오늘은 posterior distribution 에 대해서 조금 더 집중해서 글을 쓰려고 합니다.
prior probability 와 posterior probability 의 사전적 정의는 다음과 같습니다.
- prior distribution : assumed probability distribution before some evidence is taken into account
- posterior distribution : conditional probability that results from updating the prior probability with information summarized by the likelihood via an application of Bayes' rule.
간단한 예시를 이전 포스팅에서 제시했었습니다. 조금 더, Machine learning 을 공부하시는 분들의 흥미를 끌만한 새로운 예시와 함께 다음 단계를 통해 bayesian approach 의 수학적 모델링을 이해해봅시다.
- 문제 정의
- 특정 상황에 대해 문제 해결하기
- 일반적인 상황에 대해 수학적인 모델링 만들기
1. 문제 정의
bayesian approach 는 어떤 상황을 매개하고 있는 매개 변수, 값을 추론하기 위해 사용합니다.
random noise 로부터 주어진 값에 따라 특정한 이미지 를 만들어내는 확률 모델 를 가정합시다. 우리는 멍멍이 이미지를 만들어내는 매개변수 의 값을 알아내고 싶습니다.
의 값은 1차원의 scalar 값일 수도, 고차원의 벡터 값일수도 있습니다. 중요한 건 멍멍이 이미지를 만들어내는 값은 알 수 없는 고정된(사전 정의된) 값이고, 우리는 가지고 있는 정보를 바탕으로 이 값, parameter of interest 를 알아내고싶습니다.
조금 더 문제를 확장해본다면, 자연현상을 변수에 의하여 매개되는 확률 함수의 형태로 모델링한다면 bayesian approach 는 자연 현상을 풀어내기 위한 한 가지 접근이 될 수 있습니다. 조금 더 복잡한 형태의 모델에 대해서는 뒤에서 더 다루겠습니다. 일단은, 다루고 있던 멍멍이 이미지를 조금 더 살펴봅시다.
2. 문제 해결하기
어떻게 하면 값을 알 수 있을까요?
일단 우리가 가지고 있는 정보를 살펴봅시다.
0. 확률 모델에 대한 근사를 모델링(modeling) 할 수 있습니다.
우리가 확률 모델 를 완벽하게 알 수 는 없지만, 이에 대한 근사 확률 모델 를 모델링할 수 있습니다.
예를 들어서 이전 문제에서 우리는, 맛집에서의 대기시간을 exponential 함수로 모델링했습니다.
최근의 연구로 이러한 확률 모델에 대한 함수를 multi layer perceptron 으로 근사할 수 있는 방법이 개발되었습니다. 엄청나게 많은 parameter 로 더욱 정확한 를 근사할 수 있게 되었습니다.
1. 값에 대한 최소한의 정보를 가지고 있습니다.
에 대한 정보가 정말 없다면 우리는 값이 에 분포하고 있다고 할 수 있습니다.
또는 충분한 normalizing 과 근사로 의 값이 에 균일하게 분포한다고도 생각할 수 있습니다. 가장 자연적인 normal distribution 에 따라 분포한다고도 생각할 수 있습니다.
2. 관찰을 할 수 있습니다.
우리는 로 부터 생성되는 그림을 관찰할 수 있습니다. 이 과정을 observe, 혹은 sampling 이라고 합니다.
그리고 이 관찰 결과와 가지고 있는 정보를 바탕으로 에 대한 간단한 추론이 가능합니다.
예를 들어서 생각해봅시다.
가 normal distribution 을 따른다는 정보가 있다고 했을 때 우리가 100번 관찰을 했는데 90번이나 되는 강아지 그림을 관찰했다면 값은 0에 가까운 값을 가지고 있다고 어느 정도 추론이 가능합니다! 다만, 1) 실제 의 값이 50인데 정말 운이 좋아서 90번이나 강아지 그림이 나왔을 수도 있고 또는 2) 함수가 거의 모든 경우에 대해서 강아지 그림을 그려내기 때문에 관찰 결과가 크게 의미가 없을 수 도있습니다.
... 그럼 대체 관찰 결과와 가지고 있는 정보로부터 값에 대해 얻을 수 있는 정보를 어떻게 디자인할 수 있을까요?
우리는 이 과정을 조금 더 엄격하고, 세련된 수학적 언어로 표현할 것입니다. 네, Bayesian approach 입니다.
3. 아마 이게 헷갈릴 것 같습니다.
값은 Fixed value 라고 했는데 확률 분포를 따르는 값이라니 이게 무슨 말인가요?
, 값은 확률 공간 에서 추출된 값입니다.
예를 드는게 더 이해가 편할 것 같습니다.
한 나라의 남성 평균 키에 대해서 조사한다고 생각해봅시다. 당연히, 모든 사람의 키를 다 조사하면 가장 정확하겠지만 불가능합니다. 그래서 통계학자들은 남성의 평균 키는 평균 음식 섭취량에 대한 함수라는 사실을 사용하기로 결정합니다. 그럼, 이 나라 남자들의 평균키는 이 나라 남자들의 평균 음식 섭취량을 알면 확인할 수 있습니다. 그런데 정확한 이 나라 남자들의 평균 음식 섭취량을 알 수 가 없습니다. 하지만 음식 섭취량은 생산되는 음식량을 인구수로 나눈 값을 평균으로 가지는 어떠한 함수가 될 것이며, 모든 가능한 값이 일어날 확률을 전부 더하면 1이 되겠죠. 네, 우리가 정확히 알 수 없는 확률 함수일 것입니다. 그리고 의 실제값은 저 알 수 없는 확률 분포에서 추출된 어떠한 값이 되겠네요.
그래서 학자들은, 이 나라에서 생산된 음식의 양을 인구수로 나눈 값을 평균으로 하는 gaussian distribution 을 가정하게 됩니다. 한 가지 질문이 더 생깁니다. 그럼 도 음식의 생산량에 종속된 값이며 이 값에 대한 bayesian approach 를 또 실행해야하는게 아닐까? 또 그럼 음식 생산량은 올해 날씨에 대한 함수가 될 수 있고, 올해 날씨는 또 작년 날씨에 대한 함수가 되고...
이 모델은 hierachical 모델이라는 뒤에서 설명할 형태로 모델링 가능하지만... 끝이 없죠, 언제나 어느정도의 합의와 근사가 필요합니다. 우리는 여기서 식량 생산량이 다른 변수에 종속되지 않는다고 가정했습니다.
또, 첨언하자면 어떤 변수의 평균값은 central limit theorem 에 따라 결국 정규 분포의 형태를 따르기 때문에, 평균값에 대한 prior 의 경우 normal distribution 으로 design 할 수 있다는 장점이 있습니다.
3. 수학적 모델링

이러한 상황에 대한 수학적 모델은 확률론을 처음 공부하면 접하게 되는 식에서부터 유도되는 bayesian rule 공식을 사용할 수 있습니다.
처음 이 식을 보면, 이렇게 당연한 식이 왜 중요하지? 라는 생각이 들지만 공부하면 할수록 참 심오하고 재미있습니다. 가장 최근의 machine learning 논문에서도 bayesian 을 심심찮게 볼 수 있습니다.
먼저, 는 우리가 가지고 있는 에 대한 최소한의 정보입니다. prior probability(사전 확률) 이라고 합니다.
그리고 는 우리가 모델링한 실제 확률 모델에 대한 근사 모델입니다. 와 같으며, sampling probability 라고 표현합니다. 우리가 가정한 모델일 때 observation 가 관측될 확률입니다. 에 대한 함수입니다. (아래에 예시가 있습니다.)
분모에 위치한 는 marginal likelihood, 입니다. 이 식은, normalizing constant 이며, 우리가 가정한 모델에서 관측결과가 나올 marginal probability입니다. 즉, 가능한 모든 에 대해 observation 이 관측될 확률을 전부 계산한 식입니다.
정말 중요한 marginal likelihood
marginal likelihood 는 단지 constant 일 뿐이지만 posterior 를 계산함에 있어서 정말 중요하고, 또 난해합니다. 가능한 모든 의 값이 이라면 그냥 계산하면 되지만... continuous, 그것도 normal distribution 처럼 정의역이 무한하다면 어떻게 될까요? 복잡한 적분을 계산해야하며, 그렇게해서 풀리면 다행입니다. 도저히 구할 수 없는 경우도 있을 것입니다.
앞으로 이어질 몇 개의 post 에서는 이 marginal likelihood 를 처리하는 방법만 주구장창 다루게 될 것입니다.
posterior probability
marginal likelihood 까지 성공적으로 계산할 수 있다면, 우리는 최종적으로 에 대한 추론을 확률로 표현할 수 있습니다.
이렇게 표현한, 관찰결과로부터 추론할 수 있는 의 확률 분포를 , posterior probability 라고 합니다.
! ML 모델을 공부하시는 분들, 간단한 머신 러닝 모델은 많은 이미지를 보고 모델의 parameter 를 학습시킵니다. 이러한 학습 과정에 대한 가장 기본적인 가정, 모델이 바로 이 bayesian 모델입니다. 가지고 있는 관찰 결과 로 부터, 근사 확률 모델 를 학습시켜나가는 과정이죠. 이 말을 왜 계속 하냐면, machine learning 이 처음 공부 할 때는 bayesian approach 보다 훨씬 어렵고, 복잡하며 세련되보이고 대체 왜 이 bayesian approach 가 강조되는지 이해하기 어렵기 떄문입니다.
! ML 모델을 공부하지 않으시는 분들은, 자연을 확률 모델로써 수학적 모델링하고 수많은 관찰결과로부터 자연을 이해해나가는 과정이라고 이해하시면 될 것 같습니다.
4. Example
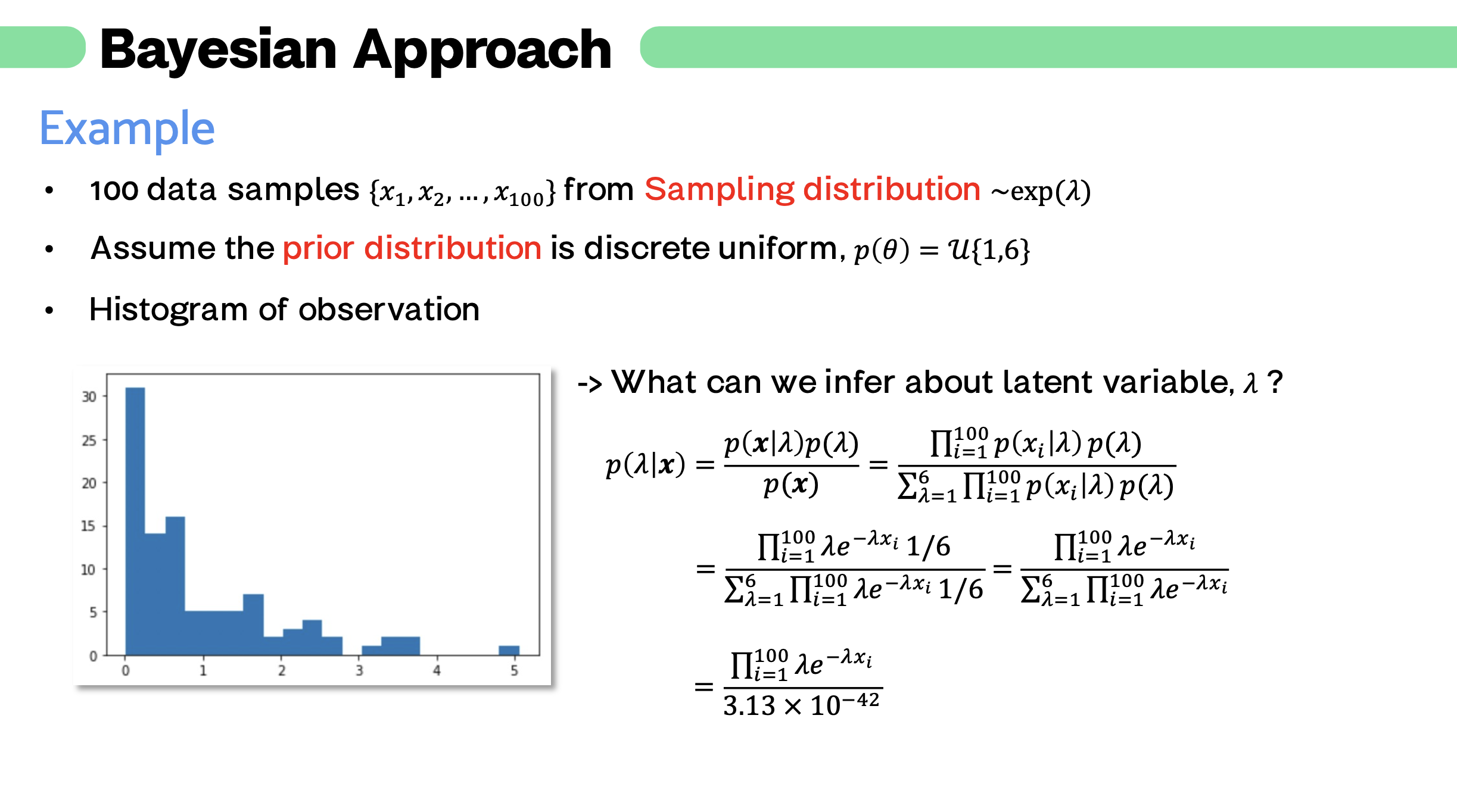

5. Posterior predictive distribution
우리가 좋은 모델을 근사하고, 적절한 에 대한 추론을 내렸다면 어떤 관측값이 나올지 어느정도의 예측도 가능합니다.
posterior predicitive distribution 은 위 bayesian approach 의 과정을 거친 후, 새로운 관측 결과에 대한 기댓값의 확률입니다.
참고로 는 의 확률 함수가 아닌 일반 함수로써의 표현입니다.
ML 모델로 따지자면, 새로운 input 에 대한 예측값과 비슷한 의미를 가지는 것 같네요. 그 외에, 이게 왜 중요한지 아직 느낌이 안 오겠지만, 앞으로 주구장창 이어질 marginal likelihood 를 풀고나면 posterior predicitive distribution 을 또 오랫동안 보게 됩니다.
6. Hierachical Model
이건 쓸까 말까 고민을 많이 했습니다. 필요하긴 한데, 위의 내용을 이해했다면 이해가 되면서 또 직접 풀다보면 어렵습니다.
그런데 재미있습니다. 이걸 풀려면.. 본격적으로 복잡한 bayesian model 을 풀기위한 다양한 sampling 기법이 등장하기도 하거든요.
이 부분은 작성한 ppt 를 그대로 첨부하는 것으로 남겨두겠습니다. 혹시 이 부분에 대한 요청이 많거나 뒤 쪽 포스트에서 추가 설명이 꼭 필요할 것 같으며 추가로 글을 작성하겠습니다.




설명 ) 아프리카에 있는 5개 학교 학생들의 한국어 숙련도를 어떻게 모델링 할 수 있을까요? 먼저 아프리카에 있는 초등학생들의 평균 한국어 실력을 매개변수로 사용하고, 그 후 각 학교 학생들의 한국어 시험 점수를 매개변수로 사용할 수 있겠네요. 이 두 단계의 매개변수로 적절한 bayesian model 을 모델링 할 수 있을 것 같습니다.
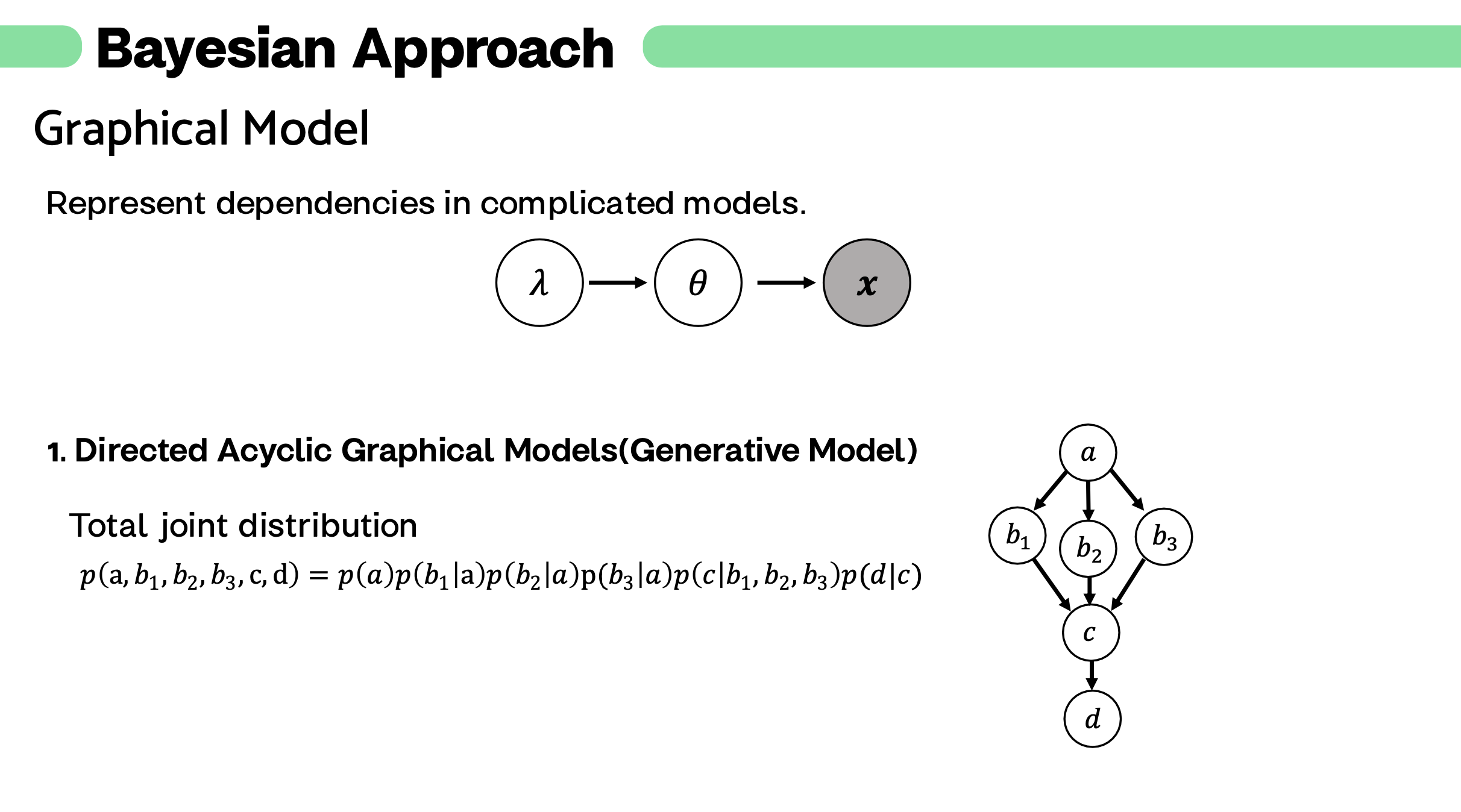
설명 ) 두 단계의 hierachical 모델도 자연에서는 아주 단순한 모델일 겁니다. 더욱 복잡한 현상, 더욱 복잡한 모델을 어떻게 한 눈에 이해할 수 있을까요? 그에 대한 solution 으로 제시된 것이 graphical model 입니다.
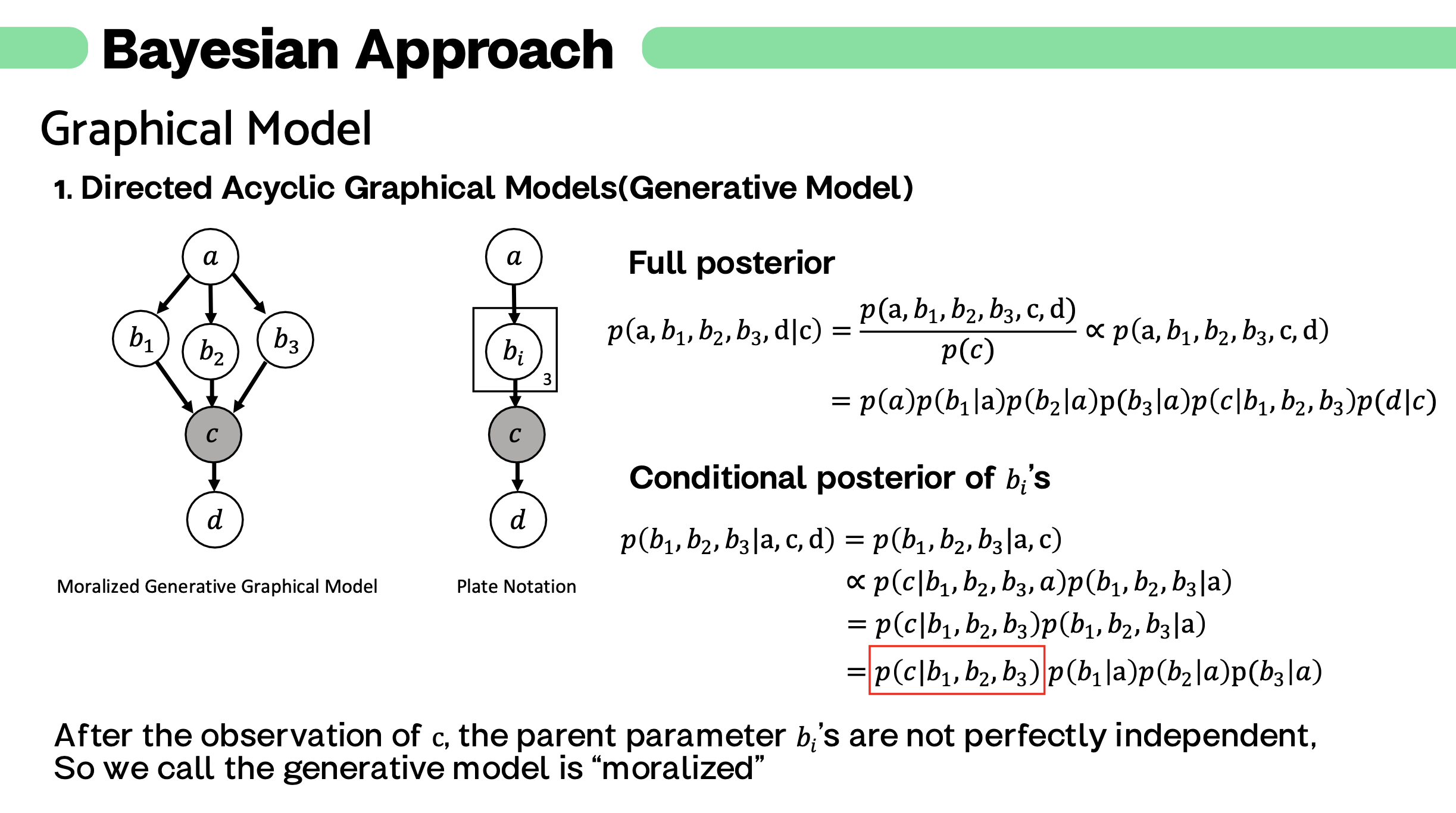
설명 ) graphical model 로 어렵고 복잡한 문제를 간단하게 표현할 수 있는 좋은 예시입니다.
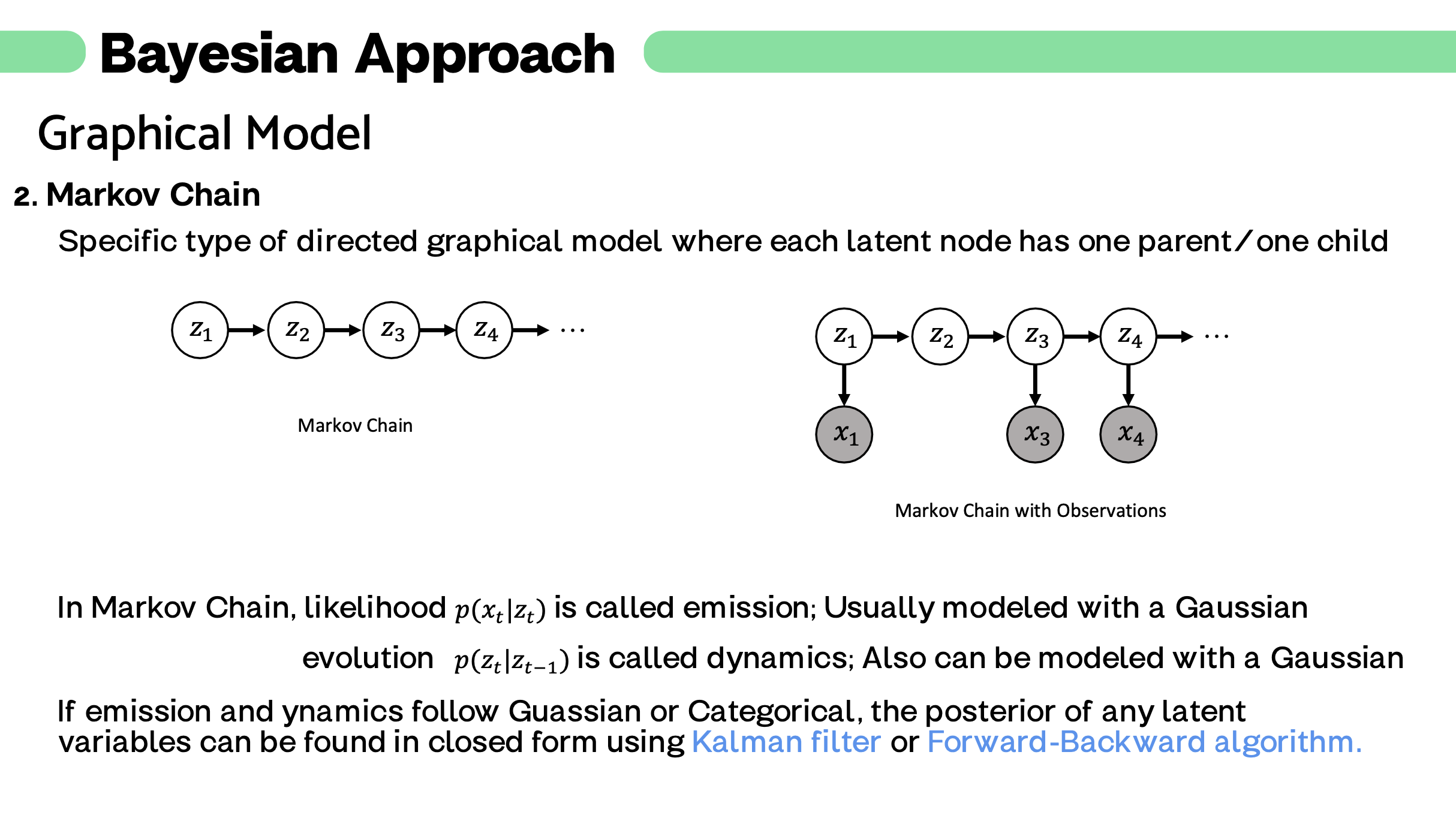
설명 ) 역시 하나의 예시입니다.
감사합니다.
모든 이미지는 제가 직접 만들었으니 이 포스트 외의 글로 퍼가지 말아주세요,
다음 글에서는 marginal likelihood 를 풀기위한 가장 유명한 방법 conjugate distribution 에 대해 알아보겠습니다.
