
오늘은 저번시간에 이어서 회귀(regression)에 대해 좀 더 자세히 다루어 보려고합니다.
input
from sklearn.datasets import make_regression
import pandas as pd
import statsmodels.api as sm
bias=100
X,y,w=make_regression(n_samples=200, n_features=1, bias=bias, noise=10, coef=True, random_state=1)
dfX=pd.DataFrame(X,columns=['X'])
dfy=pd.DataFrame(y,columns=['Y'])
df=pd.concat([dfX, dfy],axis=1) #x,y를 가로방향으로 연결
dfoutput
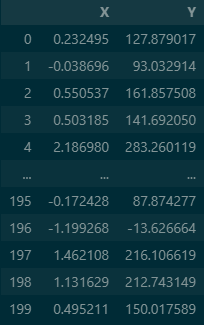
make_regression함수를 이용하여 가상의 데이터셋을 만들어 줍니다. 추가로 x,y절편으로 나눕니다.
from_formula 사용하기
input
# from_formula() 수식을 이용한 회귀분석 함수
# 종속변수 ~ 독립변수
model=sm.OLS.from_formula('Y ~ X', data=df)
result=model.fit() #학습
result.predict(dfX) # x를 입력하여 출력한 값output
0 120.009634
1 96.426481
2 147.667192
3 143.549322
4 289.975003
...
195 84.796857
196 -4.498893
197 226.938918
198 198.199938
199 142.855933
Length: 200, dtype: float64
분석값 출력1
input
print('TSS=',result.uncentered_tss) # y의 분산
print('ESS=',result.mse_model) # 예측값의 분산
print('RSS=',result.ssr) #잔차의 분산
print('R squared=',result.rsquared) # rvalue 결정계수 0.0~1.0output
TSS= 3651229.336876379
ESS= 1252601.224325924
RSS= 19403.46092458647
R squared= 0.984745763007339
여러가지 함수를 이용하여 원하는 내용만 출력할 수 있습니다.
분석값 출력2
input
result.summary()output
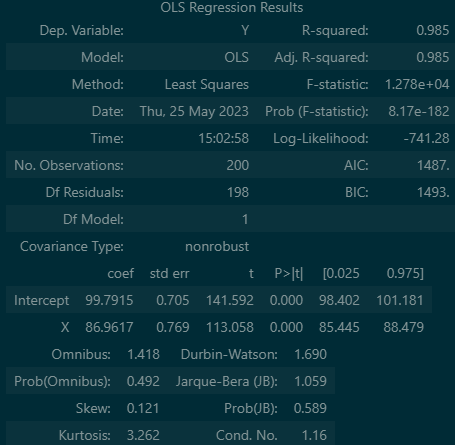
summary 함수를 사용하면 여러가지 데이터를 전체적으로 출력해 줍니다. 어제와 다르게 from_formula()를 이용하여 직접 x,y를 데이터프레임에 넣어 주었기 때문에 설명도 또한 올라간 것을 확인 할 수 있습니다.
오늘은 저번시간에 이어서 회귀분석을 좀 더 알아보았는데 데이터의 정확도, 설명도는 여러가지 방법으로 높일 수 있기 때문에 추가로 작성해 보았습니다.
😁 power through to the end 😁

AI (ML/DL) 학습