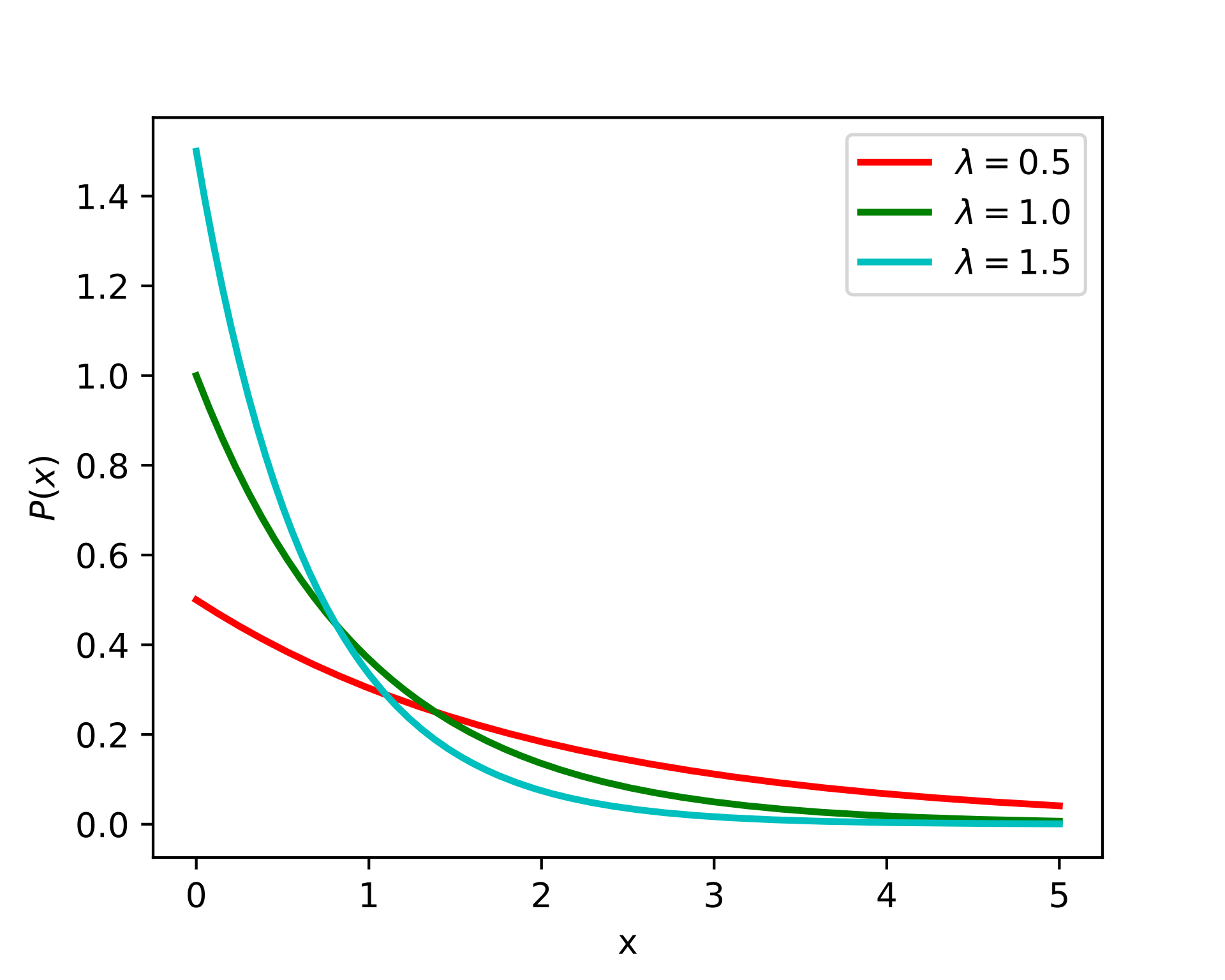
exponential distribution 의 parameter, 값은 exponential distirubtion 의 기댓값과 같습니다. 이 말은, 무수히 많이 식당을 방문해서 모든 대기시간들의 평균값을 구하면 거의 정확한 을 알 수 있다는 말입니다.
하지만 당신은 100번 밖에 방문을 안 했기 떄문에 대기시간의 평균을 정확한 값이라고 확신하기 어렵습니다. 100번의 방문 결과로 부터 우린 에 대해 어떤 정보를 알 수 있을까요?
우리는 이 지점에서 statistical inference, 그 중에서도 이 글에서는 bayesian inference 를 다룰 것입니다.
Bayesian Inference

위 자료에서, 는 관심있는 parameters 를 의미하며, 는 observation 결과를 의미합니다.
위 예시에서 가 이며, 100번의 방문을 통해 관찰한 대기시간이 값이 되겠네요.
Sampling Distribution
저희는 위 예시에서 값을 exponential distribution 으로 '모델링' 했습니다. 이 '모델링' 은 통계적 경험, 관찰 결과들의 분포로부터 우리가 상정한 distribution 입니다. 이 분포를 sampling distribution 이라고 합니다.
예를 들어, 누군가 식당의 대기줄이 줄어드는 과정을 수학적으로 나타내어보니 exponential distribution 을 따르더라! 라고 논문을 발표했다면 우리는 대부분 식당의 대기 시간 분포를 exponential distribution 으로 '모델링' 할 수 있습니다.
likelihood function
sampling distribution 은 observation 에 대한 distribution function 이지만, 같은 식 는 또한 parameter 에 대한 함수이기도 합니다. 가 에 대한 함수로써 지칭될 때는 likelihood function 이라고 명명합니다.
prior & posterior
위 식에서 아직 정의되지 않은 와 를 각각 prior 와 posterior 이라고 부릅니다.
이 부분은 다음 글에서 이어서 공유하겠습니다.
p.s. 사용된 이미지들은 공유를 위해 제가 만든 자료니 함부로 사용하지는 말아주세요.
